
Introduction to Jupyter Notebook: A Powerful Open-Source Tool
Jupyter Notebook is a popular open-source web application that has gained significant attention in the data science community. It is an interactive computing environment that enables users to create and share documents that contain live code, equations, visualizations, and narrative text. This tutorial guide will provide a comprehensive overview of Jupyter Notebook, including its primary uses, benefits, and best practices for data analysis, machine learning, and scientific computing. Jupyter Notebook is an excellent tool for data analysis because it allows users to combine code, visualizations, and text in a single document. This feature makes it easy to create reproducible research, where others can replicate and build upon the results of a study. Additionally, Jupyter Notebook supports multiple programming languages, including Python, R, and Julia, making it a versatile tool for various data science tasks.
Machine learning is another area where Jupyter Notebook excels. It provides an interactive environment for experimenting with different machine learning algorithms, visualizing the results, and fine-tuning the models. Jupyter Notebook also supports the use of popular machine learning libraries such as scikit-learn, TensorFlow, and PyTorch, enabling users to build sophisticated machine learning models.
In scientific computing, Jupyter Notebook provides an interactive platform for exploring scientific data, performing simulations, and visualizing the results. It supports the use of popular scientific computing libraries such as NumPy, SciPy, and Matplotlib, enabling users to perform complex scientific computations with ease.
In summary, Jupyter Notebook is a powerful open-source tool that provides an interactive computing environment for data analysis, machine learning, and scientific computing. Its ability to combine code, visualizations, and text in a single document makes it an excellent tool for reproducible research, experimentation, and collaboration. In the following sections, we will provide a step-by-step guide on how to install and set up Jupyter Notebook, navigate its interface, create and manage documents, and use its various features for data analysis, machine learning, and scientific computing.

Getting Started with Jupyter Notebook: Installation and Setup
Jupyter Notebook is a free and open-source web application that allows you to create and share documents that contain live code, equations, visualizations, and narrative text. This section will provide a step-by-step guide on how to install Jupyter Notebook on various operating systems, including tips on selecting the right environment and configuration options. To get started with Jupyter Notebook, you need to have Python installed on your computer. You can download the latest version of Python from the official website (https://www.python.org/downloads/). Once you have installed Python, you can install Jupyter Notebook using pip, the Python package installer.
On Windows, you can install Jupyter Notebook using the following command in the command prompt:
pip install notebookOn MacOS, you can install Jupyter Notebook using the following command in the terminal:
pip3 install notebookOn Linux, you can install Jupyter Notebook using the following command in the terminal:
sudo pip3 install notebookOnce you have installed Jupyter Notebook, you can start the application by typing the following command in the command prompt or terminal:
jupyter notebook This command will start the Jupyter Notebook application and open a web browser window that displays the Jupyter Notebook dashboard. The dashboard shows a list of all the notebooks and directories in the current working directory.
When installing Jupyter Notebook, it is essential to select the right environment and configuration options. If you are using Python for data science or machine learning, you may want to install Jupyter Notebook in a virtual environment. A virtual environment is a self-contained Python environment that allows you to install packages and dependencies without affecting the global Python installation.
To create a virtual environment, you can use the following command in the command prompt or terminal:
python -m venv myenvThis command will create a new virtual environment named “myenv” in the current working directory. To activate the virtual environment, you can use the following command:
source myenv/bin/activate Once you have activated the virtual environment, you can install Jupyter Notebook using pip.
In summary, installing Jupyter Notebook is a straightforward process that involves installing Python and using pip to install Jupyter Notebook. When installing Jupyter Notebook, it is essential to select the right environment and configuration options, especially if you are using Python for data science or machine learning. By following the steps outlined in this section, you can get started with Jupyter Notebook and begin creating and sharing documents that contain live code, equations, visualizations, and narrative text.
