
Understanding Kubernetes Node Affinity
Kubernetes node affinity plays a crucial role in optimizing deployments. It allows administrators to schedule pods onto specific nodes based on labels or other node attributes. This capability is essential for efficient resource allocation. By strategically placing pods, organizations can meet application requirements. These requirements might include access to specialized hardware, such as GPUs. Node affinity also ensures high availability and minimizes potential conflicts between applications. The core concepts involved in k8s node affinity include nodeSelector, affinity, and anti-affinity. These mechanisms offer varying levels of control over pod placement. This article will explore each concept in detail, providing practical examples and best practices for implementation. Understanding k8s node affinity is key to building robust and efficient Kubernetes deployments. Efficient resource utilization is a key benefit of implementing k8s node affinity correctly.
Proper implementation of k8s node affinity improves application performance. Consider scenarios where applications need specific hardware resources. A database requiring high-speed storage might benefit from placement on a node with NVMe drives. Similarly, machine learning applications needing GPUs should be scheduled on nodes equipped with them. Node affinity ensures these requirements are met. It avoids scheduling conflicts and enhances application reliability. Resource optimization is greatly improved with the proper application of k8s node affinity. Understanding and utilizing node affinity is a core skill for any Kubernetes administrator.
The strategic use of k8s node affinity enhances overall system resilience. By spreading pods across nodes based on specific criteria, administrators can reduce the impact of node failures. Anti-affinity, a key component of k8s node affinity, is particularly useful for preventing single points of failure. This technique ensures that critical applications are not concentrated on a single node. The robust design achieved through proper k8s node affinity implementation safeguards against outages. In summary, k8s node affinity is a fundamental aspect of effective Kubernetes cluster management. It’s crucial for both performance and stability.
Node Selection Strategies with nodeSelector
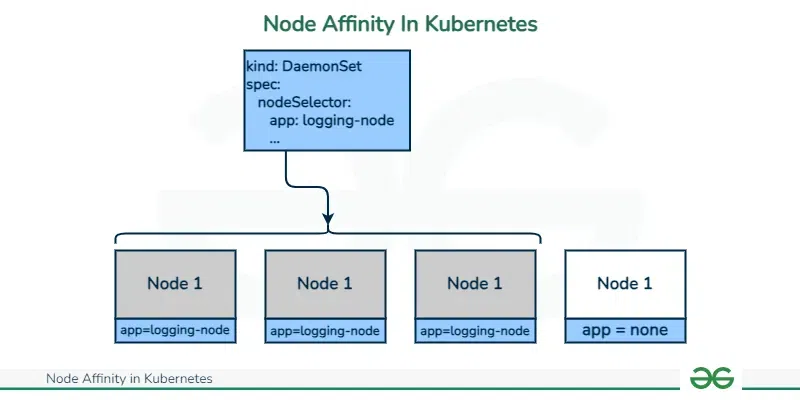
The nodeSelector mechanism offers a straightforward approach to k8s node affinity. It allows scheduling pods onto nodes possessing specific labels. This simple yet effective technique is ideal for scenarios requiring basic node selection. For example, you might label nodes with disktype: ssd and then use nodeSelector to ensure pods requiring high-speed storage are scheduled only on these nodes. This approach simplifies deployment for applications with basic hardware requirements. Using nodeSelector for k8s node affinity ensures predictable pod placement based on readily available node labels. A pod specification might look like this: apiVersion: v1 kind: Pod metadata: name: my-pod spec: containers: - name: my-container image: my-image nodeSelector: disktype: ssd. This YAML snippet directs the scheduler to place my-pod only on nodes labeled with disktype: ssd. This exemplifies the power and simplicity of nodeSelector in managing k8s node affinity.
However, nodeSelector has limitations. It only considers the presence or absence of labels. It doesn’t handle more complex scenarios, such as prioritizing pod placement or considering the current node load. More sophisticated k8s node affinity strategies, such as those involving pod anti-affinity, are beyond its capabilities. For example, you cannot use nodeSelector to ensure that two pods of the same application never run on the same node. For more complex pod placement needs, Kubernetes offers more advanced affinity mechanisms which are covered in subsequent sections. These limitations highlight the need for more advanced k8s node affinity techniques when dealing with intricate deployment requirements.
