
An Overview of Prometheus and Its Role in Kubernetes Monitoring
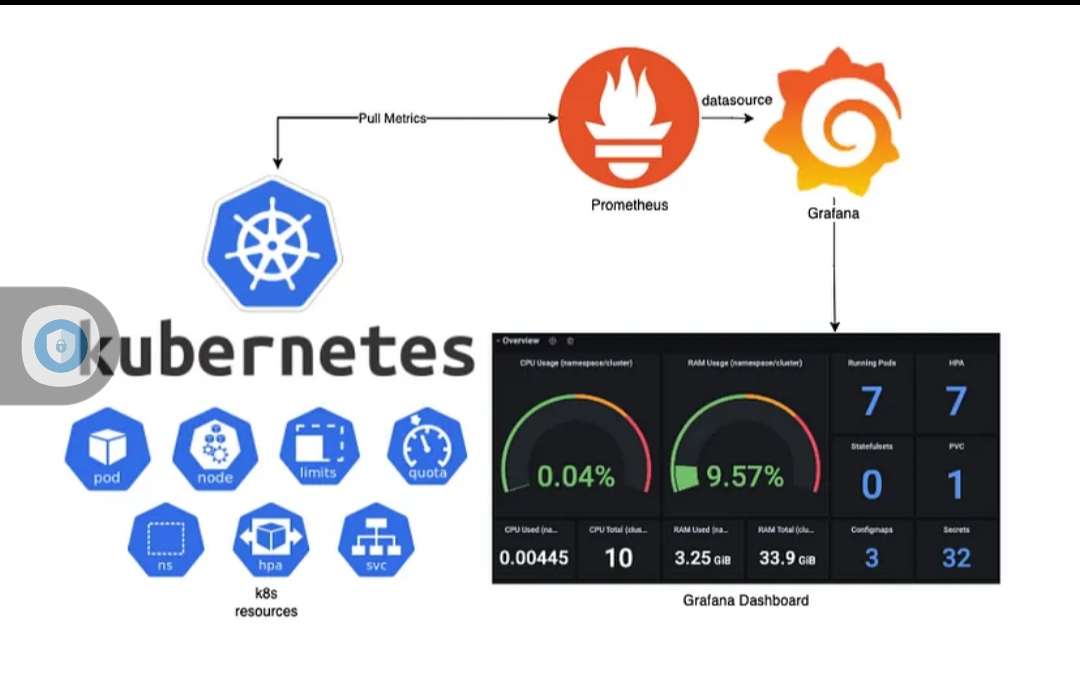
Prometheus is an open-source monitoring solution designed for containerized applications, making it an ideal choice for Kubernetes environments. The tool offers powerful features, including a flexible query language, real-time alerting, and service discovery. Integrating Prometheus with Kubernetes provides extensive monitoring capabilities for containerized applications, enabling users to track resource utilization, application performance, and system health.
The “kubernetes install prometheus” process involves deploying Prometheus within a Kubernetes cluster, allowing users to monitor resources and services effectively. By leveraging Prometheus’s capabilities, Kubernetes administrators can ensure optimal performance, identify bottlenecks, and address issues proactively. The integration of Prometheus and Kubernetes provides a robust monitoring platform tailored to the unique challenges of containerized applications.
Prerequisites: Preparing Your Kubernetes Cluster
Before installing Prometheus in your Kubernetes cluster, it is essential to prepare the environment by allocating necessary resources, configuring access control, and setting up network configurations. This section outlines the prerequisites for a successful “kubernetes install prometheus” process.
First, ensure that your Kubernetes cluster has sufficient resources to accommodate Prometheus and its associated components. Allocate adequate CPU, memory, and storage resources based on the scale and complexity of your monitored applications. Additionally, consider resource reservations and limits to prevent performance degradation due to resource contention.
Next, configure access control for Prometheus and its components. Implement role-based access control (RBAC) to manage user permissions and ensure that only authorized users can access and modify monitoring data. Utilize Kubernetes secrets or config maps to securely store sensitive information such as access tokens, API keys, and user credentials.
Finally, set up network configurations to enable communication between Prometheus, target applications, and other monitoring components. Configure service discovery mechanisms, such as DNS or environment variables, to automatically register and deregister target applications. Ensure that the Prometheus server and target applications can communicate over the network using appropriate ports and protocols.

Installing Prometheus Operator in Your Kubernetes Cluster
To install the Prometheus Operator in your Kubernetes cluster, you can use popular package managers such as Helm or Kops. This section provides a step-by-step guide for both methods, complete with code snippets and screenshots, to help you successfully “kubernetes install prometheus” and its related components.
