
What is EC2 Autoscaling and Why is it Important?
EC2 Autoscaling is a powerful feature of Amazon Web Services (AWS) that enables users to automatically adjust the number of EC2 instances in response to changes in demand. By scaling resources up or down as needed, EC2 Autoscaling helps optimize cost, performance, and availability. This is particularly important for managing dynamic workloads, where demand can fluctuate rapidly and unpredictably.
One of the key benefits of EC2 Autoscaling is cost optimization. By automatically scaling resources up or down based on demand, users can avoid overprovisioning and minimize waste. This can lead to significant cost savings, particularly for applications with variable workloads. Additionally, EC2 Autoscaling can help ensure high availability by automatically adding or removing instances to meet demand. This can help prevent downtime and ensure a consistent user experience.
EC2 Autoscaling can also improve performance by ensuring that applications have access to the resources they need to handle peak demand. By automatically scaling resources up or down, EC2 Autoscaling can help ensure that applications have access to the optimal number of instances to handle current workloads. This can help prevent performance degradation and ensure a consistent user experience, even during periods of high demand.
In summary, EC2 Autoscaling is a powerful feature of AWS that enables users to automatically adjust the number of EC2 instances in response to changes in demand. By optimizing cost, improving performance, and ensuring high availability, EC2 Autoscaling can help users manage dynamic workloads and ensure a consistent user experience.

Key Components of EC2 Autoscaling
EC2 Autoscaling is composed of several key components that work together to create a flexible and responsive infrastructure. These components include Launch Configurations, Launch Templates, Auto Scaling Groups, and Scaling Policies. Understanding these components is essential for designing and implementing effective Autoscaling solutions.
Launch Configurations
Launch Configurations define the instance type, storage, security groups, and other parameters for the instances in an Auto Scaling Group. Once created, Launch Configurations cannot be modified, but a new Launch Configuration can be created and associated with an existing Auto Scaling Group to update the instance configuration.
Launch Templates
Launch Templates provide a more flexible and customizable way to define instance configurations than Launch Configurations. Launch Templates allow users to specify multiple instance types, storage configurations, and other parameters, and can be modified after creation. Launch Templates can also be used to create new Auto Scaling Groups or update existing ones.
Auto Scaling Groups
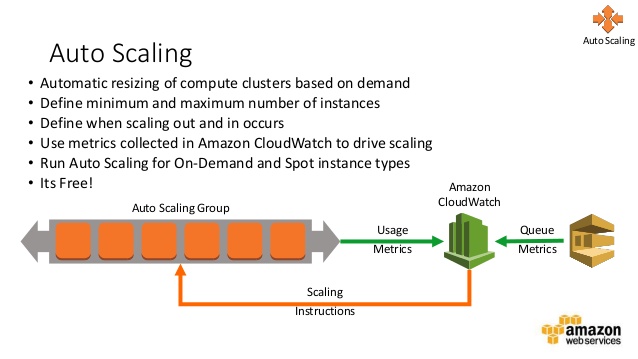
Auto Scaling Groups are the core component of EC2 Autoscaling. An Auto Scaling Group contains a collection of EC2 instances that share the same Launch Configuration or Launch Template. Auto Scaling Groups can automatically scale the number of instances up or down based on demand, using Scaling Policies.
Scaling Policies
Scaling Policies define the rules for scaling an Auto Scaling Group. Scaling Policies can be based on a variety of metrics, such as CPU utilization, network traffic, or custom CloudWatch metrics. Scaling Policies can also be triggered by scheduled events, such as time of day or day of the week. Scaling Policies can scale the number of instances in an Auto Scaling Group up or down, based on the defined rules.
By combining these components, EC2 Autoscaling can create a flexible and responsive infrastructure that can automatically adjust to changes in demand. Understanding how these components work together is essential for designing and implementing effective Autoscaling solutions.

Getting Started with EC2 Autoscaling: A Step-by-Step Guide
EC2 Autoscaling can be a complex topic, but getting started doesn’t have to be. In this section, we’ll provide a detailed, beginner-friendly guide to setting up EC2 Autoscaling. We’ll include screenshots and examples to help you follow along, and we’ll discuss best practices for configuring Autoscaling Groups, Launch Configurations, and Scaling Policies.
