
What are Auto Scaling Groups and How Do They Work?
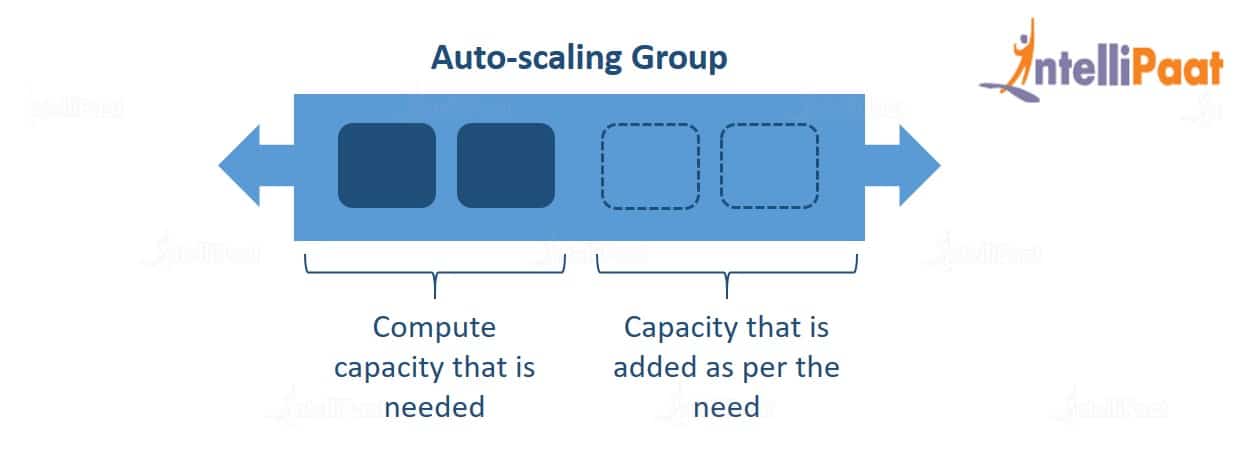
Auto scaling groups (ASGs) are a fundamental component of cloud computing that enables the automatic scaling of resources based on demand. They allow businesses to optimize their infrastructure costs while ensuring high availability and performance. An auto scaling group consists of a collection of identical instances, such as virtual machines or containers, that are managed and scaled together.
ASGs work by using launch configurations, which define the instance type, image, security groups, and other parameters required to launch new instances. When demand increases, the ASG launches new instances based on the launch configuration, and when demand decreases, the ASG terminates instances that are no longer needed. This process ensures that the infrastructure can handle the workload and provides a cost-effective solution for businesses.
Load balancers play a crucial role in ASGs by distributing incoming traffic evenly across the instances in the group. By doing so, load balancers ensure that no single instance is overwhelmed with traffic, improving the overall performance and reliability of the system.

Benefits of Using Auto Scaling Groups
Auto scaling groups offer numerous benefits for businesses looking to optimize their cloud infrastructure. By automatically scaling resources based on demand, ASGs provide cost savings, improved performance, and increased reliability.
One of the most significant advantages of using ASGs is cost savings. By scaling resources up and down based on demand, businesses can avoid overprovisioning and underutilizing resources, resulting in lower infrastructure costs. Additionally, ASGs can help businesses save on labor costs by automating the scaling process, freeing up time for IT teams to focus on other critical tasks.
ASGs also offer improved performance and increased reliability. By automatically scaling resources based on demand, ASGs ensure that the infrastructure can handle the workload, preventing slow performance and downtime. Furthermore, ASGs can help businesses improve their disaster recovery capabilities by automatically replacing failed instances, ensuring high availability and uptime.
Another advantage of using ASGs is the ability to handle unexpected traffic spikes. By automatically scaling resources based on demand, ASGs can handle sudden traffic spikes, ensuring that the infrastructure can handle the increased workload without downtime or slow performance. This feature is particularly useful for businesses with unpredictable traffic patterns, such as e-commerce websites or gaming platforms.

How to Set Up Auto Scaling Groups
Setting up auto scaling groups (ASGs) on popular cloud platforms like AWS, Azure, and Google Cloud is a straightforward process. Here is a step-by-step guide to help you get started:
AWS
- Sign in to the AWS Management Console and navigate to the EC2 service.
- Click on “Auto Scaling Groups” in the left-hand navigation menu and then click the “Create Auto Scaling group” button.
- Choose a name for your ASG and select a launch configuration or create a new one.
- Configure the network settings, including VPC, subnet, and security groups.
- Set the desired capacity, minimum, and maximum number of instances for your ASG.
- Configure scaling policies and alarms as needed.
- Review your settings and click “Create Auto Scaling group” to launch your instances.
Azure
- Sign in to the Azure Portal and navigate to the Virtual Machines service.
- Click on “Auto scaling groups” in the left-hand navigation menu and then click the “Add” button.
- Choose a name for your ASG and select a virtual machine scale set or create a new one.
- Configure the instance size, OS, and other settings as needed.
- Set the scaling rules and alerts for your ASG.
- Review your settings and click “Create” to launch your instances.
Google Cloud
- Sign in to the Google Cloud Console and navigate to the Compute Engine service.
- Click on “Auto scaling groups” in the left-hand navigation menu and then click the “Create” button.
- Choose a name for your ASG and select a instance group or create a new one.
- Configure the instance settings, including machine type, image, and network.
- Set the scaling rules and alerts for your ASG.
- Review your settings and click “Create” to launch your instances.
By following these steps, you can quickly and easily set up auto scaling groups on popular cloud platforms. Once your ASGs are up and running, be sure to monitor their performance and test your scaling policies to ensure optimal performance and cost savings.