Understanding these limitations is crucial for effective deployment. While nodeSelector provides a convenient method for simple k8s node affinity, its simplicity comes at the cost of reduced flexibility. Choosing the right tool for the job ensures efficient resource management and application performance. Complex scheduling scenarios demand the more powerful affinity and anti-affinity mechanisms discussed later. Remember that using k8s node affinity effectively hinges on carefully selecting the appropriate technique based on your specific needs and application requirements. For straightforward cases, nodeSelector offers a clear, easy-to-implement solution for k8s node affinity. However, for more complex deployment environments, exploring the capabilities of the affinity and anti-affinity features within the Kubernetes scheduler is advisable.
 nodeSelector” title=”k8s node affinity” style=”max-width: 100%; height: auto;” src=”https://media.geeksforgeeks.org/wp-content/uploads/20240506110659/Node-Affinity-In-Kubernetes.webp” />
nodeSelector” title=”k8s node affinity” style=”max-width: 100%; height: auto;” src=”https://media.geeksforgeeks.org/wp-content/uploads/20240506110659/Node-Affinity-In-Kubernetes.webp” />Advanced Pod Placement with `affinity`
Kubernetes node affinity offers powerful mechanisms for controlling pod placement. `nodeSelector` provides basic functionality, but `affinity` offers significantly more control for complex scheduling needs. `Affinity` allows for more nuanced rules, going beyond simple label matching to incorporate more sophisticated logic. This is crucial for optimizing resource utilization and ensuring application requirements are met. Mastering k8s node affinity, specifically the `affinity` mechanism, is essential for advanced Kubernetes deployments.
A key distinction within `affinity` lies in the `requiredDuringSchedulingIgnoredDuringExecution` and `preferredDuringSchedulingIgnoredDuringExecution` fields. `requiredDuringSchedulingIgnoredDuringExecution` mandates that a pod only schedules on nodes matching the specified criteria. Failure to meet these criteria prevents pod scheduling. `preferredDuringSchedulingIgnoredDuringExecution` expresses preferences, influencing the scheduler’s decisions but not blocking scheduling. The scheduler attempts to meet these preferences, but it will still schedule the pod if no suitable nodes meet the preference criteria. This flexibility is vital for balancing strict requirements with potential scheduling constraints. Effective use of k8s node affinity hinges on understanding this difference.
Both `matchExpressions` and `matchLabels` operate within the `affinity` section, defining matching criteria. `matchLabels` performs exact label matching. `matchExpressions` offers more complex matching, using operators like `In`, `NotIn`, `Exists`, and `DoesNotExist` to evaluate label values. Consider a scenario where pods need GPUs. `matchLabels` could target nodes labeled `gpu:true`. `matchExpressions` could accommodate more complex scenarios, like ensuring pods only schedule on nodes with at least two GPUs, using an expression evaluating a numeric label representing available GPU counts. YAML configurations clearly illustrate these capabilities. Understanding these options is key to implementing effective k8s node affinity strategies for even the most demanding application deployments. Using k8s node affinity effectively improves resource allocation and ensures smooth operations.
Preventing Conflicts: Understanding Kubernetes Anti-affinity
Kubernetes anti-affinity is a powerful mechanism within k8s node affinity that prevents pods from being scheduled on the same node. This is crucial for ensuring high availability and preventing resource contention. By strategically employing anti-affinity, administrators can distribute workloads effectively, mitigating the risks associated with single points of failure. This approach is especially valuable for stateful applications where data replication or consistency is paramount. Imagine a database cluster: anti-affinity ensures that database replicas reside on different nodes, enhancing resilience against node failures. If one node goes down, other replicas remain accessible, ensuring continuous operation. Properly configured k8s node affinity, incorporating anti-affinity, is a critical element of robust application deployments.
