
What are Databricks and Their Role in Data Processing?
Databricks is a unified analytics platform designed to simplify data processing and analysis for various applications, including data engineering, data science, and machine learning. The platform brings together multiple tools and services, enabling data teams to collaborate, build, and deploy data-driven solutions more efficiently.
At its core, Databricks is built on Apache Spark, an open-source, distributed computing engine for large-scale data processing. By leveraging Spark’s power, Databricks offers a robust and scalable solution for handling big data workloads, making it an ideal choice for organizations dealing with vast amounts of data.
One of the key benefits of Databricks is its collaborative workspace, which allows data professionals to work together on projects in real-time. This feature promotes knowledge sharing, reduces redundancy, and fosters a culture of innovation within data teams.
Moreover, Databricks’ lakehouse architecture combines the best elements of data lakes and data warehouses, providing a single, flexible environment for data storage, processing, and analysis. This approach simplifies data management and ensures seamless data flow between different stages of the data pipeline.
Another notable feature of Databricks is its auto-scaling capabilities, which automatically adjust cluster sizes based on workload demands. This feature ensures optimal resource utilization, reducing costs and improving performance for data-intensive tasks.
In summary, Databricks is a comprehensive analytics platform that streamlines data processing and analysis for various data-driven applications. Its unique features, such as the collaborative workspace, lakehouse architecture, and auto-scaling capabilities, make it an attractive choice for organizations looking to enhance their data capabilities and drive business value through data-driven insights.

A Brief History and Evolution of Databricks
Databricks was founded in 2013 by the original creators of Apache Spark at the University of California, Berkeley’s AMPLab. The company aimed to provide a unified analytics platform that simplified data processing and analysis for various applications, including data engineering, data science, and machine learning.
From its inception, Databricks has been closely associated with Apache Spark, an open-source, distributed computing engine for large-scale data processing. By building on Spark’s foundation, Databricks has been able to offer a robust and scalable solution for handling big data workloads, making it an ideal choice for organizations dealing with vast amounts of data.
Over the years, Databricks has evolved to meet the growing demands of big data and AI. The platform has expanded its capabilities to include support for machine learning, deep learning, and artificial intelligence, enabling organizations to build and deploy intelligent data-driven solutions more efficiently.
In addition, Databricks has introduced several innovative features to enhance its platform, such as the collaborative workspace, lakehouse architecture, and auto-scaling capabilities. These features have helped Databricks maintain its competitive edge in the rapidly evolving data processing landscape.
Today, Databricks is a leading unified analytics platform, trusted by thousands of organizations worldwide to process and analyze their data. Its commitment to innovation and excellence has made it an essential tool for data professionals seeking to unlock the full potential of their data.

Key Features and Benefits of Databricks
Databricks offers a wide range of unique features and benefits that cater to the needs of data teams and organizations. Here are some of the key features that make Databricks a popular choice for data processing and analysis:
Collaborative Workspace
Databricks provides a collaborative workspace that allows data professionals to work together on projects in real-time. This feature promotes knowledge sharing, reduces redundancy, and fosters a culture of innovation within data teams. Users can easily create, edit, and share notebooks, facilitating seamless collaboration and efficient project management.
Lakehouse Architecture
Databricks’ lakehouse architecture combines the best elements of data lakes and data warehouses, providing a single, flexible environment for data storage, processing, and analysis. This approach simplifies data management and ensures seamless data flow between different stages of the data pipeline. Additionally, Databricks supports various data formats, including structured, semi-structured, and unstructured data, making it a versatile solution for diverse data processing needs.
Auto-Scaling Capabilities
Databricks’ auto-scaling capabilities automatically adjust cluster sizes based on workload demands. This feature ensures optimal resource utilization, reducing costs and improving performance for data-intensive tasks. Users can also customize their auto-scaling policies to meet their specific requirements, providing greater flexibility and control over their data processing resources.
Integration with Apache Spark
As a platform built on Apache Spark, Databricks offers seamless integration with Spark’s extensive ecosystem of tools and libraries. Users can leverage Spark’s power for large-scale data processing, machine learning, and graph processing, all within the Databricks environment. This integration provides a unified and cohesive experience for data professionals, reducing the need for complex setup and configuration processes.
Security and Compliance
Databricks prioritizes security and compliance, offering features such as data encryption, access controls, and audit logs. These features help organizations meet various regulatory requirements and ensure the secure handling of sensitive data. Additionally, Databricks supports single sign-on (SSO) and multi-factor authentication (MFA), providing an extra layer of security for user accounts and data resources.