Step 1: Create a Launch Configuration
The first step in setting up EC2 Autoscaling is to create a Launch Configuration. A Launch Configuration defines the instance type, storage, security groups, and other parameters for the instances in an Auto Scaling Group. To create a Launch Configuration, navigate to the EC2 console and click on “Launch Configurations” in the “Auto Scaling” section. Then, click on “Create launch configuration” and follow the prompts to configure your instance settings.
Step 2: Create an Auto Scaling Group
Once you’ve created a Launch Configuration, the next step is to create an Auto Scaling Group. An Auto Scaling Group contains a collection of EC2 instances that share the same Launch Configuration or Launch Template. To create an Auto Scaling Group, navigate to the EC2 console and click on “Auto Scaling Groups” in the “Auto Scaling” section. Then, click on “Create Auto Scaling Group” and follow the prompts to configure your group settings.
Step 3: Configure Scaling Policies
The final step in setting up EC2 Autoscaling is to configure Scaling Policies. Scaling Policies define the rules for scaling an Auto Scaling Group. To configure Scaling Policies, navigate to the EC2 console and click on “Scaling Policies” in the “Auto Scaling” section. Then, click on “Create Scaling Policy” and follow the prompts to configure your scaling rules.
When configuring Scaling Policies, it’s important to consider the metrics you want to use for scaling. Common metrics include CPU utilization, network traffic, and custom CloudWatch metrics. You should also consider the thresholds and cooldown periods for your Scaling Policies to prevent rapid scaling and ensure stability.
By following these steps, you can quickly and easily set up EC2 Autoscaling and start reaping the benefits of a flexible and responsive infrastructure. Remember to monitor your Autoscaling Groups and Scaling Policies regularly to ensure they’re meeting your performance and availability needs.

Monitoring and Managing EC2 Autoscaling
Once you’ve set up EC2 Autoscaling, it’s important to monitor and manage your Autoscaling Groups to ensure they’re meeting your performance and availability needs. In this section, we’ll explore the various tools and techniques for monitoring and managing EC2 Autoscaling, including CloudWatch, Application Load Balancer, and EC2 Instance Metadata.
CloudWatch
CloudWatch is a powerful monitoring and management tool for AWS resources, including EC2 Autoscaling. With CloudWatch, you can monitor metrics such as CPU utilization, network traffic, and disk I/O to detect issues and optimize performance. You can also set alarms and notifications to alert you when metrics exceed certain thresholds, allowing you to take action before issues become critical.
Application Load Balancer
An Application Load Balancer (ALB) can be used to distribute traffic across multiple EC2 instances in an Autoscaling Group. With an ALB, you can monitor and manage traffic flow, ensuring that your applications are highly available and responsive. ALBs also support advanced features such as content-based routing, sticky sessions, and SSL termination, allowing you to create complex and scalable application architectures.
EC2 Instance Metadata
EC2 Instance Metadata is a service that provides information about the current EC2 instance, including its IP address, region, and Availability Zone. With EC2 Instance Metadata, you can programmatically retrieve information about the instance and use it to manage and monitor your Autoscaling Groups. For example, you could use EC2 Instance Metadata to retrieve the instance’s public IP address and use it to perform health checks or configure load balancers.
By using these tools and techniques, you can effectively monitor and manage your EC2 Autoscaling Groups, ensuring they’re meeting your performance and availability needs. Remember to regularly review your metrics and alarms, and adjust your Scaling Policies as needed to optimize performance and cost.

Scaling Strategies for EC2 Autoscaling
EC2 Autoscaling offers several scaling strategies that allow you to automatically adjust the number of instances in your Autoscaling Group based on demand. In this section, we’ll examine three common scaling strategies: dynamic, predictive, and scheduled scaling. We’ll discuss the advantages and disadvantages of each strategy, and provide examples of when to use them. We’ll also explain how to configure Scaling Policies to implement these strategies.
Dynamic Scaling
Dynamic scaling is a reactive scaling strategy that adjusts the number of instances in your Autoscaling Group based on current demand. With dynamic scaling, you can set up CloudWatch alarms to trigger Scaling Policies when certain metrics, such as CPU utilization or network traffic, exceed or fall below certain thresholds. This allows you to quickly and automatically scale your resources up or down as needed to meet demand.
Dynamic scaling is ideal for applications with unpredictable or fluctuating workloads, such as e-commerce sites during holiday seasons or social media platforms during live events. However, dynamic scaling can lead to overprovisioning or underprovisioning if the scaling policies are not carefully configured.
