
What are Recurrent Networks?
Recurrent Neural Networks (RNNs) are a type of artificial neural network designed to process sequential data, making them particularly suitable for tasks involving time series or natural language. Unlike traditional feedforward networks, RNNs have connections that form directed cycles, allowing them to maintain a form of “memory” that captures information about previous inputs in the sequence.
The concept of memory in RNNs enables them to model temporal dependencies, where the output at each time step is influenced by the current input and the historical context. This feature sets RNNs apart from other neural network architectures, such as convolutional neural networks (CNNs), which excel in processing spatial data but are less adept at handling sequential information.
RNNs have demonstrated remarkable success in various applications, including natural language processing, speech recognition, and time series prediction. Their ability to capture long-term dependencies in data makes them an invaluable tool for tasks that require understanding the context of a sequence, such as sentiment analysis, machine translation, and music generation.

How do Recurrent Networks Work?
Recurrent Neural Networks (RNNs) process sequential data by maintaining a form of internal memory that captures information about previous inputs in the sequence. This memory enables RNNs to model temporal dependencies, where the output at each time step is influenced by the current input and the historical context.
The backpropagation through time (BPTT) algorithm is the primary training method for RNNs. BPTT extends the backpropagation algorithm to sequences of inputs by unrolling the network through time and computing gradients for each time step. However, BPTT poses challenges, such as vanishing and exploding gradients, which can hinder the network’s ability to learn long-term dependencies.
To address these challenges, gating mechanisms, like Long Short-Term Memory (LSTM) and Gated Recurrent Unit (GRU) units, have been introduced. These mechanisms regulate the flow of information within the network, allowing RNNs to selectively forget or retain information, thereby improving their ability to capture long-term dependencies.
LSTM units consist of three primary components: the input, forget, and output gates. These gates control the flow of information into and out of a memory cell, which stores the network’s internal state. GRU units, on the other hand, combine the input and forget gates into a single update gate, simplifying the overall structure while maintaining the ability to capture long-term dependencies.
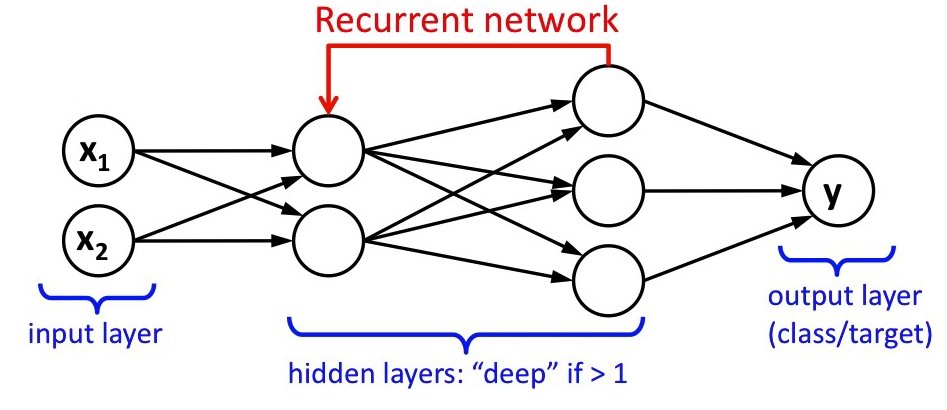
Applications of Recurrent Networks
Recurrent Neural Networks (RNNs) have been successfully applied in various real-world applications, thanks to their ability to process sequential data and capture long-term dependencies. Some prominent use cases include natural language processing, speech recognition, and time series prediction.
In natural language processing, RNNs have been employed for tasks such as sentiment analysis, machine translation, and text generation. By capturing the context of words within a sentence, RNNs can better understand the meaning and intent of the text, leading to more accurate and nuanced predictions.
Speech recognition is another area where RNNs excel. By processing audio data as a sequence of features, RNNs can model the temporal dependencies in speech, enabling them to recognize and transcribe spoken words with high accuracy. This technology is used in various applications, from virtual assistants like Siri and Alexa to automated transcription services.
Time series prediction is a common application of RNNs in finance, meteorology, and other fields where historical data is used to forecast future trends. By learning the patterns and dependencies in the data, RNNs can generate accurate predictions, helping professionals make informed decisions based on data-driven insights.
Overall, RNNs offer significant advantages in handling sequential data, making them an essential tool in various applications where understanding context and temporal dependencies is crucial.