Method 1: Installing Prometheus Operator Using Helm
Helm is a widely-used package manager for Kubernetes that simplifies the deployment and management of applications. To install the Prometheus Operator using Helm, follow these steps:
- Install Helm on your local machine or within the Kubernetes cluster.
- Add the Prometheus Operator Helm repository:
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts - Update your Helm repository:
helm repo update - Install the Prometheus Operator chart:
helm install my-prom-operator prometheus-community/kube-prometheus-stack
Method 2: Installing Prometheus Operator Using Kops
Kops is a Kubernetes operations tool that simplifies the deployment and management of Kubernetes clusters. To install the Prometheus Operator using Kops, follow these steps:
- Configure your Kops cluster as required.
- Create a custom Kubernetes manifest file for the Prometheus Operator.
- Apply the manifest file to your Kops cluster:
kops apply -f my-prom-operator-manifest.yaml
After completing either method, you should have a fully functional Prometheus Operator installed in your Kubernetes cluster, enabling you to deploy Prometheus and configure service monitoring for your containerized applications.

Deploying Prometheus and Configuring Service Monitoring
Once the Prometheus Operator is installed, you can deploy Prometheus and configure service monitoring for your Kubernetes resources. This section discusses the role of ServiceMonitors, PodMonitors, and PrometheusRules in monitoring Kubernetes resources and provides a step-by-step guide for configuring service monitoring.
ServiceMonitors
ServiceMonitors are custom resources that define how Prometheus should scrape targets within a Kubernetes cluster. They allow you to monitor services, pods, and endpoints by automatically discovering targets and configuring scrape jobs.
PodMonitors
PodMonitors are custom resources that monitor specific pods rather than services. They are useful for monitoring stateless applications or components that do not expose a service. PodMonitors can be used to monitor targets that require more granular control than ServiceMonitors provide.
PrometheusRules
PrometheusRules define recording and alerting rules for Prometheus. Recording rules allow you to precompute and store frequently used metrics, while alerting rules trigger alerts based on specific conditions. PrometheusRules help you create custom monitoring rules tailored to your application’s needs.
Step-by-Step Guide: Configuring Service Monitoring
- Create a ServiceMonitor, PodMonitor, or PrometheusRule manifest file for your Kubernetes resources.
- Apply the manifest file to your Kubernetes cluster:
kubectl apply -f my-monitoring-manifest.yaml - Verify that the new targets have been added to Prometheus by checking the Prometheus targets page.
By deploying Prometheus and configuring service monitoring, you can effectively monitor your Kubernetes resources and ensure optimal performance and availability.
Accessing and Visualizing Prometheus Data with Grafana
Prometheus provides a powerful query language and a flexible data model, but its visualization capabilities are limited. To create custom dashboards and visualize Prometheus data more effectively, you can integrate Prometheus with Grafana. This section explains how to access and visualize Prometheus data using Grafana, with a step-by-step guide on setting up Grafana, connecting it to Prometheus, and creating custom dashboards.
Step 1: Installing Grafana
To install Grafana, follow the official documentation for your target platform (Grafana Installation). For Kubernetes, you can use Helm or Kops to simplify the installation process.
Step 2: Connecting Grafana to Prometheus
After installing Grafana, you need to connect it to your Prometheus instance. To do this, follow these steps:
- Open Grafana and navigate to the “Add data source” page.
- Select “Prometheus” as the data source type.
- Enter the URL of your Prometheus server (e.g.,
http://prometheus-server:9090). - Save the data source configuration.
Step 3: Creating Custom Dashboards
With Grafana connected to Prometheus, you can create custom dashboards to visualize your monitoring data. To create a dashboard, follow these steps:
- Navigate to the Grafana dashboard page and click “Create”.
- Add panels to your dashboard using Prometheus queries.
- Customize the appearance and layout of your dashboard.
- Save and share your dashboard with other team members.
By visualizing Prometheus data with Grafana, you can gain deeper insights into your Kubernetes resources and ensure optimal performance and availability.

Alerts and Notifications: Setting Up Monitoring Alerts in Prometheus
Prometheus offers a powerful alerting system that allows you to define custom alert rules based on your monitoring data. This section discusses how to configure alerts and notifications in Prometheus, including creating alert rules, setting up Alertmanager, and configuring various notification channels.
