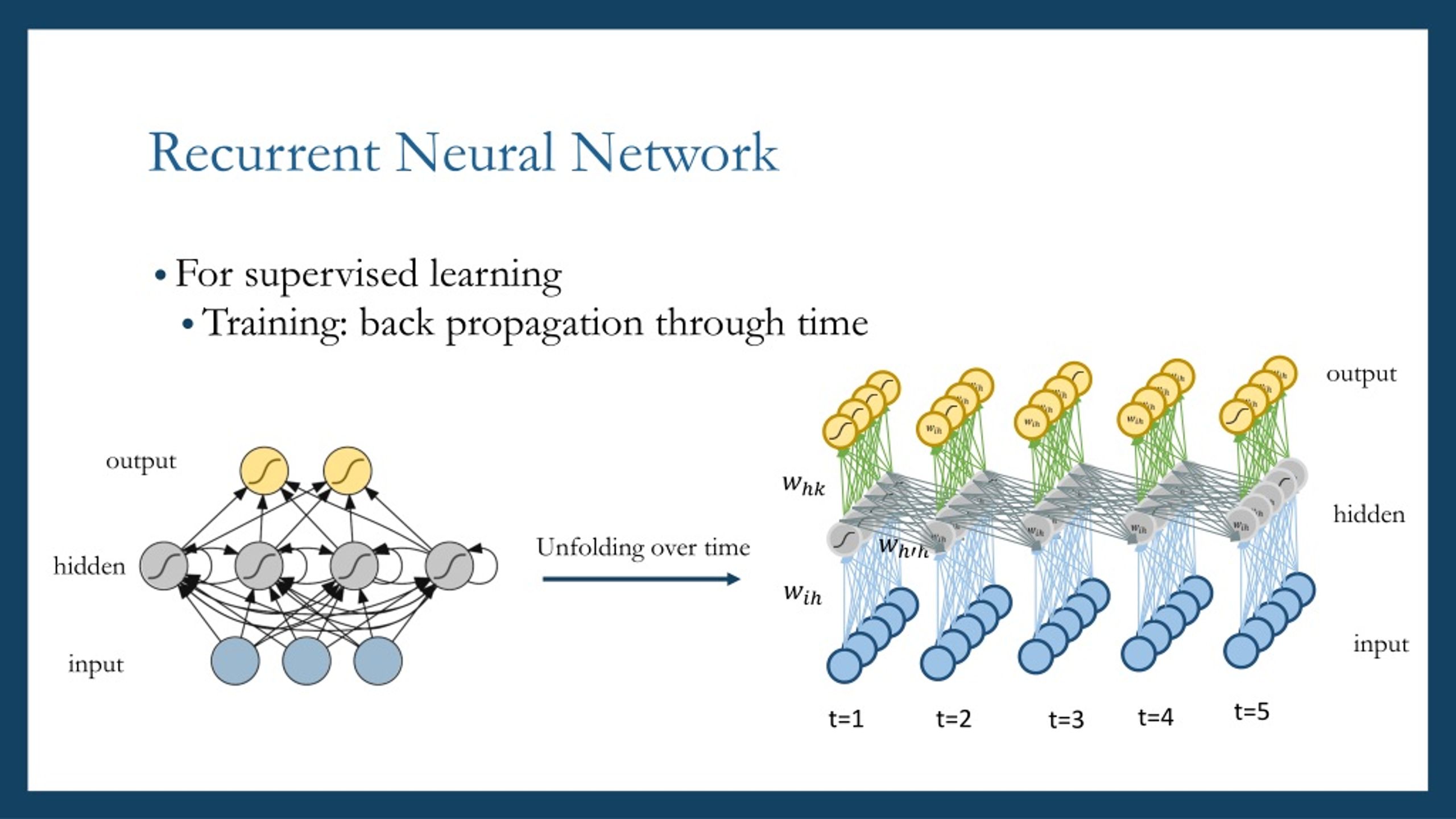
What is a Recurrent Layer Neural Network?
Recurrent Layer Neural Networks (RNNs) are a specialized class of artificial neural networks designed to process sequential data, such as time series, natural language, or speech signals. Unlike traditional feedforward neural networks, RNNs have a temporal dynamic behavior, allowing them to capture and model patterns across time. This unique feature makes RNNs particularly suitable for a wide range of applications, including natural language processing, speech recognition, and time series prediction.
At the heart of an RNN lies the concept of hidden states, which serve as a form of memory that encodes information from previous time steps. This memory enables RNNs to maintain a form of internal context, allowing them to make decisions based not only on the current input but also on the historical context. The hidden states are updated as new inputs arrive, and the information flows through the network over time, giving RNNs their distinctive recurrent structure.
The training process of RNNs involves a technique called backpropagation through time (BPTT), which extends the backpropagation algorithm to handle sequences of variable lengths. BPTT unrolls the network over time, allowing the gradients to be computed and propagated backward through the unrolled network, updating the weights and biases to minimize the overall error.