Predictive Scaling
Predictive scaling is a proactive scaling strategy that uses historical data and machine learning algorithms to predict future demand and adjust the number of instances in your Autoscaling Group accordingly. With predictive scaling, you can create Scaling Policies that automatically increase or decrease the number of instances based on predicted demand.
Predictive scaling is ideal for applications with predictable workloads, such as batch processing jobs or scheduled reports. However, predictive scaling requires historical data and may not be effective for applications with unpredictable workloads.
Scheduled Scaling
Scheduled scaling is a manual scaling strategy that adjusts the number of instances in your Autoscaling Group based on a predefined schedule. With scheduled scaling, you can create Scaling Policies that automatically increase or decrease the number of instances at specific times of the day, week, or month.
Scheduled scaling is ideal for applications with predictable demand patterns, such as business hours or weekends. However, scheduled scaling may not be effective for applications with unpredictable workloads.
By understanding these scaling strategies and how to configure Scaling Policies, you can effectively manage your EC2 Autoscaling resources and ensure they’re meeting your performance and availability needs. Remember to regularly review your Scaling Policies and adjust them as needed to optimize cost and performance.

EC2 Autoscaling Use Cases and Best Practices
EC2 Autoscaling is a powerful tool for managing dynamic workloads on AWS, and it can be used in a variety of real-world scenarios. In this section, we’ll explore some common use cases for EC2 Autoscaling, such as web applications, batch processing, and container orchestration. We’ll also provide best practices for designing and implementing Autoscaling solutions for these use cases, and discuss common challenges and how to overcome them.
Web Applications
Web applications are a common use case for EC2 Autoscaling. With Autoscaling, you can automatically adjust the number of instances in your Autoscaling Group based on demand, ensuring that your application can handle traffic spikes and remain highly available. To implement Autoscaling for web applications, you can use CloudWatch alarms to trigger Scaling Policies based on metrics such as CPU utilization or request count. You can also use an Application Load Balancer to distribute traffic across multiple instances and ensure high availability.
Best practices for Autoscaling web applications include setting up health checks to ensure that instances are running correctly, using instance warm-up periods to ensure that new instances are fully initialized before they receive traffic, and using cooldown periods to prevent rapid scaling and ensure stability.
Batch Processing
Batch processing is another common use case for EC2 Autoscaling. With Autoscaling, you can automatically launch and terminate instances based on the workload, ensuring that you’re only using the resources you need and minimizing costs. To implement Autoscaling for batch processing, you can use Scaling Policies to launch instances when the workload exceeds a certain threshold, and terminate instances when the workload falls below a certain threshold.
Best practices for Autoscaling batch processing workloads include using spot instances to reduce costs, using instance metadata to pass parameters and data to instances, and using AWS Batch to manage and optimize batch processing workloads.
Container Orchestration
Container orchestration is a growing use case for EC2 Autoscaling. With Autoscaling, you can automatically launch and terminate instances based on the demand for your containers, ensuring that you’re only using the resources you need and minimizing costs. To implement Autoscaling for container orchestration, you can use tools such as Amazon ECS, Amazon EKS, or Kubernetes, which support Autoscaling natively.
Best practices for Autoscaling container orchestration workloads include using spot instances to reduce costs, using instance metadata to pass parameters and data to instances, and using lifecycle hooks to perform custom actions when instances are launched or terminated.
By understanding these use cases and best practices, you can effectively design and implement Autoscaling solutions for your workloads on AWS. Remember to regularly review your Autoscaling Groups and Scaling Policies, and adjust them as needed to optimize cost and performance.
Troubleshooting EC2 Autoscaling Issues
EC2 Autoscaling is a powerful tool for managing dynamic workloads on AWS, but it can also be complex and prone to issues. In this section, we’ll identify some common issues that may arise when using EC2 Autoscaling, such as scaling delays, termination protection, and health check failures. We’ll provide troubleshooting steps and solutions for each issue, and discuss how to monitor and prevent these issues from occurring in the future.
Scaling Delays
Scaling delays can occur when Autoscaling takes too long to launch or terminate instances, leading to underprovisioning or overprovisioning of resources. To troubleshoot scaling delays, you can check the CloudWatch metrics for your Autoscaling Group, such as GroupMinSize, GroupMaxSize, and GroupDesiredCapacity, to ensure that they match your Scaling Policy. You can also check the launch configuration and launch template settings to ensure that they’re correctly configured.