Navigating the Jupyter Notebook Interface: A User-Friendly Experience
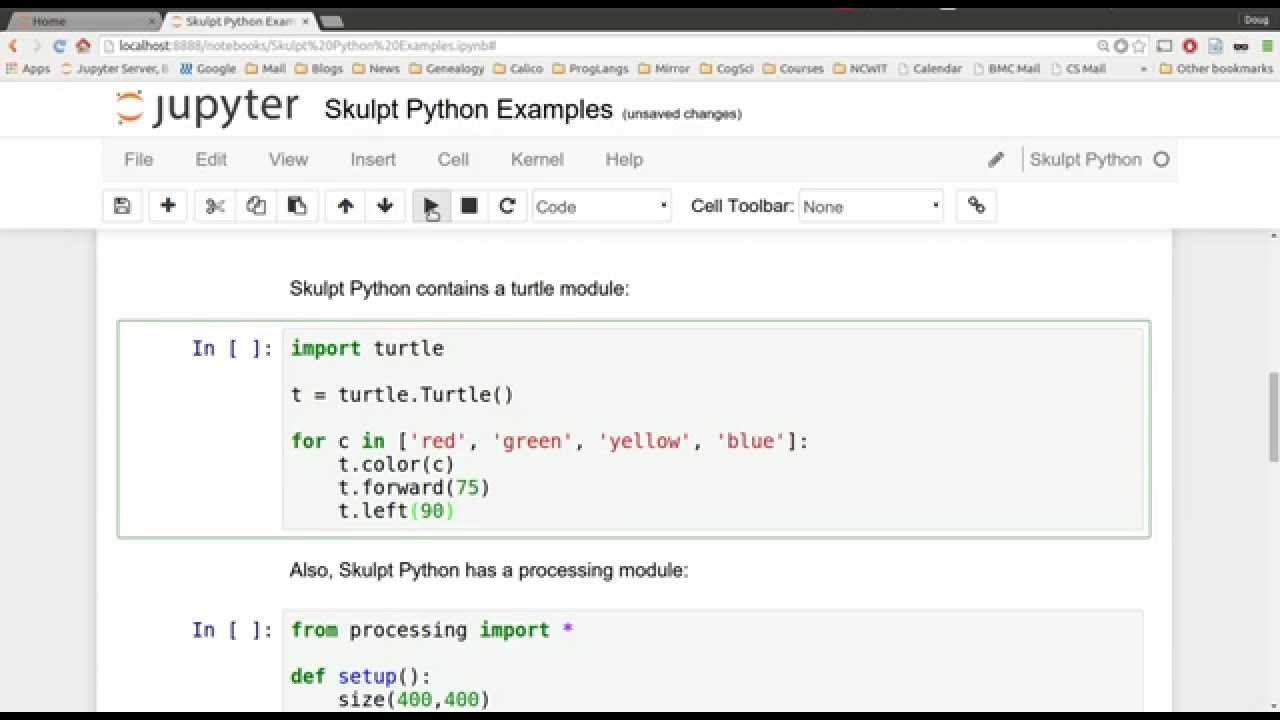
Jupyter Notebook provides a user-friendly interface that allows you to create and manage documents, run code, and visualize data. This section will explain the different components of the Jupyter Notebook interface, such as the dashboard, notebooks, and terminals, and how to interact with them effectively. The Jupyter Notebook interface consists of two main components: the dashboard and the notebook. The dashboard provides an overview of all the notebooks and directories in the current working directory. From the dashboard, you can create new notebooks, open existing ones, and manage your files.
To create a new notebook, click on the “New” button in the top right corner of the dashboard. This will open a new tab with a new untitled notebook. The notebook consists of cells, which can be used to enter and run code, markdown, or raw text.
To run a cell, click on it to select it, and then press the “Shift” and “Enter” keys simultaneously. This will run the code in the cell and display the output below it. You can also use the “Run” menu or the play button in the toolbar to run the cell.
The Jupyter Notebook interface also includes a terminal, which can be accessed by clicking on the “Terminal” button in the dashboard. The terminal allows you to run command-line commands, such as navigating directories, installing packages, and running scripts.
