Understanding Machine Learning Algorithms: A Broad Perspective
Machine learning algorithms are essential components of artificial intelligence (AI) that enable computers to learn from data and make predictions or decisions without explicit programming. These algorithms have become increasingly popular in various industries, including finance, healthcare, marketing, and transportation, to name a few. The ability to analyze vast amounts of data and extract meaningful insights has led to significant advancements in machine learning, making it a critical area of study for researchers and practitioners alike.
Understanding different types of machine learning algorithms and their applications is crucial for anyone looking to harness their power. Machine learning algorithms can be broadly classified into three categories: supervised learning, unsupervised learning, and reinforcement learning. Supervised learning involves training a model on labeled data to predict outcomes, while unsupervised learning deals with identifying patterns in unlabeled data. Reinforcement learning, on the other hand, involves training an agent to make decisions based on rewards and penalties in a dynamic environment.
In this article, we will explore popular machine learning algorithms and their real-world applications, focusing on examples that demonstrate their power and potential. By the end, you will have a better understanding of machine learning algorithms and how they can be used to solve complex problems in various industries.
.jpg)
Popular Machine Learning Algorithms: A Comprehensive Overview
Machine learning algorithms are powerful tools for data analysis and prediction, and several popular algorithms are widely used across various industries. Here, we will discuss some of the most commonly used machine learning algorithms and their applications:
- Linear Regression: Linear regression is a simple yet effective algorithm used for predicting a continuous outcome variable based on one or more predictor variables. It is widely used in finance, economics, and social sciences to model trends and relationships between variables.
- Logistic Regression: Logistic regression is a variation of linear regression used for predicting binary outcomes, such as pass/fail or yes/no. It is commonly used in marketing, healthcare, and social sciences to model the probability of an event occurring based on one or more predictor variables.
- Decision Trees: Decision trees are a type of algorithm used for both classification and regression tasks. They recursively split data into subsets based on the most significant attributes, creating a tree-like structure that can be used for making decisions or predictions. Decision trees are commonly used in finance, marketing, and healthcare for segmenting customers, predicting outcomes, and identifying important factors.
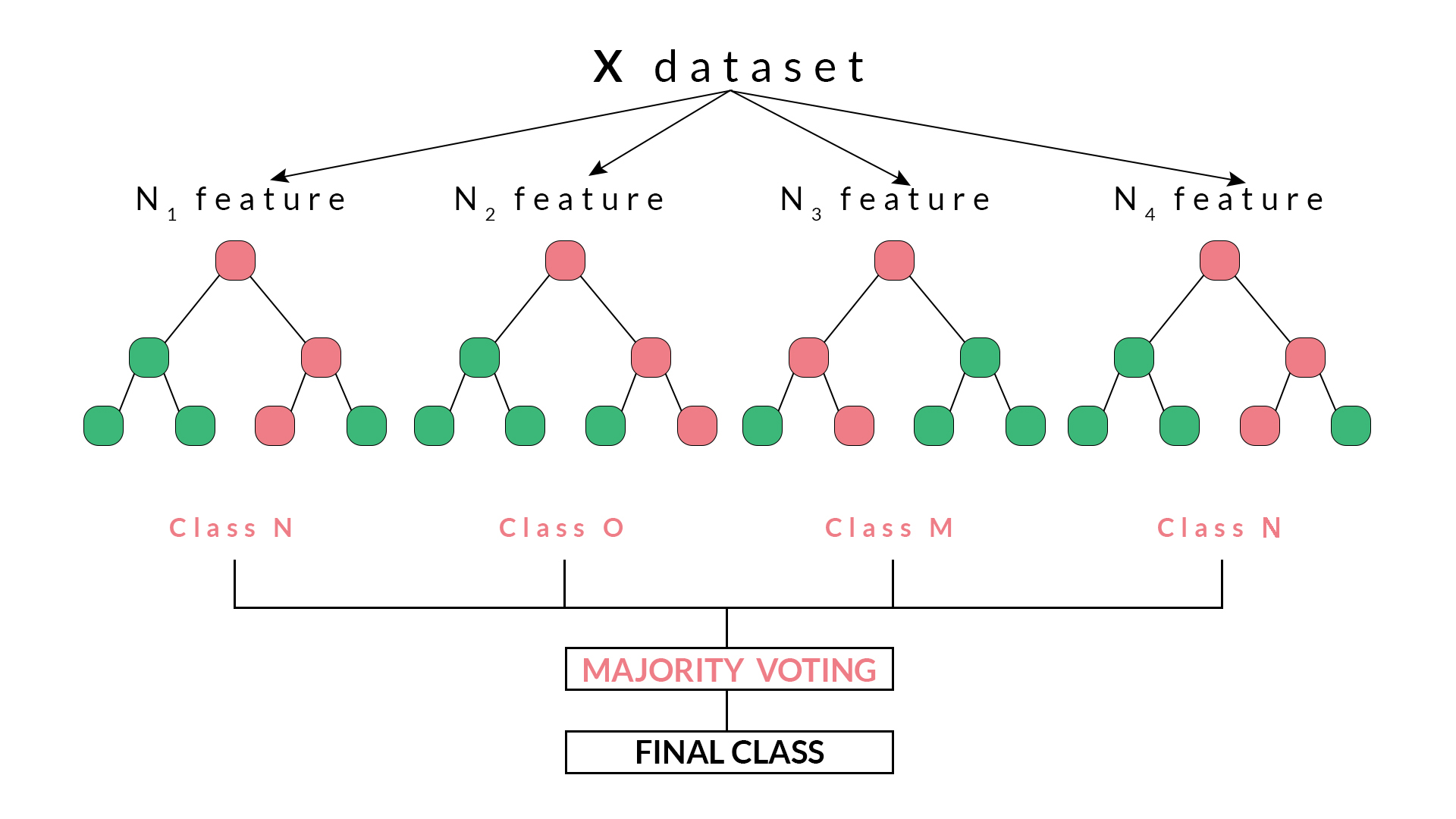
- Random Forest: Random forest is an ensemble algorithm that combines multiple decision trees to improve accuracy and reduce overfitting. It is widely used in finance, marketing, and healthcare for predicting outcomes, identifying important factors, and reducing the risk of overfitting.