Performance and Scalability
Databricks is designed to handle large-scale data processing workloads with ease. The platform offers high performance and scalability, ensuring that data teams can efficiently process and analyze vast amounts of data. With support for distributed computing, Databricks enables users to parallelize their data processing tasks, significantly reducing processing times and improving overall efficiency.
In summary, Databricks’ unique features and benefits make it an attractive choice for organizations looking to streamline their data processing and analysis efforts. Its collaborative workspace, lakehouse architecture, auto-scaling capabilities, and seamless integration with Apache Spark are just a few of the reasons why Databricks has become a leading unified analytics platform for data engineering, data science, and machine learning.

How to Use Databricks: A ‘Hands-On’ Guide
To help you get started with Databricks, this section provides a step-by-step guide on setting up a Databricks workspace, creating clusters, and running notebooks. With these instructions, you’ll be able to experience the power of Databricks first-hand and explore its unique features and capabilities.
Step 1: Sign Up for a Databricks Account
To start using Databricks, sign up for a free trial account on the official Databricks website. After signing up, log in to your new account and familiarize yourself with the user interface.
Step 2: Create a New Workspace
Once logged in, create a new workspace by clicking on the “Create Workspace” button. Provide the necessary details, such as the workspace name, cloud provider, and region. After creating the workspace, you’ll be redirected to the workspace dashboard.
Step 3: Set Up a New Cluster
To start processing data, create a new cluster by clicking on the “Create Cluster” button. Choose the appropriate runtime based on your requirements, such as Spark, PySpark, or Delta Engine. Configure the cluster settings, including the number of workers and driver type, and then start the cluster.
Step 4: Create a Notebook
After setting up the cluster, create a new notebook by clicking on the “Create” button and selecting “Notebook.” Choose the language for your notebook, such as Python, Scala, or SQL, and attach it to the cluster you created earlier. Now you’re ready to start writing and running code in your new notebook.
Step 5: Run a Simple Query
To test your setup, run a simple query in your notebook. For example, you can use the following Python code to print “Hello, Databricks!” in the output cell:
print("Hello, Databricks!") Step 6: Explore Databricks’ Unique Features
Now that you have a basic understanding of how to use Databricks, take some time to explore its unique features, such as the collaborative workspace, lakehouse architecture, and auto-scaling capabilities. Experiment with different use cases and data processing tasks to get a feel for the platform’s capabilities and potential benefits for your organization.
By following these steps, you’ll be well on your way to mastering Databricks and unlocking its full potential for data engineering, data science, and machine learning projects. Happy data processing!
Use Cases and Success Stories of Databricks
Databricks has been successfully implemented by numerous companies and organizations across various industries to streamline data processing, improve data-driven decision-making, and foster innovation. Here are some real-life examples of Databricks in action:
Case Study 1: Data Science at Scale for a Leading Financial Institution
A major financial institution used Databricks to centralize its data science efforts, enabling its data scientists to collaborate more effectively and process large datasets efficiently. By adopting Databricks, the institution was able to reduce its data processing time from days to hours, significantly improving its ability to make data-driven decisions and respond to market changes quickly.
Case Study 2: Real-Time Fraud Detection for a Global E-commerce Company
A global e-commerce company leveraged Databricks to develop a real-time fraud detection system that analyzed user behavior and transaction patterns. By using Databricks’ collaborative workspace and lakehouse architecture, the company was able to build and deploy its fraud detection model quickly, reducing fraudulent transactions by 50% and improving overall customer trust and satisfaction.
Case Study 3: Machine Learning for Predictive Maintenance in Manufacturing
A leading manufacturing company used Databricks to implement a predictive maintenance system that analyzed sensor data from industrial machines. By using Databricks’ machine learning capabilities, the company was able to predict equipment failures before they occurred, reducing downtime and maintenance costs by 30%.
Case Study 4: Data Engineering for a Large-Scale Media Company
A large-scale media company used Databricks to simplify its data engineering efforts, enabling its data engineers to process and analyze large volumes of data from various sources. By adopting Databricks, the company was able to reduce its data processing time from weeks to days, improving its ability to deliver personalized content and recommendations to its users.
These success stories demonstrate the versatility and power of Databricks in addressing various data processing and analysis challenges. By providing a unified analytics platform for data engineering, data science, and machine learning, Databricks enables organizations to streamline their data processing efforts, foster collaboration, and make data-driven decisions more effectively.

Comparing Databricks to Alternative Data Processing Platforms
When considering a data processing platform, it’s essential to evaluate various options to ensure you choose the one that best fits your organization’s needs. In this section, we’ll compare Databricks to other popular data processing platforms, such as AWS Glue, Google Cloud Dataproc, and Microsoft Azure Databricks, to help you make an informed decision.