To interact with the Jupyter Notebook interface effectively, it is essential to understand the different components and how to use them. The dashboard provides an overview of your files and allows you to create and manage notebooks. The notebook consists of cells, which can be used to enter and run code, markdown, or raw text. The terminal allows you to run command-line commands.
When working with Jupyter Notebook, it is also essential to follow best practices for organizing and sharing your documents. This includes using descriptive names for your notebooks, using version control to track changes, and sharing your notebooks with others using collaboration tools.
In summary, the Jupyter Notebook interface provides a user-friendly experience for creating and managing documents, running code, and visualizing data. By understanding the different components of the interface and following best practices for organizing and sharing your documents, you can make the most of this powerful open-source tool.
Creating and Managing Jupyter Notebook Documents: A Practical Approach
Jupyter Notebook provides a flexible and user-friendly environment for creating and managing documents that contain live code, equations, visualizations, and narrative text. This section will describe how to create, save, and organize Jupyter Notebook documents, including best practices for naming conventions, version control, and sharing with others. To create a new Jupyter Notebook document, you can use the Jupyter Notebook interface or the command line. To create a new document using the interface, click on the “New” button in the top right corner of the dashboard and select “Notebook – Python 3” (or any other kernel you prefer). This will open a new tab with a new untitled notebook.
To save the notebook, click on the “Save” button in the top toolbar or use the “File” > “Save and Checkpoint” menu option. You can also use the keyboard shortcut “Ctrl + S” to save the notebook. It is a good practice to save the notebook frequently to avoid losing any work.
Jupyter Notebook documents are saved as JSON files with a “.ipynb” extension. The JSON format allows Jupyter Notebook to store the notebook’s content, including the code cells, markdown cells, and output.
To organize Jupyter Notebook documents, you can use directories and subdirectories. You can create a new directory by clicking on the “New” button in the dashboard and selecting “Folder”. You can then move notebooks between directories by dragging and dropping them.
When naming Jupyter Notebook documents, it is essential to use descriptive and meaningful names that accurately reflect the notebook’s content. This will make it easier to find and manage your notebooks.
Jupyter Notebook also supports version control using Git. This allows you to track changes to your notebooks, collaborate with others, and maintain a history of your work. To use Git with Jupyter Notebook, you need to install the Jupyter Notebook Git extension and configure your Git settings.
When sharing Jupyter Notebook documents with others, it is essential to consider the security and access controls. You can share notebooks using a variety of methods, including email, cloud storage services, or version control systems. When sharing notebooks, it is a good practice to use a naming convention that reflects the notebook’s purpose, audience, and version.
In summary, Jupyter Notebook provides a flexible and user-friendly environment for creating and managing documents that contain live code, equations, visualizations, and narrative text. By following best practices for naming conventions, version control, and sharing with梦幻西游3游戏中的捕鱼达人others, you can create engaging and informative documents that are easy to manage and share.

How to Use Jupyter Notebook Cells: Markdown, Code, and Output
Jupyter Notebook provides a flexible and user-friendly environment for creating and sharing documents that contain live code, equations, visualizations, and narrative text. One of the key features of Jupyter Notebook is the ability to use different types of cells, including Markdown, Code, and Output cells. In this section, we will discuss the different types of Jupyter Notebook cells, their purposes, and how to use them to create engaging and informative documents.
Markdown Cells
Markdown cells allow you to add formatted text, images, links, and other multimedia to your Jupyter Notebook documents. Markdown is a lightweight markup language that is easy to learn and use. With Markdown, you can create headings, lists, tables, code blocks, and other formatted text without having to use complex HTML syntax. To create a Markdown cell, select “Markdown” from the “Cell” > “Cell Type” menu. You can then type or paste your Markdown-formatted text into the cell. To format your text, you can use the Markdown syntax, which includes special characters such as “#” for headings, “*” for lists, and “`” for code blocks.
