
What are Neural Networks and Why Use Python?
Neural networks are a category of machine learning algorithms designed to recognize patterns and model complex relationships in data. They are inspired by the human brain’s structure and function, comprising interconnected layers of nodes or artificial neurons. These networks can learn and improve from experience, making them highly effective for various applications, such as image and speech recognition, natural language processing, and predictive analytics.
Python has emerged as the go-to programming language for implementing neural networks, thanks to its simplicity, versatility, and extensive library support. Libraries like TensorFlow, Keras, and PyTorch provide pre-built functions and modules, enabling developers to design, train, and deploy neural networks with ease. Furthermore, Python’s readability and active community foster collaboration and knowledge sharing, making it an ideal choice for both beginners and experienced practitioners in the field of artificial intelligence and machine learning.

Setting Up Your Python Environment
To begin working with neural networks in Python, you’ll need to set up a suitable environment. Start by installing Python, if you haven’t already, and ensure that you have a recent version (3.6 or higher) for optimal compatibility with popular libraries. Next, install essential libraries for neural network development, such as TensorFlow, Keras, and NumPy. These libraries provide pre-built functions and modules, simplifying the process of designing, training, and deploying neural networks.
To install TensorFlow, Keras, and NumPy, you can use Python’s package manager, pip. Open your terminal or command prompt and enter the following commands:
pip install tensorflow keras numpy Once the installation is complete, you can verify the successful installation of these libraries by importing them in a Python script or interactive session. Here’s an example:
import tensorflow as tf import keras import numpy as np If the libraries are installed correctly, you will not encounter any import errors. With the Python environment set up, you can now proceed to build and train your first neural network using Python.

Building a Simple Neural Network with Python
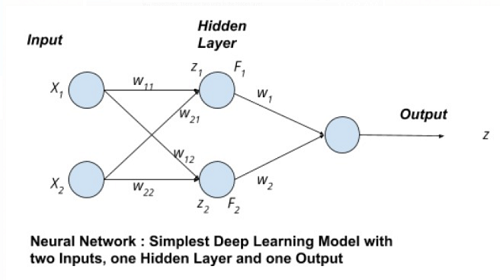
Now that you have your Python environment set up, it’s time to create a basic neural network. At its core, a neural network comprises input and output layers, as well as one or more hidden layers that process the data. Each layer contains nodes or artificial neurons, and the connections between these nodes are called weights. Activation functions determine the output of each node, introducing non-linearity into the model.
Let’s walk through the process of building a simple neural network using Python and Keras. First, import the necessary libraries:
import numpy as np from keras.models import Sequential from keras.layers import Dense Next, create a dataset to train the neural network. For simplicity, we’ll use a synthetic dataset:
X = np.random.random((1000, 20)) y = keras.utils.to_categorical(np.random.randint(10, size=(1000, 1)), num_classes=10) Now, create the neural network model. In this example, we’ll use a simple feedforward neural network with one input layer, one hidden layer, and one output layer:
model = Sequential() model.add(Dense(64, activation='relu', input_dim=20)) model.add(Dense(10, activation='softmax')) Finally, compile the model and fit it to the dataset:
model.compile(loss='categorical_crossentropy', optimizer='sgd', metrics=['accuracy']) model.fit(X, y, epochs=10, batch_size=32) This simple example demonstrates the fundamental components of a neural network, including input and output layers, hidden layers, and activation functions. With a solid understanding of these concepts, you can now explore more advanced topics, such as backpropagation, optimization techniques, and performance improvement strategies.