Best Practices for Using Auto Scaling Groups
Auto scaling groups (ASGs) can provide significant benefits for businesses looking to optimize their cloud infrastructure. However, to get the most out of ASGs, it’s essential to follow best practices for using them. Here are some best practices to keep in mind:
Set Up Alarms
Setting up alarms is crucial for monitoring the performance of your ASGs. Use cloud platform-specific tools like AWS CloudWatch or Azure Monitor to set up alarms that trigger when certain conditions are met, such as when the CPU utilization exceeds a certain threshold or when the number of instances falls below a certain level.
Monitor Performance
Monitoring the performance of your ASGs is essential for ensuring optimal performance and cost savings. Use cloud platform-specific tools like AWS CloudWatch or Azure Monitor to monitor key performance metrics like CPU utilization, network traffic, and memory usage. Additionally, consider using third-party monitoring tools like Datadog or New Relic for more advanced monitoring capabilities.
Test Scaling Policies
Testing your scaling policies is crucial for ensuring that your ASGs can handle sudden traffic spikes or decreases. Use cloud platform-specific tools like AWS Auto Scaling or Azure Autoscale to test your scaling policies and ensure that they are configured correctly.
Use Launch Configurations
Using launch configurations is essential for ensuring that your instances are configured correctly. Use launch configurations to define the instance type, image, security groups, and other settings required to launch new instances. This ensures that your instances are configured consistently and correctly, reducing the risk of errors and downtime.
Use Load Balancers
Using load balancers is crucial for ensuring that your instances are evenly distributed and can handle the workload. Use load balancers to distribute incoming traffic evenly across the instances in your ASG, ensuring that no single instance is overwhelmed with traffic.
Clean Up Old Instances
Cleaning up old instances is essential for ensuring that you are not paying for resources that you no longer need. Use cloud platform-specific tools like AWS Auto Scaling or Azure Autoscale to terminate instances that are no longer needed, reducing costs and improving performance.
By following these best practices, you can ensure that your auto scaling groups are configured correctly, monitored effectively, and optimized for performance and cost savings.