Popular Recurrent Network Architectures
Various Recurrent Neural Network (RNN) architectures have been developed to address specific use cases and challenges. Some of the most popular RNN architectures include Elman networks, Jordan networks, and simple RNNs.
Elman Networks
Elman networks, also known as shallow RNNs, are a type of RNN with a single hidden layer. The hidden layer’s activation at time step t is fed back to itself at time step t+1, serving as the input to the hidden layer. Elman networks are suitable for tasks with short-term dependencies and are relatively easy to train compared to deeper RNNs.
Jordan Networks
Jordan networks are similar to Elman networks but use the output activation at time step t as input to the hidden layer at time step t+1. This architecture is beneficial for tasks where the output at each time step depends on the entire history of previous outputs. However, Jordan networks can be more challenging to train than Elman networks due to the increased complexity.
Simple RNNs
Simple RNNs, or fully connected RNNs, are the most basic form of RNNs, where the hidden layer at time step t is connected to the hidden layer at time step t+1. Simple RNNs can capture short-term dependencies but struggle with long-term dependencies due to challenges like vanishing and exploding gradients. Despite these limitations, simple RNNs remain a popular choice for tasks with short sequences and limited complexity.
Each of these RNN architectures has its strengths and weaknesses, making them suitable for different applications. Choosing the right architecture depends on the specific task, data, and desired performance trade-offs.

Training and Optimizing Recurrent Networks
Training Recurrent Neural Networks (RNNs) involves optimizing their parameters to minimize a loss function that measures the difference between the predicted output and the true output. The training process consists of data preprocessing, hyperparameter tuning, and optimization techniques.
Data Preprocessing
Data preprocessing for RNNs includes cleaning, normalization, and transformation. Sequential data should be split into training, validation, and test sets to ensure the model’s generalization performance. Additionally, techniques like padding and truncation may be applied to handle sequences of varying lengths.
Hyperparameter Tuning
Hyperparameter tuning is crucial for the successful training of RNNs. Key hyperparameters include the learning rate, batch size, number of hidden units, and the number of layers. Various techniques, such as grid search, random search, and Bayesian optimization, can be employed to find the optimal hyperparameter values.
Optimization Techniques
Optimization techniques for RNN training include gradient descent and its variants, such as stochastic gradient descent (SGD), mini-batch gradient descent, and Adam. These methods aim to minimize the loss function by iteratively adjusting the model’s parameters in the direction of the negative gradient.
During training, RNNs can face challenges like overfitting and slow convergence. Overfitting occurs when the model learns the training data too well, resulting in poor generalization performance on unseen data. Techniques like regularization, dropout, and early stopping can help mitigate overfitting. Slow convergence, on the other hand, can be addressed by using adaptive learning rates, momentum, or second-order optimization methods.
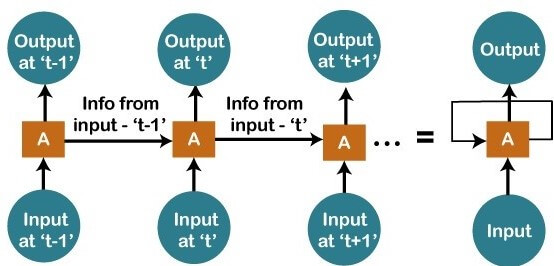
Evaluating the Performance of Recurrent Networks
Evaluating the performance of Recurrent Neural Networks (RNNs) is crucial for understanding their effectiveness and identifying areas for improvement. Various metrics, such as accuracy, perplexity, and loss functions, can be used to assess the performance of RNNs. Additionally, visualization techniques can help interpret and understand the “black box” nature of these models.
Accuracy
Accuracy is a common metric for evaluating the performance of RNNs, especially in classification tasks. It measures the proportion of correct predictions out of the total number of predictions. However, accuracy alone might not be sufficient for tasks with imbalanced data or when dealing with rare events.
Perplexity
Perplexity is a popular metric for evaluating language models, which are often based on RNNs. It measures how well the model predicts the test data by taking the exponential of the average cross-entropy loss per word. Lower perplexity indicates better performance in modeling the probability distribution of the data.
Loss Functions
Loss functions, such as mean squared error (MSE) or cross-entropy loss, are used to train RNNs by comparing the predicted output with the true output. Monitoring the loss function during training and validation can provide insights into the model’s performance and help diagnose issues like overfitting or underfitting.
Visualization Techniques
Visualization techniques can help interpret and understand the “black box” nature of RNNs. Techniques like saliency maps, activation maximization, and layer-wise relevance propagation (LRP) can reveal which input features contribute the most to the model’s predictions, providing insights into the model’s decision-making process.