Implementing anti-affinity involves defining rules within the pod specification’s `affinity` section. The `podAntiAffinity` field allows for specifying the constraints. Similar to affinity, `requiredDuringSchedulingIgnoredDuringExecution` and `preferredDuringSchedulingIgnoredDuringExecution` options exist. The former strictly enforces the anti-affinity rule during scheduling, while the latter represents a preference, allowing for scheduling flexibility if strict adherence is impossible. `matchExpressions` and `matchLabels` enable precise targeting of pods that should be kept apart. Consider a scenario with resource-intensive pods. Anti-affinity ensures these pods are distributed across nodes, preventing resource exhaustion on a single node. This leads to improved overall cluster performance and prevents individual applications from negatively impacting each other. Effective use of k8s node affinity, including anti-affinity rules, contributes directly to a well-balanced and resilient cluster.
YAML configurations illustrate anti-affinity’s practical application. For example, defining `podAntiAffinity` with a `labelSelector` targeting specific application labels ensures that pods sharing the same application label are not co-located. This is commonly used in microservices architecture, where multiple instances of a service should be spread across nodes. Another example involves deploying stateful sets: anti-affinity helps prevent replicas of a stateful application from residing on the same node, further enhancing high availability and reducing the risk of simultaneous failures. Mastering k8s node affinity, particularly anti-affinity, significantly improves cluster resource management and application stability. Careful consideration of these rules during deployment is critical for achieving optimal cluster performance and application resilience. Understanding and correctly applying k8s node affinity principles greatly impacts the success of any Kubernetes deployment.

How to Implement Kubernetes Node Affinity in Your Deployments
Implementing k8s node affinity involves several key steps. First, define labels on your Kubernetes nodes. These labels act as identifiers, allowing you to target specific nodes for pod placement. Use descriptive labels that clearly indicate the node’s characteristics, such as hardware capabilities (e.g., gpu: true for nodes with GPUs) or roles (e.g., role: database for nodes dedicated to database workloads). Apply these labels using kubectl label nodes. Remember to choose meaningful and consistent label names for effective management of your k8s node affinity rules.
Next, create YAML files specifying the node affinity rules for your pods. Within the pod specification, define the affinity section. This section contains the rules determining where pods can be scheduled. For example, to schedule a pod only on nodes with the label gpu: true, use a nodeSelector. If more complex rules are needed, use the affinity field with requiredDuringSchedulingIgnoredDuringExecution or preferredDuringSchedulingIgnoredDuringExecution to express preferences or hard requirements. These settings control the strictness of the affinity rules. Remember to test your YAML files thoroughly before deployment to avoid unexpected behavior. Efficient k8s node affinity implementation requires careful planning and precise YAML configuration.
Finally, deploy your pods using kubectl apply -f . After deployment, verify the pod placements using kubectl get pods -o wide. This command shows where each pod is scheduled and the labels on the underlying nodes. This confirms if k8s node affinity is working as expected. Troubleshooting common errors might involve checking node labels, verifying the YAML syntax, and ensuring the labels match the selectors. Careful monitoring of resource usage and application performance post-deployment can inform iterative refinements to your k8s node affinity strategy. Observing pod scheduling and resource utilization data helps optimize pod placement and maintain application health. Consistent monitoring and adjustment are crucial for effective k8s node affinity management.
Best Practices for Kubernetes Node Affinity
Effective k8s node affinity implementation hinges on several best practices. Firstly, establish a clear and consistent naming convention for node labels. Using descriptive and easily understandable labels improves maintainability and reduces confusion. This helps in managing k8s node affinity rules effectively and prevents conflicts. Avoid overly generic labels, opting for specific identifiers related to hardware resources or software configurations. Careful label management is crucial for successful k8s node affinity.
Secondly, avoid overly restrictive k8s node affinity rules. Overly specific rules can limit pod scheduling flexibility, potentially leading to scheduling failures. Strive for a balance between precise targeting and sufficient flexibility. Analyze resource needs carefully. This ensures the pods can be scheduled successfully, and it prevents scheduling bottlenecks. Monitoring resource utilization and adjusting affinity rules helps prevent scheduling issues. Regular review ensures optimal resource allocation.
