
Understanding Cloud Architectures: An Overview
Cloud architectures have become increasingly popular in recent years due to their flexibility, scalability, and cost-effectiveness. At their core, cloud architectures consist of various components, including servers, storage systems, networking, and applications, all working together to deliver computing resources and services over the internet. These systems offer numerous benefits, such as reduced capital and operational expenses, increased collaboration and productivity, and enhanced security and disaster recovery capabilities.
Efficient storage and retrieval processes are crucial to the overall performance and success of cloud architectures. As data volumes continue to grow, organizations need to ensure that their cloud systems can handle the increasing demands of storing, accessing, and managing large amounts of data. In this comprehensive guide, we will explore the key considerations, storage solutions, strategies, and best practices for optimizing storage and retrieval in cloud architectures.

Key Considerations for Storage and Retrieval in Cloud Architectures
When designing and implementing storage and retrieval systems in cloud architectures, several factors must be taken into account to ensure optimal performance, availability, and security. These factors include scalability, availability, performance, and security.
Scalability
Scalability is the ability of a system to handle increasing workloads and data volumes without compromising performance or availability. In cloud architectures, scalability can be achieved through horizontal scaling (adding more resources, such as servers or storage devices) or vertical scaling (upgrading existing resources with more powerful hardware or software components). Scalability is crucial for organizations that expect their data volumes and user base to grow over time.
Availability
Availability refers to the percentage of time that a system is accessible and operational. High availability is essential for mission-critical applications and services that require minimal downtime. Cloud architectures can provide high availability through redundancy, fault tolerance, and disaster recovery mechanisms, such as multiple data replicas, automatic failover, and geographically distributed data centers.
Performance
Performance refers to the speed and responsiveness of a system in processing and delivering data to users. Factors that affect performance include network latency, storage access time, and processing power. To optimize performance in cloud architectures, organizations can use techniques such as caching, indexing, and prefetching, which we will discuss in more detail in a later section.
Security
Security is a critical concern for cloud architectures, as they involve storing and processing sensitive data over the internet. To ensure data privacy and integrity, cloud providers offer various security features, such as encryption, access control, and activity monitoring. However, organizations must also implement their own security policies and procedures, such as strong passwords, multi-factor authentication, and regular security audits.
By considering these factors, organizations can design and implement storage and retrieval systems in cloud architectures that are efficient, reliable, and secure. In the following sections, we will explore various storage solutions and strategies for optimizing data retrieval in cloud architectures.
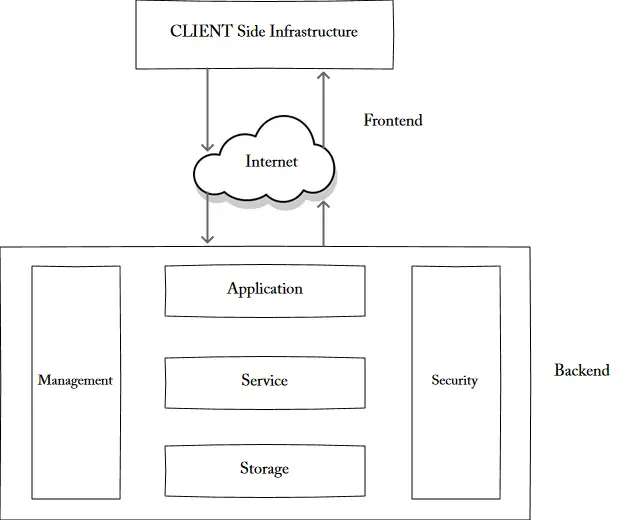
Types of Storage Solutions in Cloud Architectures
Cloud architectures offer various storage solutions, each with its advantages and disadvantages. The three main types of storage solutions are object storage, block storage, and file storage. Understanding the differences between these storage solutions is crucial for optimizing storage and retrieval processes in cloud architectures.
Object Storage
Object storage is a scalable and cost-effective storage solution that stores data as objects within a flat address space. Each object includes the data itself, metadata, and a unique identifier. Object storage is ideal for storing unstructured data, such as images, videos, and documents, that do not require frequent updates or modifications. Object storage also provides high durability and availability through data replication and redundancy mechanisms.
Block Storage
Block storage is a storage solution that divides data into blocks and stores them as separate units on disk arrays. Each block is assigned a unique identifier and can be accessed and modified independently. Block storage is ideal for storing structured data, such as databases and file systems, that require frequent updates and modifications. Block storage also provides high performance and low latency through direct access to the storage devices.
File Storage
File storage is a storage solution that organizes data into a hierarchical file system, with directories and subdirectories. Each file includes metadata, such as creation date, modification date, and access permissions. File storage is ideal for storing shared files and documents that require access control and collaboration features. File storage also provides compatibility with various operating systems and applications that support standard file system protocols.