AWS Glue
AWS Glue is a fully managed ETL service that makes it easy to move data between data stores. While AWS Glue offers serverless ETL capabilities, it lacks the comprehensive features and flexibility of Databricks. Databricks, on the other hand, provides a unified analytics platform for data engineering, data science, and machine learning, making it a more versatile solution for complex data processing tasks.
Google Cloud Dataproc
Google Cloud Dataproc is a fully managed, open-source Spark and Hadoop service that allows you to run and manage clusters at scale. While Google Cloud Dataproc offers a cost-effective solution for running Spark and Hadoop workloads, it lacks the collaborative workspace and lakehouse architecture found in Databricks. These features enable Databricks to provide a more seamless and efficient data processing experience for data teams.
Microsoft Azure Databricks
Microsoft Azure Databricks is a fast, easy, and collaborative Apache Spark-based analytics platform. While Azure Databricks offers similar features to Databricks, it is limited to the Microsoft Azure ecosystem. If your organization is not using Azure or prefers a more versatile solution, Databricks might be a better fit for your data processing needs.
When choosing a data processing platform, consider the unique features and benefits of each option. While AWS Glue, Google Cloud Dataproc, and Microsoft Azure Databricks offer compelling solutions, Databricks stands out as a unified analytics platform for data engineering, data science, and machine learning. By providing a collaborative workspace, lakehouse architecture, and auto-scaling capabilities, Databricks simplifies data processing and analysis, making it an excellent choice for data teams and organizations.
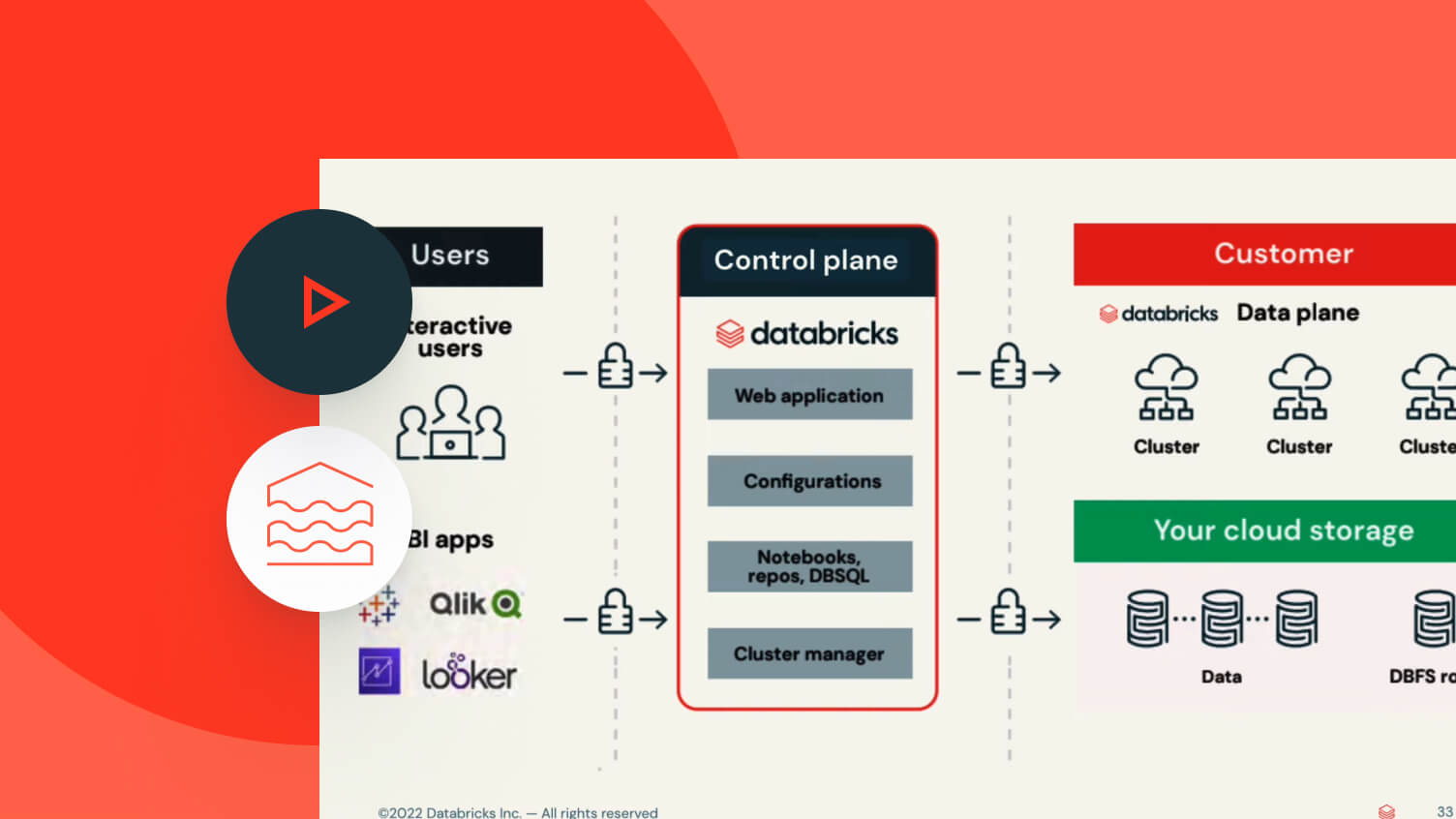
Databricks Pricing and Scalability: What You Need to Know
Understanding a platform’s pricing structure and scalability is crucial when selecting a data processing solution. In this section, we’ll discuss Databricks’ pricing and how it scales with usage, as well as provide tips on optimizing costs and ensuring efficient resource allocation.