Thirdly, ensure node labels accurately reflect application requirements. Align your node labels with the specific needs of your applications. This guarantees that k8s node affinity functions correctly. This includes hardware capabilities like GPU availability or specific software packages. Using k8s node affinity effectively requires close coordination between application requirements and node labeling. Regularly review your k8s node affinity configurations. This ensures that they remain aligned with evolving application needs and resource availability. Proactive monitoring and adjustment are key to maintaining efficient resource utilization and optimal application performance. Properly implemented k8s node affinity significantly improves overall cluster efficiency.

Advanced Affinity Techniques and Considerations for k8s Node Affinity
Beyond the fundamental `nodeSelector` and `affinity` mechanisms, Kubernetes offers more sophisticated techniques for controlling pod placement. `podTopologySpreadConstraints` provide a powerful way to distribute pods across multiple failure domains. This ensures high availability by preventing concentrated deployments within a single zone or region. By specifying constraints based on topology keys like “topology.kubernetes.io/zone” or “topology.kubernetes.io/region”, administrators can achieve optimal resilience. Effective use of `podTopologySpreadConstraints` significantly enhances the robustness of applications deployed using k8s node affinity.
Understanding the interaction between k8s node affinity and pod eviction is crucial. Node affinity rules influence which nodes a pod can be scheduled on. However, events like node resource pressure or maintenance can trigger pod evictions, even if those pods meet affinity criteria. Resource management strategies should therefore consider both affinity rules and potential eviction scenarios. Overly restrictive k8s node affinity rules can exacerbate scheduling challenges during resource contention. Careful balancing is needed to ensure optimal resource utilization without compromising application availability. Monitoring resource usage and adapting affinity rules proactively remains essential for efficient cluster management. Careful planning and monitoring will make the implementation of k8s node affinity a success.
Another important consideration is the potential impact of k8s node affinity on overall resource management. While node affinity improves resource allocation for specific applications, it can potentially lead to resource fragmentation if not carefully planned. Pods with stringent affinity rules may occupy nodes less efficiently, leaving some resources unused. This can be mitigated by thoughtful label management, careful selection of affinity rules, and ongoing monitoring of resource utilization. Effective resource management necessitates a holistic approach that accounts for both the benefits and potential drawbacks of k8s node affinity. The advantages of strategic use of k8s node affinity in improving application performance and high availability outweigh the potential challenges when implemented correctly. Continuous monitoring and fine-tuning of k8s node affinity configurations are vital for optimal cluster performance.
Real-World Examples and Use Cases of k8s Node Affinity
Consider a scenario involving a database application. This application requires high performance and low latency. Using k8s node affinity, database pods can be scheduled on nodes with high-speed SSDs and ample memory. This ensures optimal performance and prevents contention with other resource-intensive applications. Proper k8s node affinity configuration drastically improves the database’s response times and overall user experience. The intelligent placement of pods through k8s node affinity is key to success here.
Another example involves deploying a machine learning application requiring GPU access. By leveraging k8s node affinity, the pods are strategically scheduled only onto nodes equipped with GPUs. This significantly accelerates the training process and reduces the overall job completion time. Without k8s node affinity, these GPU-intensive pods might be placed on nodes lacking the necessary hardware, rendering the application unusable. The application’s success hinges on intelligent resource allocation, achievable through effective k8s node affinity.
In a large-scale web application deployment, k8s node affinity plays a crucial role in maintaining high availability. By applying anti-affinity rules, pods of the same application are prevented from running on the same node. This ensures that if one node fails, the entire application remains operational. This enhances resilience and ensures continuous service even in the event of hardware failures. Effective k8s node affinity significantly boosts the application’s robustness and fault tolerance. The strategic use of k8s node affinity ensures high availability and prevents single points of failure. This approach enhances the application’s resilience, a key aspect of modern infrastructure design. K8s node affinity’s role in distributing application workload across available resources ensures high availability and efficient resource utilization. Therefore, a well-defined k8s node affinity strategy is crucial for successful large-scale deployment.