Choosing the appropriate storage solution depends on the specific requirements of the application or service. Object storage is suitable for storing large volumes of unstructured data, while block storage is ideal for storing structured data that requires frequent updates and modifications. File storage is appropriate for storing shared files and documents that require access control and collaboration features. By selecting the appropriate storage solution, organizations can optimize storage and retrieval processes in cloud architectures and improve overall system performance and efficiency.
Strategies for Effective Data Retrieval in Cloud Architectures
Efficient data retrieval is crucial for optimizing cloud architectures’ performance and reducing latency. Various strategies can be employed to improve data retrieval, including caching, indexing, and prefetching. These techniques can significantly enhance system performance and user experience.
Caching
Caching is a technique that stores frequently accessed data in a cache, a high-speed memory storage layer. By storing frequently accessed data in a cache, cloud architectures can reduce the number of requests to the underlying storage system, thereby improving system performance and reducing latency. Caching can be implemented at various levels, including the application, database, and network levels.
Indexing
Indexing is a technique that organizes data in a way that enables faster retrieval. By creating indexes on frequently queried columns, cloud architectures can significantly reduce the time it takes to retrieve data. Indexing can be implemented at various levels, including the database and file system levels.
Prefetching
Prefetching is a technique that anticipates user requests and retrieves data before it is actually needed. By prefetching data, cloud architectures can reduce the time it takes to retrieve data and improve system performance. Prefetching can be implemented at various levels, including the application and database levels.
Choosing the appropriate data retrieval strategy depends on the specific requirements of the application or service. Caching is suitable for storing frequently accessed data, while indexing is ideal for organizing data in a way that enables faster retrieval. Prefetching is appropriate for anticipating user requests and retrieving data before it is actually needed. By selecting the appropriate data retrieval strategy, organizations can optimize storage and retrieval processes in cloud architectures and improve overall system performance and efficiency.
Implementing Storage and Retrieval Solutions in Popular Cloud Platforms
Cloud platforms offer various storage and retrieval solutions that cater to different use cases and requirements. Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP) are three popular cloud platforms that provide a range of storage and retrieval services. Understanding the unique features and capabilities of each platform can help organizations optimize storage and retrieval processes in cloud architectures.
Amazon Web Services (AWS)
AWS offers a range of storage and retrieval services, including Amazon Simple Storage Service (S3), Amazon Elastic Block Store (EBS), and Amazon Elastic File System (EFS). S3 is an object storage service that provides scalable and durable storage for data backup, archival, and analytics. EBS is a block storage service that provides persistent storage for Amazon Elastic Compute Cloud (EC2) instances, while EFS is a fully managed file system that provides scalable and shared file storage for EC2 instances.
Microsoft Azure
Microsoft Azure offers a range of storage and retrieval services, including Azure Blob Storage, Azure Disk Storage, and Azure Files. Azure Blob Storage is an object storage service that provides scalable and durable storage for unstructured data, such as text and binary data. Azure Disk Storage is a block storage service that provides persistent storage for Azure Virtual Machines, while Azure Files is a fully managed file share service that provides scalable and shared file storage for Azure Virtual Machines.
Google Cloud Platform (GCP)
GCP offers a range of storage and retrieval services, including Google Cloud Storage, Google Persistent Disks, and Google Cloud Filestore. Google Cloud Storage is an object storage service that provides scalable and durable storage for data backup, archival, and analytics. Google Persistent Disks are block storage devices that provide persistent storage for Google Compute Engine instances, while Google Cloud Filestore is a fully managed file share service that provides scalable and shared file storage for Google Compute Engine instances.
Choosing the appropriate storage and retrieval solution depends on the specific requirements of the application or service. AWS, Azure, and GCP offer a range of storage and retrieval services that cater to different use cases and requirements. By selecting the appropriate storage and retrieval solution, organizations can optimize storage and retrieval processes in cloud architectures and improve overall system performance and efficiency.
Best Practices for Designing Storage and Retrieval Systems in Cloud Architectures
Designing efficient and effective storage and retrieval systems in cloud architectures is crucial for optimizing system performance and reducing costs. Best practices for designing these systems include data partitioning, replication, and backup strategies. These practices can help ensure data availability, durability, and scalability while minimizing latency and improving overall system efficiency.
Data Partitioning
Data partitioning, also known as sharding, involves dividing data into smaller, more manageable parts and distributing them across multiple storage devices or nodes. This approach can help improve data access times, reduce latency, and increase system throughput. Data partitioning can be implemented in various ways, including horizontal partitioning, vertical partitioning, and hybrid partitioning. The choice of partitioning strategy depends on the specific requirements of the application or service.
Replication
Data replication involves creating multiple copies of data and distributing them across different storage devices or nodes. This approach can help ensure data availability and durability in case of hardware failures or network outages. Replication can be implemented in various ways, including synchronous replication, asynchronous replication, and hybrid replication. The choice of replication strategy depends on the specific requirements of the application or service.