Training Your Neural Network: Backpropagation and Optimization
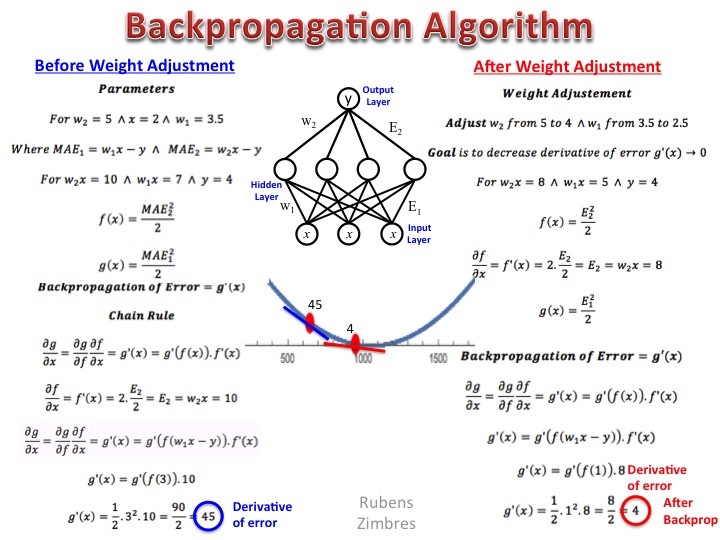
Training a neural network involves adjusting the weights and biases of the connections between nodes to minimize the difference between the predicted output and the actual output. This process is called backpropagation, which calculates the gradient of the loss function concerning each weight and bias, allowing the network to update them iteratively. The optimization techniques used during training aim to find the optimal set of weights and biases that minimize the loss function.
Selecting the appropriate loss function and optimizer is crucial for successful neural network training. The loss function, also known as the error or cost function, measures the difference between the predicted and actual outputs. Common loss functions include mean squared error (MSE) for regression tasks and categorical cross-entropy for classification tasks. The optimizer, on the other hand, determines the strategy for updating the weights and biases during training. Popular optimizers include stochastic gradient descent (SGD), Adam, and RMSprop.
Here’s an example of how to train a neural network using the mean squared error loss function and the Adam optimizer in Python and Keras:
model.compile(loss='mean_squared_error', optimizer='adam', metrics=['accuracy']) model.fit(X, y, epochs=10, batch_size=32) During training, the neural network will use backpropagation to calculate the gradients of the loss function concerning each weight and bias, and the Adam optimizer will update the weights and biases iteratively to minimize the loss function. By understanding the concepts of backpropagation and optimization, you can effectively train your neural network to perform complex tasks and solve real-world problems.
How to Improve Performance: Regularization and Hyperparameter Tuning
Neural networks can sometimes suffer from overfitting, where the model performs well on the training data but poorly on unseen data. To address this issue, regularization techniques and hyperparameter tuning can be employed to improve the performance of your neural network. Regularization techniques, such as L1, L2, and dropout, help prevent overfitting by adding a penalty term to the loss function or modifying the network architecture. Hyperparameter tuning, on the other hand, involves finding the optimal set of hyperparameters for your neural network, such as the learning rate, batch size, and number of epochs.
Regularization Techniques
L1 and L2 regularization techniques add a penalty term to the loss function, encouraging the model to have smaller weights and biases. Dropout, a regularization technique that randomly drops a percentage of nodes during training, helps prevent overfitting by promoting the development of redundant representations within the network.
Hyperparameter Tuning
Hyperparameter tuning can significantly impact the performance of your neural network. Common methods for hyperparameter tuning include grid search and random search. Grid search involves systematically iterating through a predefined set of hyperparameters, while random search selects hyperparameters at random within a specified range. Both methods aim to find the optimal set of hyperparameters that minimize the validation loss.
Here’s an example of how to implement L2 regularization and hyperparameter tuning using grid search in Python and Keras:
from keras.wrappers.scikit_learn import KerasClassifier from sklearn.model_selection import GridSearchCV from keras.regularizers import Regularizer def create_model(learning_rate=0.01, batch_size=32, epochs=10, l2=0.0): model = Sequential() model.add(Dense(64, activation='relu', input_dim=20, kernel_regularizer=Regularizer('l2', l2))) model.add(Dense(10, activation='softmax')) model.compile(loss='categorical_crossentropy', optimizer=keras.optimizers.Adam(lr=learning_rate), metrics=['accuracy']) return model model = KerasClassifier(build_fn=create_model, verbose=0) param_grid = {'batch_size': [16, 32, 64], 'epochs': [5, 10, 15], 'l2': [0.0, 0.01, 0.1]} grid = GridSearchCV(estimator=model, param_grid=param_grid, cv=3) grid_result = grid.fit(X, y) By incorporating regularization techniques and hyperparameter tuning, you can improve the performance of your neural network, ensuring that it generalizes well to unseen data and effectively solves real-world problems.