How Do Recurrent Layer Neural Networks Work?
Recurrent Layer Neural Networks (RNNs) have a unique internal structure that enables them to process sequential data. The key component of an RNN is the hidden state, which acts as a form of memory that encodes information from previous time steps. This memory allows RNNs to maintain a sense of context and make decisions based on both the current input and historical information.
At each time step, an RNN receives an input vector and updates its hidden state based on the current input and the previous hidden state. This update process can be mathematically represented as:
ht = f(Wihxt + Whhht−1 + b)
where:
htis the hidden state at time steptxtis the input vector at time steptWihandWhhare the weight matrices connecting the input and previous hidden state to the current hidden state, respectivelybis the bias vectorfis a nonlinear activation function, such as the hyperbolic tangent (tanh) or rectified linear unit (ReLU)
The hidden state ht is then used to compute the output vector at time step t, which can be represented as:
yt = Whoht + b'
where:
ytis the output vector at time steptWhois the weight matrix connecting the hidden state to the outputb'is the bias vector for the output
The training process of RNNs involves a technique called backpropagation through time (BPTT), which extends the backpropagation algorithm to handle sequences of variable lengths. BPTT unrolls the network over time, allowing the gradients to be computed and propagated backward through the unrolled network, updating the weights and biases to minimize the overall error.
Use Cases for Recurrent Layer Neural Networks
Recurrent Layer Neural Networks (RNNs) have a wide range of applications in various domains, thanks to their ability to model sequential data. Some prominent use cases for RNNs include:
Natural Language Processing (NLP)
RNNs are extensively used in NLP tasks, such as language modeling, sentiment analysis, and machine translation. For instance, RNNs can be trained to predict the next word in a sentence, given the previous words, enabling applications like text generation and chatbots. In sentiment analysis, RNNs can capture the context in a text to determine the overall sentiment, outperforming traditional bag-of-words models.
Speech Recognition
RNNs are instrumental in speech recognition systems, where they convert spoken language into written text. By modeling the temporal dependencies in speech signals, RNNs can effectively recognize and transcribe speech, even in noisy environments. Deep Speech, a Mozilla project, is an example of a state-of-the-art speech recognition system based on RNNs.
Time Series Prediction
RNNs excel in time series forecasting, where the goal is to predict future values based on historical data. Applications include stock price prediction, weather forecasting, and demand forecasting for inventory management. RNNs can capture the complex patterns and trends in time series data, providing accurate predictions and valuable insights for decision-making.
Case Study: Language Modeling with RNNs
A notable example of RNNs in NLP is the language modeling task, where the goal is to predict the next word in a sequence given the context. Google’s word2vec project demonstrated the power of RNNs in capturing semantic relationships between words, enabling applications like word embeddings and semantic similarity analysis.
Popular Types of Recurrent Layer Neural Networks
Several variants of Recurrent Layer Neural Networks (RNNs) have been developed to address specific challenges and improve their performance in various applications. Some popular types of RNNs include:
Long Short-Term Memory (LSTM) Networks
LSTM networks are a type of RNN designed to tackle the challenge of modeling long-term dependencies in sequential data. They introduce a memory cell and three gating mechanisms (input, output, and forget gates) that control the flow of information, enabling LSTMs to selectively remember or forget information over time. LSTMs have been successful in various applications, such as speech recognition, machine translation, and sentiment analysis.
Gated Recurrent Units (GRUs)
GRUs are a simplified version of LSTMs, merging the input and forget gates into a single update gate. This simplification reduces the number of parameters and computational complexity, making GRUs faster to train than LSTMs while still delivering competitive performance. GRUs are particularly effective in tasks where long-term dependencies are less critical, such as part-of-speech tagging and named entity recognition.
Echo State Networks (ESNs)
ESNs are a type of sparsely connected RNN that randomly initialize the weights of the hidden layer and keep them fixed during training. This simplification allows ESNs to avoid the vanishing gradient problem and significantly reduces the training time. ESNs have been successfully applied to tasks like time series prediction, chaotic time series generation, and nonlinear system identification.
Comparing LSTMs, GRUs, and ESNs
Each type of RNN has its advantages and disadvantages. LSTMs are suitable for tasks requiring the modeling of long-term dependencies and have demonstrated success in various applications. GRUs offer a trade-off between LSTMs and simpler RNNs, providing competitive performance with fewer parameters and computational complexity. ESNs, on the other hand, are an efficient choice for tasks with short-term dependencies, as they avoid the vanishing gradient problem and require minimal training time.
Training and Optimizing Recurrent Layer Neural Networks
Training Recurrent Layer Neural Networks (RNNs) effectively can be challenging due to issues like vanishing and exploding gradients, which affect the model’s ability to learn long-term dependencies. To address these challenges, several strategies have been developed:
Handling Vanishing and Exploding Gradients
To mitigate the vanishing gradient problem, researchers have proposed techniques like gradient clipping, weight initialization methods, and long short-term memory (LSTM) networks. Gradient clipping limits the norm of the gradients to prevent them from exploding or vanishing, while weight initialization methods like orthogonal initialization and Xavier initialization help maintain a balanced distribution of weights.