Here are some examples of how to use Markdown in Jupyter Notebook:
- To create a heading, use the “#” symbol followed by a space. For example, “# Heading 1” will create a level 1 heading.
- To create a list, use the “*” symbol followed by a space. For example, “* Item 1” will create a bullet point.
- To create a code block, use the “`” symbol followed by a space. For example, “`code`” will create a code block.
Code Cells
Code cells allow you to enter and run Python code in Jupyter Notebook. You can use code cells to perform data analysis, machine learning, scientific computing, and other tasks. To create a code cell, select “Code” from the “Cell” > “Cell Type” menu. You can then type or paste your Python code into the cell. To run the code in a cell, you can use the “Run” button in the toolbar, the “Shift + Enter” keyboard shortcut, or the “Cell” > “Run Cells” menu option. When you run a code cell, Jupyter Notebook will execute the code and display the output in the cell below it.
Here are some tips for using code cells in Jupyter Notebook:
- Use descriptive variable names and comments to make your code more readable and understandable.
- Use the “print()” function to display output in the console.
- Use the “%%time” and “%%timeit” magic commands to measure the performance of your code.
Output Cells
Output cells display the output of the code in the previous cell. The output can include text, images, tables, and other multimedia. You can also use output cells to display the results of data visualization and machine learning models. To view the output of a code cell, simply run the cell using the “Run” button, the “Shift + Enter” keyboard shortcut, or the “Cell” > “Run Cells” menu option. The output will be displayed in the cell below the code cell.
Here are some tips for using output cells in Jupyter Notebook:
- Use the “display()” function to display output in a more readable format.
- Use the “matplotlib” library to create interactive data visualizations.
- Use the “seaborn” library to create statistical data visualizations.
In summary, Jupyter Notebook provides a flexible and user-friendly environment for creating and sharing documents that contain live code, equations, visualizations, and narrative text. By using the different types of Jupyter Notebook cells (Markdown, Code, and Output), you can create engaging and informative documents that are easy to read, understand, and share.
Working with Data in Jupyter Notebook: Importing, Manipulating, and Visualizing
Jupyter Notebook is a powerful tool for data analysis, machine learning, and scientific computing. One of the primary uses of Jupyter Notebook is working with data, including importing, manipulating, and visualizing data. In this section, we will discuss how to use Jupyter Notebook to work with data using popular libraries such as Pandas, NumPy, and Matplotlib. We will also provide tips on data cleaning, transformation, and exploration.
Importing Data
To work with data in Jupyter Notebook, you first need to import the data into your notebook. Jupyter Notebook supports various file formats, including CSV, Excel, JSON, and SQL. To import data into Jupyter Notebook, you can use the Pandas library, which provides functions for reading and writing data in various file formats. Here are some examples of how to import data into Jupyter Notebook using Pandas:
- To import a CSV file, use the “read\_csv()” function. For example, “import pandas as pd” followed by “df = pd.read\_csv(‘data.csv’)” will import a CSV file named “data.csv” into a Pandas DataFrame named “df”.
- To import an Excel file, use the “read\_excel()” function. For example, “import pandas as pd” followed by “df = pd.read\_excel(‘data.xlsx’, sheet\_name=’Sheet1′)” will import the first sheet of an Excel file named “data.xlsx” into a Pandas DataFrame named “df”.
- To import a JSON file, use the “read\_json()” function. For example, “import pandas as pd” followed by “df = pd.read\_json(‘data.json’)” will import a JSON file named “data.json” into a Pandas DataFrame named “df”.
- To import data from a SQL database, use the “read\_sql\_query()” or “read\_sql\_table()” functions. For example, “import pandas as pd” followed by “import sqlite3” and “conn = sqlite3.connect(‘database.db’)” and “df = pd.read\_sql\_query(‘SELECT * FROM table_name’, conn)” will import data from a SQL database named “database.db” into a Pandas DataFrame named “df”.