- Support Vector Machines (SVMs): SVMs are a type of algorithm used for classification and regression tasks. They work by finding the optimal boundary or hyperplane that separates data into classes or predicts continuous outcomes. SVMs are commonly used in finance, marketing, and healthcare for detecting fraud, segmenting customers, and predicting outcomes.
- Neural Networks: Neural networks are a type of algorithm inspired by the structure and function of the human brain. They consist of interconnected nodes or neurons that process and transmit information. Neural networks are commonly used in image and speech recognition, natural language processing, and predictive modeling.
Understanding these popular machine learning algorithms and their applications is crucial for anyone looking to harness their power in real-world scenarios. In the following sections, we will explore real-world examples of how these algorithms are used to solve complex problems and improve decision-making in various industries.
Real-World Example: Predicting Housing Prices with Linear Regression
Linear regression is a popular machine learning algorithm used for predicting continuous outcomes based on one or more predictor variables. In this section, we will explore how linear regression can be used to predict housing prices, a common application in the real estate industry.
Imagine you are a real estate analyst tasked with predicting the selling price of a house based on its size, location, age, and other relevant factors. Linear regression can be used to model the relationship between these predictor variables and the selling price, allowing you to make accurate predictions and inform your decision-making process.
To apply linear regression to this problem, you would first gather historical data on housing prices, along with information on the size, location, age, and other relevant factors of each house. Next, you would use linear regression to estimate the coefficients or weights associated with each predictor variable, indicating their relative importance in predicting the selling price.
Once the model is trained, you can use it to predict the selling price of a new house based on its size, location, age, and other relevant factors. For example, if a house has a size of 2000 square feet, is located in a desirable neighborhood, and is 10 years old, the model might predict a selling price of $500,000.
Linear regression is a simple yet powerful algorithm for predicting housing prices and other continuous outcomes. By understanding the relationship between predictor variables and the outcome variable, you can make informed decisions and gain valuable insights into complex problems.
Real-World Example: Classifying Customer Segments with Decision Trees and Random Forest
Machine learning algorithms can be used to classify customer segments based on various factors, such as demographics, purchasing behavior, and preferences. Decision trees and random forest are two popular algorithms used for this purpose. In this section, we will explore how these algorithms can be applied to classify customer segments.
Imagine you are a marketing analyst for a retail company looking to better understand your customer base. You have collected data on customer demographics, purchasing behavior, and preferences, and you want to segment your customers into distinct groups to tailor your marketing strategies.
Decision trees can be used to create a series of rules or questions based on the predictor variables, allowing you to segment your customers into distinct groups. For example, you might create a decision tree that segments customers based on age, income, and the types of products they purchase. Customers who are over 30, have an income over $50,000, and purchase electronics would be segmented into one group, while customers who are under 30, have an income under $50,000, and purchase clothing would be segmented into another group.
Random forest is an ensemble algorithm that combines multiple decision trees to improve accuracy and reduce overfitting. By aggregating the results of multiple decision trees, random forest can provide a more robust and accurate classification of customer segments. For example, a random forest algorithm might segment customers into groups based on age, income, and product preferences, as well as other factors, such as geographic location and education level.
By using decision trees and random forest to classify customer segments, you can gain valuable insights into your customer base and tailor your marketing strategies to better meet their needs. These algorithms provide a powerful tool for segmenting customers and improving the effectiveness of marketing campaigns.
Real-World Example: Detecting Fraudulent Transactions with Support Vector Machines
Support vector machines (SVMs) are a powerful machine learning algorithm used for classification and regression tasks. In this section, we will explore how SVMs can be used to detect fraudulent transactions, a common application in the financial industry.