Applying Neural Networks to Real-World Problems
Neural networks have proven to be highly effective in solving a wide range of real-world problems across various industries. In this section, we will explore several applications of neural networks using Python, including image recognition, natural language processing, and time series forecasting.
Image Recognition
Image recognition is a common application of neural networks, where the goal is to identify and classify objects within an image. Convolutional Neural Networks (CNNs), a specialized type of neural network, are particularly well-suited for image recognition tasks. With Python and libraries like TensorFlow and Keras, you can quickly build and train CNNs to classify images from datasets such as CIFAR-10, MNIST, or even more complex datasets like ImageNet.
Natural Language Processing
Natural Language Processing (NLP) involves analyzing and understanding human language, enabling machines to communicate more effectively with humans. Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) networks, both types of neural networks, are commonly used for NLP tasks such as sentiment analysis, text classification, and language translation.
Time Series Forecasting
Time series forecasting is the process of predicting future values based on historical data. Neural networks, such as Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) networks, can be used to model complex temporal dependencies and make accurate predictions. With Python and libraries like TensorFlow and Keras, you can build and train neural networks to forecast stock prices, weather patterns, or other time-series data.
By understanding the applications of neural networks in real-world problems, you can leverage the power of these algorithms to build innovative and impactful solutions. Python, with its extensive library support and versatility, is an ideal choice for implementing and experimenting with neural networks in various domains.
Trends and Future Directions in Neural Network Research
Neural networks and deep learning have experienced rapid advancements in recent years, and research in these areas continues to push the boundaries of machine learning. In this section, we will explore several emerging trends and future directions in neural network research, including the development of deep learning architectures, reinforcement learning, and transfer learning.
Deep Learning Architectures
Deep learning architectures, such as Convolutional Neural Networks (CNNs), Recurrent Neural Networks (RNNs), and Long Short-Term Memory (LSTM) networks, have proven to be highly effective in various applications. Future research will focus on refining these architectures, developing new ones, and improving their efficiency and scalability. For instance, researchers are exploring the use of capsule networks, a type of CNN that better captures hierarchical relationships between features, and attention mechanisms, which allow models to focus on the most relevant parts of the input.
Reinforcement Learning
Reinforcement learning, a type of machine learning where an agent learns to make decisions by interacting with an environment, has gained significant attention in recent years. Future research in reinforcement learning will focus on developing more sophisticated algorithms, improving sample efficiency, and scaling up these algorithms to handle complex real-world problems. Additionally, researchers are exploring the integration of deep learning techniques with reinforcement learning to create deep reinforcement learning models, which have achieved remarkable results in various domains, such as game playing and robotics.
Transfer Learning
Transfer learning, the process of applying knowledge gained from one task to another related task, has become increasingly popular in deep learning. Future research in transfer learning will focus on developing more effective techniques for transferring knowledge across tasks, improving fine-tuning strategies, and understanding the theoretical foundations of transfer learning. These advancements will enable practitioners to build more accurate and efficient models with less data, reducing the time and resources required for training.
By staying up-to-date with the latest trends and future directions in neural network research, you can continue to harness the power of these algorithms to solve complex machine learning problems and drive innovation in your field.

Conclusion: The Power of Neural Networks and Python
Throughout this comprehensive guide, we have explored the fundamentals of neural networks and their implementation using Python. By mastering the concepts covered in this article, you are now equipped to tackle complex machine learning problems and unlock the potential of neural networks and Python.
Neural networks, with their ability to model intricate patterns and relationships in data, have become an indispensable tool in modern data science and machine learning. Python, as a versatile and popular programming language, offers a wealth of libraries and frameworks, such as TensorFlow, Keras, and NumPy, that simplify the process of building, training, and deploying neural networks.
In this guide, we have covered the essential steps for working with neural networks in Python, from setting up your environment and creating a simple neural network to applying regularization techniques, optimizing hyperparameters, and exploring real-world applications. Furthermore, we have highlighted emerging trends and future directions in neural network research, ensuring that you remain at the forefront of this rapidly evolving field.
As you continue your journey in mastering neural networks with Python, remember to stay curious, experiment with new ideas, and embrace the challenges that come with working on complex machine learning problems. By doing so, you will not only enhance your skills but also contribute to the ongoing advancements in the field of artificial intelligence and machine learning.