Manipulating Data
Once you have imported data into Jupyter Notebook, you can use Pandas to manipulate the data. Pandas provides various functions for cleaning, transforming, and exploring data, including functions for filtering, sorting, grouping, merging, and reshaping data. Here are some examples of how to manipulate data in Jupyter Notebook using Pandas:
- To filter data, use the “query()” or “loc[]” or “iloc[]” functions. For example, “df.query(‘column\_name == value’)” or “df.loc[df[‘column\_name’] == value, :]” or “df.iloc[row\_index, :]” will filter the data based on a condition or index.
- To sort data, use the “sort\_values()” function. For example, “df.sort\_values(by=’column\_name’, ascending=False)” will sort the data based on a column in descending order.
- To group data, use the “groupby()” function. For example, “df.groupby(‘column\_name’).mean()” will group the data based on a column and calculate the mean of the other columns.
- To merge data, use the “merge()” function. For example, “merged\_df = pd.merge(df1, df2, on=’common\_column’, how=’inner’)” will merge two DataFrames (df1 and df2) based on a common column using an inner join.
- To reshape data, use the “pivot\_table()” or “melt()” functions. For example, “pd.pivot\_table(df, values=’column\_name’, index=’column\_name1′, columns=’column\_name2′, aggfunc=’mean’)” will create a pivot table based on two columns and an aggregation function.
Visualizing Data
In addition to manipulating data, Jupyter Notebook also provides tools for visualizing data. You can use the Matplotlib library to create various types of plots, charts, and graphs in Jupyter Notebook. Here are some examples of how to visualize data in Jupyter Notebook using Matplotlib:
- To create a line plot, use the “plot()” function. For example, “import matplotlib.pyplot as plt” followed by “plt.plot(x, y)” will create a line plot of the x and y variables.
- To create a scatter plot, use the “scatter()” function. For example, “import matplotlib.pyplot as plt” followed by “plt.scatter(x, y)” will create a scatter plot of the x and y variables.
- To create a bar plot, use the “bar()” function. For example, “import matplotlib.pyplot as plt” followed by “plt.bar(x, y)” will create a bar plot of the x and y variables.
- To create a histogram, use the “hist()” function. For example, “import matplotlib.pyplot as plt” followed by “plt.hist(x)” will create a histogram of the x variable.
- To create a box plot, use the “boxplot()” function. For example, “import matplotlib.pyplot as plt” followed by “plt.boxplot(x)” will create a box plot of the x variable.
In summary, Jupyter Notebook provides a powerful environment for working with data, including importing, manipulating, and visualizing data. By using popular libraries such as Pandas,

Running Code in Jupyter Notebook: Debugging, Testing, and Profiling
Jupyter Notebook is an excellent tool for data analysis, machine learning, and scientific computing, as it allows users to write and run code in a user-friendly environment. However, as with any programming tool, running code in Jupyter Notebook can sometimes result in errors or unexpected behavior. In this section, we will discuss how to debug, test, and profile code in Jupyter Notebook effectively.
Debugging Code in Jupyter Notebook
Debugging is the process of identifying and fixing errors in code. Jupyter Notebook provides several tools for debugging code, including the following:
- Print Statements: One of the simplest ways to debug code in Jupyter Notebook is to use print statements to output the values of variables at different points in the code. This can help users identify where the code is going wrong and what values are being assigned to variables.
- Interactive Debugging: Jupyter Notebook also supports interactive debugging using the Python debugger (pdb) module. To use pdb, users can insert the following code at the point where they want to start debugging:
import pdb; pdb.set_trace(). This will open an interactive debugger where users can step through the code, inspect variables, and run commands.
Testing Code in Jupyter Notebook
Testing is the process of verifying that code works as expected. Jupyter Notebook provides several tools for testing code, including the following:
- Unit Testing: Unit testing is the practice of testing individual units of code (e.g., functions or methods) to ensure that they work as expected. Jupyter Notebook supports unit testing using the Python unittest module. To use unittest, users can create a separate test file that imports the code to be tested and defines test cases using the unittest.TestCase class.