Real-World Use Cases of Auto Scaling Groups
Auto scaling groups (ASGs) are used in a variety of real-world applications, from e-commerce websites to gaming platforms to data processing applications. Here are some examples of how ASGs are used in practice:
E-Commerce Websites
E-commerce websites often experience spikes in traffic during peak shopping seasons, such as Black Friday or Cyber Monday. To handle these spikes, e-commerce websites can use ASGs to automatically scale up or down based on demand. For example, an e-commerce website might use ASGs to add more instances during peak shopping hours and then scale down during off-peak hours to save on costs.
Gaming Platforms
Gaming platforms often experience unpredictable traffic patterns, with sudden spikes in traffic during new game releases or special events. To handle these spikes, gaming platforms can use ASGs to automatically scale up or down based on demand. For example, a gaming platform might use ASGs to add more instances during a new game release and then scale down once the initial rush has passed.
Data Processing Applications
Data processing applications often require significant computational resources to process large datasets. To handle these demands, data processing applications can use ASGs to automatically scale up or down based on the size of the dataset. For example, a data processing application might use ASGs to add more instances when processing a large dataset and then scale down once the processing is complete.
Content Delivery Networks
Content delivery networks (CDNs) often experience spikes in traffic based on the popularity of certain content. To handle these spikes, CDNs can use ASGs to automatically scale up or down based on demand. For example, a CDN might use ASGs to add more instances when a particular video goes viral and then scale down once the traffic subsides.
Machine Learning Applications
Machine learning applications often require significant computational resources to train models. To handle these demands, machine learning applications can use ASGs to automatically scale up or down based on the size of the dataset and the complexity of the model. For example, a machine learning application might use ASGs to add more instances when training a complex model on a large dataset and then scale down once the training is complete.
By using ASGs in these real-world applications, businesses can ensure that they have the necessary resources to handle traffic spikes and processing demands, while also optimizing costs and performance.
Choosing the Right Auto Scaling Group Strategy
When it comes to auto scaling groups, choosing the right strategy is crucial for ensuring optimal performance and cost savings. Here are some factors to consider when choosing an auto scaling group strategy:
Scaling Policies
Scaling policies define the conditions under which your auto scaling group should scale up or down. There are several types of scaling policies to choose from, including manual scaling, scheduled scaling, and dynamic scaling. Manual scaling allows you to manually adjust the number of instances in your auto scaling group, while scheduled scaling allows you to automatically adjust the number of instances based on a schedule. Dynamic scaling, on the other hand, allows you to automatically adjust the number of instances based on demand, such as CPU utilization or network traffic.
Scaling Metrics
Scaling metrics are the metrics that your auto scaling group uses to determine when to scale up or down. Common scaling metrics include CPU utilization, network traffic, and memory usage. When choosing scaling metrics, it’s important to consider the specific needs and goals of your application. For example, if your application is CPU-intensive, you might want to choose CPU utilization as your scaling metric. If your application is memory-intensive, you might want to choose memory usage as your scaling metric.
Cooldown Periods
Cooldown periods are the amount of time that your auto scaling group waits before scaling up or down again. Cooldown periods are important for preventing your auto scaling group from scaling too quickly or too slowly. When choosing cooldown periods, it’s important to consider the specific needs and goals of your application. For example, if your application has a lot of variability in demand, you might want to choose a longer cooldown period to prevent your auto scaling group from scaling too quickly.
Health Checks
Health checks are used to determine the health status of your instances. When choosing health checks, it’s important to consider the specific needs and goals of your application. For example, if your application requires high availability, you might want to choose aggressive health checks to quickly detect and replace unhealthy instances.
Alarms
Alarms are used to notify you when certain conditions are met, such as when the CPU utilization exceeds a certain threshold or when the number of instances falls below a certain level. When choosing alarms, it’s important to consider the specific needs and goals of your application. For example, if your application requires high availability, you might want to set up alarms to notify you when the number of instances falls below a certain level.
By considering these factors, you can choose the right auto scaling group strategy for your specific needs and goals. Additionally, it’s important to regularly monitor and adjust your auto scaling group strategy to ensure optimal performance and cost savings.
Potential Challenges and Limitations of Auto Scaling Groups
While auto scaling groups offer many benefits, there are also potential challenges and limitations to consider. Here are some of the most common issues:
Cold Starts
Cold starts occur when a new instance is launched and has to initialize and configure itself before it can start serving traffic. This process can take several minutes, during which time the instance is not able to handle requests. Cold starts can be a significant issue for applications that require low latency or high availability, as they can result in slow response times or even downtime.
Instance Termination
Instance termination can occur for a variety of reasons, such as when an instance becomes unhealthy or when the auto scaling group needs to scale down due to decreased demand. When an instance is terminated, any data stored on that instance is lost, which can be a significant issue for applications that require data persistence. To mitigate this issue, it’s important to use data storage solutions that are independent of individual instances, such as Amazon S3 or Google Cloud Storage.
Cost Overruns
Auto scaling groups can help businesses save on costs by automatically scaling up or down based on demand. However, if not properly managed, auto scaling groups can also result in cost overruns. For example, if an auto scaling group is configured to scale up too aggressively, it can result in the launch of unnecessary instances, which can increase costs. To avoid cost overruns, it’s important to regularly monitor and adjust your auto scaling group strategy, and to use cost optimization tools provided by your cloud platform.
Complexity
Auto scaling groups can be complex to set up and manage, especially for businesses that are new to cloud computing. To mitigate this issue, it’s important to invest time in learning about auto scaling groups and how they work, and to use tools and services provided by your cloud platform to simplify the setup and management process.
By understanding these potential challenges and limitations, businesses can take steps to mitigate them and ensure that their auto scaling groups are properly configured and managed for optimal performance and cost savings.

Future Trends in Auto Scaling Groups
Auto scaling groups have been a key component of cloud computing for several years, and they continue to evolve and improve. Here are some future trends to watch in auto scaling groups:
Serverless Computing
Serverless computing is a cloud computing model in which the cloud provider manages the infrastructure and dynamically allocates resources as needed. Serverless computing is well-suited for applications that have variable or unpredictable workloads, as it allows businesses to pay only for the resources they use. Auto scaling groups can be used in conjunction with serverless computing to automatically scale the number of serverless functions based on demand.
Container Orchestration
Container orchestration is a method of managing and scaling containers, which are lightweight, portable, and self-contained units of software. Container orchestration tools like Kubernetes and Docker Swarm can be used to manage and scale containers across multiple hosts, making it easier to deploy and manage containerized applications. Auto scaling groups can be used in conjunction with container orchestration tools to automatically scale the number of containers based on demand.
Machine Learning-Based Scaling
Machine learning-based scaling is a method of automatically scaling resources based on historical data and predictive analytics. By analyzing past usage patterns and predicting future demand, machine learning-based scaling can help businesses optimize their resource utilization and reduce costs. Auto scaling groups can be integrated with machine learning-based scaling tools to automatically adjust the number of instances based on predicted demand.
Hybrid Cloud Scaling
Hybrid cloud scaling is a method of scaling applications across both public and private clouds. By using a combination of on-premises and cloud-based resources, businesses can achieve greater flexibility and scalability while maintaining control over their data and infrastructure. Auto scaling groups can be used in conjunction with hybrid cloud tools to automatically scale resources across both public and private clouds based on demand.
By staying up-to-date on these future trends in auto scaling groups, businesses can ensure that they are taking full advantage of the latest technologies and best practices for cloud computing.