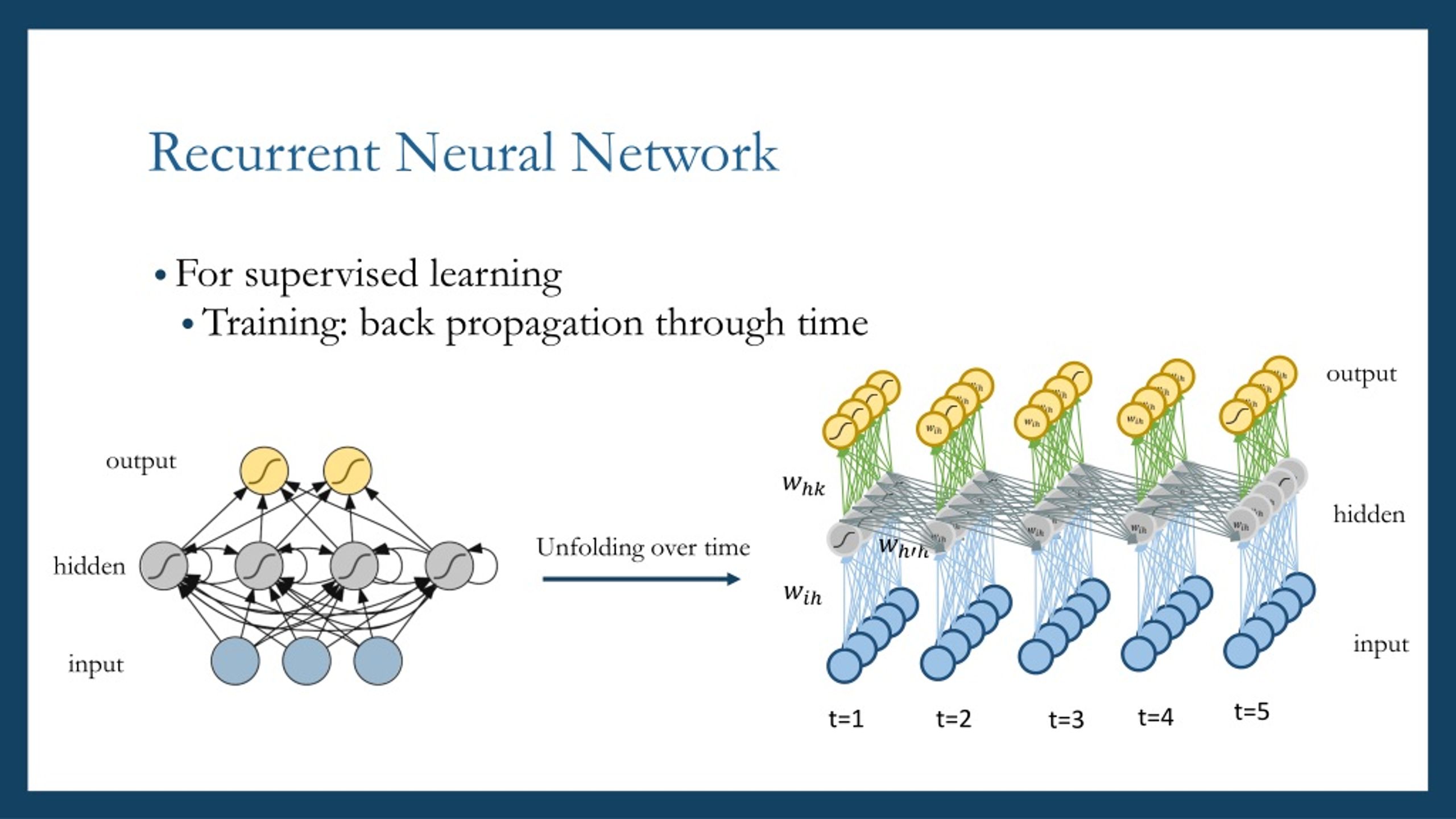
Recurrent Networks vs. Other Sequence Models
Recurrent Neural Networks (RNNs) are not the only sequence models available for processing sequential data. Alternative models, such as Convolutional Neural Networks (CNNs) and Transformers, also have the capability to handle sequences, albeit with different strengths and weaknesses. Understanding the trade-offs between these models can help practitioners choose the most suitable one for their specific application.