- Doctest: Doctest is a module that allows users to include test cases in the documentation of functions or methods. To use doctest, users can include examples of how the code should work in the docstrings of functions or methods, and then use the doctest.testmod() function to run the tests.
Profiling Code in Jupyter Notebook
Profiling is the process of measuring the performance of code to identify bottlenecks or inefficiencies. Jupyter Notebook provides several tools for profiling code, including the following:
- Line Profiler: Line profiler is a module that allows users to measure the time taken to execute individual lines of code. To use line profiler, users can install the module using pip and then use the @profile decorator to profile individual functions.
- Memory Profiler: Memory profiler is a module that allows users to measure the memory usage of code. To use memory profiler, users can install the module using pip and then use the @profile decorator to profile individual functions.
In addition to these tools, Jupyter Notebook also supports the use of external profiling tools such as cProfile and pytest.
Handling Errors and Exceptions in Jupyter Notebook
Errors and exceptions are a common occurrence when running code in Jupyter Notebook. To handle errors and exceptions effectively, users can use the following techniques:
- Try/Except Blocks: Try/except blocks allow users to catch and handle exceptions that may occur during the execution of code. By wrapping code in a try block and defining except blocks for specific exceptions, users can prevent errors from halting the execution of the code.
- Finally Blocks: Finally blocks allow users to specify code that should be executed regardless of whether an exception occurs. This can be useful for cleaning up resources such as files or database connections.
By using these techniques, users can ensure that their code runs smoothly and efficiently in Jupyter Notebook, and can quickly identify and fix any errors or exceptions that may occur.
Collaborating and Sharing Jupyter Notebook Documents: Best Practices and Tools
Jupyter Notebook is not only a powerful tool for data analysis, machine learning, and scientific computing, but it is also an excellent platform for collaboration and sharing of documents. This section will discuss best practices and tools for collaborating and sharing Jupyter Notebook documents with others.
Version Control with Git and GitHub
Version control is an essential practice when working with Jupyter Notebook documents, especially when collaborating with others. Git is a popular version control system that allows users to track changes, revert to previous versions, and collaborate with others. GitHub is a web-based platform that provides a user-friendly interface for using Git.
To use Git and GitHub with Jupyter Notebook, users can follow these steps:
- Create a new Git repository on GitHub.
- Clone the repository to the local machine using Git.
- Create a new Jupyter Notebook document in the cloned repository.
- Commit changes to the local repository using Git.
- Push changes to the remote repository on GitHub.
By using Git and GitHub, users can ensure that their Jupyter Notebook documents are always up-to-date and can easily collaborate with others by sharing the remote repository.
Collaboration Tools
In addition to version control, there are several collaboration tools that users can use to work together on Jupyter Notebook documents. Some popular collaboration tools include:
- Google Colab: Google Colab is a free cloud-based platform that allows users to write and run Jupyter Notebook documents in the browser. Google Colab supports real-time collaboration, allowing multiple users to work on the same document simultaneously.
- JupyterHub: JupyterHub is a multi-user version of Jupyter Notebook that allows multiple users to have their own Jupyter Notebook server. JupyterHub supports real-time collaboration, allowing multiple users to work on the same document simultaneously.
- CoCalc: CoCalc is a cloud-based platform that provides a full suite of collaboration tools for Jupyter Notebook, including real-time collaboration, file sharing, and messaging.
Presentation Options
Jupyter Notebook documents can be exported to several presentation formats, making it easy to share results with others. Some popular presentation options include:
- HTML: Jupyter Notebook documents can be exported to HTML, allowing users to share the document as a standalone web page.
- PDF: Jupyter Notebook documents can be exported to PDF, allowing users to share the document as a printable document.
- Slides: Jupyter Notebook documents can be exported to Slides, allowing users to create a slideshow presentation from the document.
By using these best practices and tools, users can effectively collaborate and share Jupyter Notebook documents with others, making it an excellent platform for data analysis, machine learning, and scientific computing.