Pricing Structure
Databricks uses a consumption-based pricing model, which means you pay for the resources you use. The pricing structure consists of two main components: DBUs (Databricks Units) and additional services. DBUs are a measure of consumption that combines the amount of data processed, the number of hours of cluster usage, and the instance type. Additional services, such as data storage and networking, are billed separately.
Scalability
Databricks is designed to scale with your data processing needs. As your data grows, you can easily add more nodes to your clusters, allowing you to process larger datasets and run more complex workloads. Additionally, Databricks’ auto-scaling capabilities automatically adjust the number of nodes in your cluster based on the workload, ensuring optimal performance and cost efficiency.
Optimizing Costs
To optimize costs when using Databricks, consider the following best practices:
- Terminate clusters when not in use to avoid unnecessary charges.
- Use smaller instance types for development and testing environments.
- Leverage Databricks’ workspace sharing feature to collaborate with team members and reduce redundant resources.
- Monitor your DBU usage and adjust your workloads accordingly to stay within your budget.
Efficient Resource Allocation
To ensure efficient resource allocation, consider the following recommendations:
- Create separate clusters for development, testing, and production environments to avoid performance bottlenecks.
- Use Databricks’ job scheduling feature to automate and manage your workloads effectively.
- Monitor your cluster performance and adjust the number of nodes based on workload demands.
- Leverage Databricks’ query optimization features, such as caching and indexing, to improve query performance and reduce processing times.
By understanding Databricks’ pricing structure and scalability, you can make informed decisions about implementing Databricks in your organization. With its consumption-based pricing model and ability to scale with your data processing needs, Databricks offers a flexible and cost-effective solution for data engineering, data science, and machine learning.

The Future of Databricks: Trends and Predictions
As data processing and AI continue to evolve, understanding how platforms like Databricks are positioned to address emerging challenges and opportunities is crucial. In this section, we’ll analyze the latest trends in data processing and AI and discuss how Databricks is poised to help organizations navigate these changes.
Trend 1: Real-Time Data Processing
Real-time data processing is becoming increasingly important as organizations seek to make instantaneous decisions based on up-to-the-minute data. Databricks’ support for real-time data processing through tools like Structured Streaming and its lakehouse architecture enables organizations to harness the power of real-time data, providing a competitive edge in today’s fast-paced business environment.
Trend 2: Data Mesh and Decentralized Data Architectures
Data mesh and decentralized data architectures are gaining traction as organizations aim to break down data silos and democratize data access. Databricks’ collaborative workspace and lakehouse architecture support these trends by providing a unified platform for data engineering, data science, and machine learning, enabling teams to work together more effectively and share insights across the organization.
Trend 3: AI and Machine Learning
AI and machine learning continue to be at the forefront of data-driven innovation. Databricks’ support for popular machine learning libraries and frameworks, such as TensorFlow, Scikit-learn, and PyTorch, allows data scientists and engineers to build, train, and deploy machine learning models more efficiently, driving innovation and growth for organizations.
Trend 4: Data Governance and Security
Data governance and security are critical components of any modern data processing platform. Databricks’ robust data governance and security features, such as data lineage, access controls, and encryption, ensure that organizations can securely manage and process their data while adhering to regulatory requirements.
Predictions for Databricks
Based on these trends, we predict that Databricks will continue to be a leading player in the data processing and AI space. Its focus on real-time data processing, data mesh and decentralized data architectures, AI and machine learning, and data governance and security positions it well to address the evolving needs of organizations in the coming years.
By staying abreast of the latest trends and predictions in data processing and AI, you can ensure that your organization is well-equipped to make informed decisions about implementing platforms like Databricks. With its innovative features and strong position in the market, Databricks is poised to help organizations navigate the challenges and opportunities of the data-driven future.