Creating Alert Rules
To create alert rules in Prometheus, you need to define a PrometheusRule resource. This resource contains one or more alertRules sections, each of which defines a set of alert rules. Here’s an example of a simple alert rule that triggers when a pod’s CPU usage exceeds 80%:
{ "kind": "PrometheusRule", "apiVersion": "monitoring.coreos.com/v1", "metadata": { "name": "my-alert-rules" }, "spec": { "groups": [ { "name": "example.rules", "rules": [ { "alert": "HighCPUUsage", "expr": "sum(rate(container_cpu_usage_seconds_total{container!=""POD"",container!=""kube-state-metrics"",container!=""kubernetes-dashboard"",container!=""prometheus""}[5m])) by (pod_name) > 80", "for": "5m", "labels": { "severity": "critical" }, "annotations": { "summary": "High CPU usage in pod {{ $labels.pod_name }}" } } ] } ] } }Setting Up Alertmanager
Alertmanager is a separate component that handles alert routing, silencing, and inhibition. To set up Alertmanager, you need to create an Alertmanager resource in your Kubernetes cluster. Here’s an example of a simple Alertmanager configuration:
{ "kind": "Alertmanager", "apiVersion": "monitoring.coreos.com/v1", "metadata": { "name": "my-alertmanager" }, "spec": { "route": { "receiver": "team-X-mails" }, "receivers": [ { "name": "team-X-mails", "emailConfig": { "to": "[email protected]" } } ] } }Configuring Notification Channels
Prometheus supports various notification channels, including email, Slack, PagerDuty, and more. To configure a notification channel, you need to define a corresponding receiver in the Alertmanager resource. For example, to configure an email notification channel, you can use the following configuration:
{ "kind": "Alertmanager", "apiVersion": "monitoring.coreos.com/v1", "metadata": { "name": "my-alertmanager" }, "spec": { "route": { "receiver": "team-X-mails" }, "receivers": [ { "name": "team-X-mails", "emailConfig": { "to": "[email protected]", "from": "[email protected]" } } ] } }By setting up monitoring alerts in Prometheus, you can proactively identify and address issues in your Kubernetes cluster, ensuring optimal performance and availability.

Best Practices for Prometheus Monitoring in Kubernetes
Prometheus is a powerful monitoring solution for Kubernetes environments, but to get the most out of it, you need to follow best practices. This section shares some best practices for Prometheus monitoring in Kubernetes, including resource management, backup strategies, and security considerations.
Resource Management
To ensure optimal performance and resource utilization, you should consider the following resource management best practices:
- Monitor resource usage and set resource requests and limits for Prometheus components.
- Use horizontal pod autoscaling to scale Prometheus components based on resource usage and demand.
- Configure the Prometheus retention policy to balance data retention and storage requirements.
Backup Strategies
Regular backups are essential to ensure data durability and recoverability. Here are some backup strategies to consider:
- Schedule regular backups of Prometheus data using the built-in backup feature or a third-party tool.
- Store backups in a secure and durable storage solution, such as a cloud storage service or a network-attached storage device.
- Test backup and restore processes regularly to ensure data recoverability.
Security Considerations
Security is a critical aspect of any monitoring solution. Here are some security considerations for Prometheus monitoring in Kubernetes:
- Configure role-based access control (RBAC) to restrict access to Prometheus components and data.
- Use secure communication channels, such as HTTPS, to protect data in transit.
- Regularly update Prometheus components and dependencies to ensure security patches and bug fixes are applied.
By following these best practices, you can ensure a reliable and secure Prometheus monitoring solution for your Kubernetes environment.
Troubleshooting and Optimization: Addressing Common Challenges
Prometheus monitoring in Kubernetes can present several challenges, including performance optimization, data discrepancies, and cluster upgrades. This section provides tips on addressing these common challenges and offers troubleshooting techniques to ensure a smooth monitoring experience.
Optimizing Performance
Prometheus can consume significant resources when monitoring a large number of targets. To optimize performance, consider the following:
- Monitor Prometheus performance metrics and adjust resource requests and limits accordingly.
- Use targeted label selectors to reduce the number of scraped targets.
- Configure Prometheus to use a push gateway for short-lived targets or high-churn services.
Resolving Data Discrepancies
Data discrepancies can occur due to various reasons, such as misconfigured scrape jobs or network issues. To resolve data discrepancies, consider the following:
- Verify scrape job configurations and ensure they are correctly targeting the desired endpoints.
- Check network connectivity and firewall rules to ensure Prometheus can communicate with target endpoints.
- Review Prometheus logs and metrics to identify any issues or anomalies.
Handling Cluster Upgrades
Upgrading a Kubernetes cluster with Prometheus monitoring can be challenging, especially when dealing with multiple Prometheus instances and components. To handle cluster upgrades, consider the following:
- Plan the upgrade sequence and ensure it aligns with Kubernetes best practices.
- Test the upgrade process in a staging environment before applying it to production.
- Monitor Prometheus and Kubernetes metrics during and after the upgrade to ensure a smooth transition.
By following these best practices and troubleshooting techniques, you can ensure a reliable and effective Prometheus monitoring solution for your Kubernetes environment.