Backup Strategies
Backup strategies involve creating copies of data and storing them in a separate location or medium. This approach can help ensure data availability and recoverability in case of data loss or corruption. Backup strategies can be implemented in various ways, including full backups, incremental backups, and differential backups. The choice of backup strategy depends on the specific requirements of the application or service.
Monitoring and optimizing storage and retrieval systems in cloud architectures is also essential for ensuring system performance and cost efficiency. This can be achieved through various techniques, such as monitoring system metrics, analyzing system logs, and implementing performance optimization strategies. By following best practices for designing storage and retrieval systems in cloud architectures, organizations can optimize system performance, reduce costs, and ensure data availability, durability, and recoverability.
Emerging Trends and Innovations in Cloud Storage and Retrieval Technologies
Cloud storage and retrieval technologies have evolved significantly in recent years, with new trends and innovations emerging to improve storage and retrieval processes and reduce costs. Some of these trends and innovations include serverless computing, edge computing, and artificial intelligence (AI).
Serverless Computing
Serverless computing is an emerging trend in cloud computing that enables developers to build and run applications without having to manage servers or infrastructure. Serverless computing can help simplify the development and deployment of cloud-based applications, reduce costs, and improve scalability and availability. In the context of storage and retrieval in cloud architectures, serverless computing can help optimize data storage and retrieval processes by automatically scaling resources up or down based on demand.
Edge Computing
Edge computing is another emerging trend in cloud computing that involves processing data closer to the source or the edge of the network. Edge computing can help reduce latency, improve performance, and reduce bandwidth costs. In the context of storage and retrieval in cloud architectures, edge computing can help optimize data storage and retrieval processes by storing data locally on edge devices and reducing the need for frequent communication with centralized cloud servers.
Artificial Intelligence (AI)
Artificial intelligence (AI) is a rapidly evolving technology that has the potential to transform cloud storage and retrieval processes. AI can help automate data management tasks, optimize data storage and retrieval processes, and improve data security and privacy. For example, AI-powered data analytics tools can help identify patterns and insights in large datasets, while AI-powered data compression algorithms can help reduce storage costs. AI-powered data encryption and decryption tools can help improve data security and privacy, while AI-powered anomaly detection tools can help detect and prevent data breaches and cyber attacks.
By leveraging these emerging trends and innovations, organizations can optimize their cloud storage and retrieval processes, reduce costs, and improve system performance and efficiency. However, it is essential to address the challenges and limitations of these technologies, such as data privacy, security, and compliance issues, through best practices and emerging solutions.

Challenges and Limitations of Cloud Storage and Retrieval Technologies
Cloud storage and retrieval technologies have revolutionized the way organizations manage and access data. However, these technologies also come with challenges and limitations that organizations must address and mitigate to ensure data privacy, security, and compliance. Some of these challenges and limitations include:
- Data Privacy: Cloud storage and retrieval technologies involve storing data on third-party servers, which can raise concerns about data privacy and security. Organizations must ensure that they have robust data protection policies and procedures in place to protect sensitive data and prevent unauthorized access.
- Security: Cloud storage and retrieval technologies are vulnerable to cyber attacks and data breaches. Organizations must implement strong security measures, such as encryption, access controls, and intrusion detection systems, to protect their data and prevent unauthorized access.
- Compliance: Cloud storage and retrieval technologies must comply with various regulations and standards, such as HIPAA, GDPR, and PCI DSS. Organizations must ensure that their cloud storage and retrieval solutions comply with these regulations and standards to avoid penalties and fines.
- Vendor Lock-in: Cloud storage and retrieval technologies can create vendor lock-in, making it difficult for organizations to switch to a different provider or bring their data back in-house. Organizations must ensure that they have a clear exit strategy and can easily migrate their data to a different provider if needed.
- Cost: Cloud storage and retrieval technologies can be expensive, especially for organizations with large amounts of data. Organizations must carefully evaluate their storage and retrieval needs and choose a solution that meets their requirements while minimizing costs.
To address these challenges and limitations, organizations can adopt best practices and emerging solutions, such as:
- Data Encryption: Encrypting data before storing it in the cloud can help protect sensitive information and prevent unauthorized access.
- Access Controls: Implementing access controls, such as multi-factor authentication and role-based access control, can help ensure that only authorized users can access the data.
- Monitoring and Auditing: Regularly monitoring and auditing cloud storage and retrieval systems can help detect and prevent cyber attacks and data breaches.
- Data Backup and Disaster Recovery: Implementing data backup and disaster recovery strategies can help ensure that data is protected and can be quickly restored in case of a disaster or data loss.
- Contract Negotiation: Negotiating clear and concise contracts with cloud storage and retrieval providers can help ensure that organizations have a clear exit strategy and can avoid vendor lock-in.
By addressing these challenges and limitations, organizations can ensure that their cloud storage and retrieval systems are secure, compliant, and cost-effective. However, it is essential to continually monitor and optimize these systems to ensure that they meet the organization’s evolving storage and retrieval needs.