Regularization Methods
Regularization techniques, such as dropout, weight decay, and zoneout, can help prevent overfitting and improve the generalization of RNNs. Dropout randomly sets a fraction of hidden units to zero during training, while weight decay adds an L2 penalty to the loss function to prevent the weights from growing too large. Zoneout, a variant of dropout for RNNs, randomly retains the hidden state of a unit from the previous time step, promoting the preservation of information over time.
Hyperparameter Tuning
Hyperparameter tuning is crucial for the successful training of RNNs. Key hyperparameters include the learning rate, batch size, number of hidden units, and the number of layers. Techniques like grid search, random search, and Bayesian optimization can help find the optimal set of hyperparameters for a given problem.
Optimizers
Choosing the right optimizer can significantly impact the training of RNNs. Popular optimizers include Stochastic Gradient Descent (SGD), Momentum, Adagrad, Adadelta, RMSProp, and Adam. These optimizers employ different strategies to adapt the learning rate during training, improving convergence and model performance.
Challenges and Limitations of Recurrent Layer Neural Networks
Despite their powerful capabilities, Recurrent Layer Neural Networks (RNNs) face several challenges and limitations that can impact their performance:
Difficulty Modeling Long-Term Dependencies
One major challenge in training RNNs is the vanishing gradient problem, which makes it difficult for the network to learn long-term dependencies. As the gradient information is backpropagated through time, it may decrease exponentially, causing the network to prioritize learning short-term dependencies over long-term ones.
Sensitivity to Input Order
RNNs are sensitive to the order of input sequences, which can lead to inconsistent performance when the input order is altered. This sensitivity can be problematic in applications where the input order is not well-defined or may change during deployment.
Computational Complexity
RNNs can be computationally expensive, especially when dealing with long sequences, due to the need to maintain hidden states for each time step. This computational complexity can lead to longer training times and increased memory requirements, making it challenging to scale RNNs to larger datasets or more complex tasks.
Exploding Gradients
In some cases, the gradients during backpropagation through time may grow excessively large, leading to exploding gradients. Exploding gradients can cause the weights to update rapidly, leading to unstable training and poor model performance.
Solutions and Mitigations
To address these challenges, researchers have proposed various techniques, such as gradient clipping, weight initialization methods, long short-term memory (LSTM) networks, and gated recurrent units (GRUs). Additionally, regularization methods like dropout, weight decay, and zoneout can help prevent overfitting and improve the generalization of RNNs.
Emerging Trends and Future Directions in Recurrent Layer Neural Networks
Recurrent Layer Neural Networks (RNNs) have shown significant promise in various applications, and ongoing research continues to uncover new ways to improve and extend their capabilities:
Integration of Attention Mechanisms
Attention mechanisms have been increasingly integrated into RNNs to help the networks focus on relevant information and improve their ability to model long-term dependencies. Attention-based RNNs have been successful in applications like machine translation, text summarization, and image captioning.
Capsule Networks
Capsule networks are a relatively new development in neural networks that aim to better capture hierarchical relationships and spatial information. By incorporating capsule networks into RNNs, researchers hope to enhance the networks’ ability to model complex sequential data, such as video and audio.
Transformers
Transformers are a type of neural network architecture designed for handling sequential data, particularly in natural language processing tasks. Transformers have shown superior performance in machine translation, text classification, and question answering, outperforming traditional RNNs and convolutional neural networks (CNNs).
Future Research Directions
Future research in RNNs may focus on addressing current challenges, such as the vanishing gradient problem, computational complexity, and sensitivity to input order. Additionally, researchers may explore the integration of RNNs with other advanced techniques, like reinforcement learning, few-shot learning, and unsupervised learning, to further expand their capabilities and applicability.

Conclusion: The Power and Potential of Recurrent Layer Neural Networks
Recurrent Layer Neural Networks (RNNs) have emerged as a powerful and versatile tool for handling sequential data, offering significant advantages over traditional feedforward neural networks. By incorporating hidden states and backpropagation through time, RNNs can effectively model complex temporal dependencies and have demonstrated success in various applications, such as natural language processing, speech recognition, and time series prediction.
Despite their remarkable capabilities, RNNs face several challenges, including difficulty modeling long-term dependencies, sensitivity to input order, and computational complexity. However, ongoing research continues to address these issues, with recent advancements in attention mechanisms, capsule networks, and transformers further expanding the potential of RNNs.
As the field of machine learning and artificial intelligence evolves, RNNs will undoubtedly remain an essential component in the development of innovative and creative solutions to complex real-world problems. By leveraging the unique strengths of RNNs, researchers and practitioners can unlock new opportunities for automation, prediction, and understanding in a wide range of domains, ultimately driving progress and delivering value to society.