To prevent scaling delays, you can use instance warm-up periods to ensure that new instances are fully initialized before they receive traffic, and use cooldown periods to prevent rapid scaling and ensure stability. You can also use spot instances to reduce scaling delays and costs.
Termination Protection
Termination protection can prevent instances from being accidentally terminated, but it can also interfere with Autoscaling. To troubleshoot termination protection issues, you can check the instance settings to ensure that termination protection is enabled or disabled as needed. You can also check the Autoscaling Group settings to ensure that they’re correctly configured to terminate instances.
To prevent termination protection issues, you can use lifecycle hooks to perform custom actions when instances are launched or terminated, and use termination policies to specify which instances should be terminated first.
Health Check Failures
Health check failures can occur when instances fail to pass health checks, leading to them being terminated and replaced. To troubleshoot health check failures, you can check the instance settings to ensure that they’re correctly configured, and check the CloudWatch metrics for your Autoscaling Group to ensure that they’re within acceptable limits. You can also check the Application Load Balancer settings to ensure that they’re correctly configured.
To prevent health check failures, you can use health checks to ensure that instances are running correctly, and use instance warm-up periods to ensure that new instances are fully initialized before they receive traffic. You can also use Amazon EC2 Systems Manager to automate instance maintenance and ensure that they’re running correctly.
By understanding these common issues and how to troubleshoot them, you can effectively manage and optimize your EC2 Autoscaling infrastructure. Remember to regularly review your Autoscaling Groups and Scaling Policies, and adjust them as needed to optimize cost and performance.

Advanced Topics in EC2 Autoscaling
EC2 Autoscaling is a powerful tool for managing dynamic workloads on AWS, and it offers several advanced features that can help you optimize cost, performance, and availability. In this section, we’ll dive deeper into some of these advanced topics, such as Spot Instances, Lifecycle Hooks, and Instance Refresh. We’ll explain how these features work, and provide examples and best practices for using them in real-world scenarios.
Spot Instances
Spot Instances are instances that can be purchased at a discounted price, but they can be terminated at any time when demand for Spot Instances increases. To use Spot Instances with EC2 Autoscaling, you can configure your Autoscaling Group to launch and terminate Spot Instances based on demand. This can help you save up to 90% on instance costs, but it requires careful planning and management to ensure availability and performance.
Best practices for using Spot Instances with EC2 Autoscaling include using spot fleets to launch and manage Spot Instances, using instance pools to ensure availability, and using instance hibernation to save instance state and reduce launch times. You should also monitor Spot Instance prices and availability to ensure that your Autoscaling Group can launch and terminate instances as needed.
Lifecycle Hooks
Lifecycle Hooks are custom actions that can be performed when instances are launched or terminated in an Autoscaling Group. Lifecycle Hooks can be used to perform tasks such as running custom scripts, performing system updates, or integrating with external systems. Lifecycle Hooks can be configured to wait for a specified period of time before continuing with the instance launch or termination process.
Best practices for using Lifecycle Hooks with EC2 Autoscaling include using them to perform tasks that require human intervention, such as system updates or configuration changes, and using them to integrate with external systems, such as monitoring or logging systems. You should also ensure that Lifecycle Hooks are configured to wait for a reasonable amount of time to allow tasks to complete, and that they’re tested thoroughly before being used in production.
Instance Refresh
Instance Refresh is a feature that allows you to replace instances in an Autoscaling Group with newer instances that have the latest updates and patches. Instance Refresh can be used to ensure that instances are up-to-date and secure, and to improve performance and availability.
Best practices for using Instance Refresh with EC2 Autoscaling include scheduling Instance Refresh during off-peak hours to minimize disruption, and testing Instance Refresh thoroughly before using it in production. You should also ensure that your Autoscaling Group is configured to launch instances with the latest updates and patches, and that you’re monitoring instance health and performance to ensure that they’re running correctly.
By understanding these advanced topics and how to use them, you can optimize your EC2 Autoscaling infrastructure for cost, performance, and availability. Remember to regularly review your Autoscaling Groups and Scaling Policies, and adjust them as needed to ensure that they’re meeting your needs and optimizing your workloads on AWS.