Imagine you are a data analyst for a bank looking to detect fraudulent transactions in real-time. You have collected data on historical transactions, including the transaction amount, time of day, location, and other relevant factors. Your goal is to build a model that can accurately detect fraudulent transactions and alert the bank’s fraud department.
SVMs can be used to classify transactions as either “fraudulent” or “non-fraudulent” based on the predictor variables. By finding the optimal boundary or hyperplane that separates the two classes, SVMs can provide a robust and accurate classification of transactions. For example, a transaction with an amount of $10,000 at 3:00 AM in a foreign location might be classified as “fraudulent,” while a transaction with an amount of $50 at 10:00 AM in the same location might be classified as “non-fraudulent.”
SVMs are particularly effective in high-dimensional spaces and can handle noisy data, making them well-suited for detecting fraudulent transactions. By using SVMs to classify transactions, you can improve the accuracy of fraud detection and reduce the risk of false positives or false negatives.
In summary, SVMs provide a powerful tool for detecting fraudulent transactions and improving the security of financial systems. By understanding the relationship between predictor variables and the outcome variable, you can make informed decisions and gain valuable insights into complex problems.

Real-World Example: Improving Image Recognition with Neural Networks
Neural networks are a type of machine learning algorithm inspired by the structure and function of the human brain. They are particularly effective in image recognition tasks, where they can learn to identify patterns and features in images with high accuracy. In this section, we will explore how neural networks can be used to improve image recognition and provide a real-world example of their application.
Imagine you are a computer vision engineer for a self-driving car company. Your goal is to build a model that can accurately recognize traffic signs, pedestrians, and other objects on the road. Neural networks can be used to learn the complex features and patterns in images, allowing you to build a robust and accurate model for image recognition.
Convolutional neural networks (CNNs) are a type of neural network specifically designed for image recognition tasks. They consist of multiple layers that learn to detect features in images, such as edges, shapes, and textures. By combining these features, CNNs can learn to recognize complex objects and patterns in images.
For example, a CNN might learn to detect edges in an image, then combine these edges to form shapes, and finally combine shapes to form objects, such as traffic signs or pedestrians. By learning to recognize these objects, the CNN can provide accurate and reliable image recognition, even in complex or noisy environments.
In summary, neural networks provide a powerful tool for improving image recognition and can be applied to a wide range of real-world problems. By learning to detect complex features and patterns in images, neural networks can provide accurate and reliable image recognition, even in challenging environments.
How to Choose the Right Machine Learning Algorithm: A Practical Guide
Choosing the right machine learning algorithm for a specific problem can be a challenging task, as there are many different algorithms to choose from, each with its own strengths and weaknesses. In this section, we will offer practical tips on how to choose the right machine learning algorithm for your problem, taking into account factors such as data size, data type, and the desired outcome.
First, consider the size and complexity of your data. If you have a large dataset with many features, you may want to consider using algorithms such as random forest or neural networks, which can handle high-dimensional data and learn complex patterns. On the other hand, if you have a small dataset with only a few features, you may want to consider using simpler algorithms such as linear or logistic regression.
Next, consider the type of data you are working with. If you are working with categorical data, you may want to consider using algorithms such as decision trees or random forest, which can handle categorical variables effectively. If you are working with numerical data, you may want to consider using algorithms such as linear regression or neural networks, which can handle numerical data well.
Finally, consider the desired outcome of your analysis. If you are looking to make predictions or forecasts, you may want to consider using algorithms such as linear regression or neural networks, which are well-suited for prediction tasks. If you are looking to classify data into categories, you may want to consider using algorithms such as decision trees or support vector machines, which are well-suited for classification tasks.
In summary, choosing the right machine learning algorithm for a specific problem requires careful consideration of factors such as data size, data type, and the desired outcome. By taking these factors into account, you can choose the right algorithm for your problem and improve the accuracy and reliability of your analysis.
.jpg)
Conclusion: The Power of Machine Learning Algorithms in Real-World Applications
Machine learning algorithms have become an essential tool in various industries, enabling businesses and organizations to make informed decisions, improve efficiency, and gain a competitive edge. By understanding the different types of machine learning algorithms and their applications, you can choose the right algorithm for your specific problem and achieve accurate and reliable results.
Throughout this article, we have explored various real-world examples of machine learning algorithms, including linear regression, decision trees, random forest, support vector machines, and neural networks. We have demonstrated how these algorithms can be used to predict housing prices, classify customer segments, detect fraudulent transactions, and improve image recognition.
Choosing the right machine learning algorithm for a specific problem requires careful consideration of factors such as data size, data type, and the desired outcome. By taking these factors into account, you can choose the right algorithm for your problem and improve the accuracy and reliability of your analysis.
In conclusion, machine learning algorithms provide a powerful tool for solving complex problems and making informed decisions. By exploring different algorithms and their use cases, you can unlock the potential of machine learning and harness its power to drive innovation and growth in your business or organization.