Recurrent Networks vs. Convolutional Neural Networks (CNNs)
CNNs are primarily designed for spatial data, such as images, but can also be applied to sequences by treating the input as a 1D signal. While RNNs maintain an internal state that captures information from previous time steps, CNNs rely on convolutional filters that slide across the input sequence, capturing local patterns and dependencies. RNNs are generally better at handling long-term dependencies, but CNNs can be more efficient in terms of computational resources and may perform better on short sequences or when parallelization is desired.
Recurrent Networks vs. Transformers
Transformers are a type of sequence model that has gained popularity in natural language processing tasks. Unlike RNNs, Transformers do not maintain an internal state and instead rely on self-attention mechanisms to capture dependencies between input elements. This architecture allows Transformers to process sequences in parallel, making them more computationally efficient than RNNs for long sequences. However, RNNs, especially those with gating mechanisms like LSTMs and GRUs, can still outperform Transformers on tasks requiring the explicit modeling of long-term dependencies.
In summary, RNNs, CNNs, and Transformers each have their unique strengths and weaknesses. When working with sequential data, it is essential to consider the specific requirements of the task, such as the length of the sequences, the need for parallelization, and the importance of capturing long-term dependencies, to determine the most suitable model.
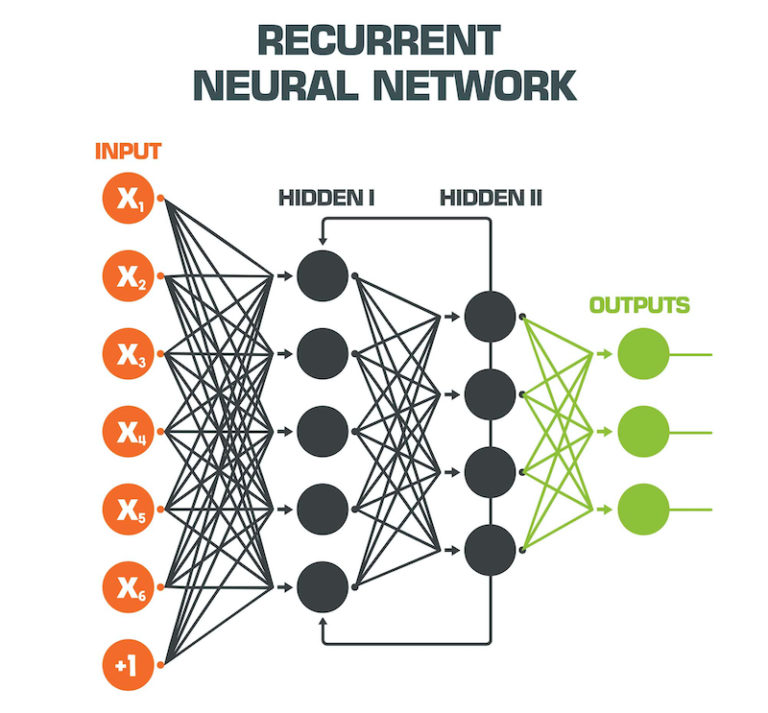
Future Trends and Research Directions in Recurrent Networks
Recurrent Neural Networks (RNNs) have proven to be a powerful tool for processing sequential data, and their development continues to be an active area of research. Several emerging trends and research directions are shaping the future of RNNs, including new architectures, training algorithms, and applications.
New Architectures
Recent advances in RNN architectures focus on improving the modeling of long-term dependencies and addressing the challenges of vanishing and exploding gradients. Novel gating mechanisms, such as the recently proposed “Fraternal Twins” and “Transformer-XL,” aim to further enhance the performance of RNNs on sequential data.
Training Algorithms
Efficient and robust training algorithms are essential for the successful application of RNNs. Research in this area includes the development of adaptive learning rate methods, second-order optimization techniques, and methods for better regularization and normalization. These advancements aim to improve the generalization performance of RNNs and reduce their sensitivity to hyperparameter settings.
Applications
RNNs have been successfully applied to various domains, and new applications continue to emerge. For instance, RNNs have shown promise in healthcare for tasks like disease diagnosis and treatment planning, where they can process time series data from electronic health records. Additionally, RNNs are being explored for their potential in reinforcement learning, where they can be used to model the sequential decision-making process in complex environments.
In conclusion, Recurrent Neural Networks remain an exciting and rapidly evolving field, with numerous opportunities for innovation and development. By staying informed about the latest trends and research directions, practitioners can contribute to the ongoing advancement of RNNs and their successful application in various domains.
