What are Docker Volumes and Why are they Important?
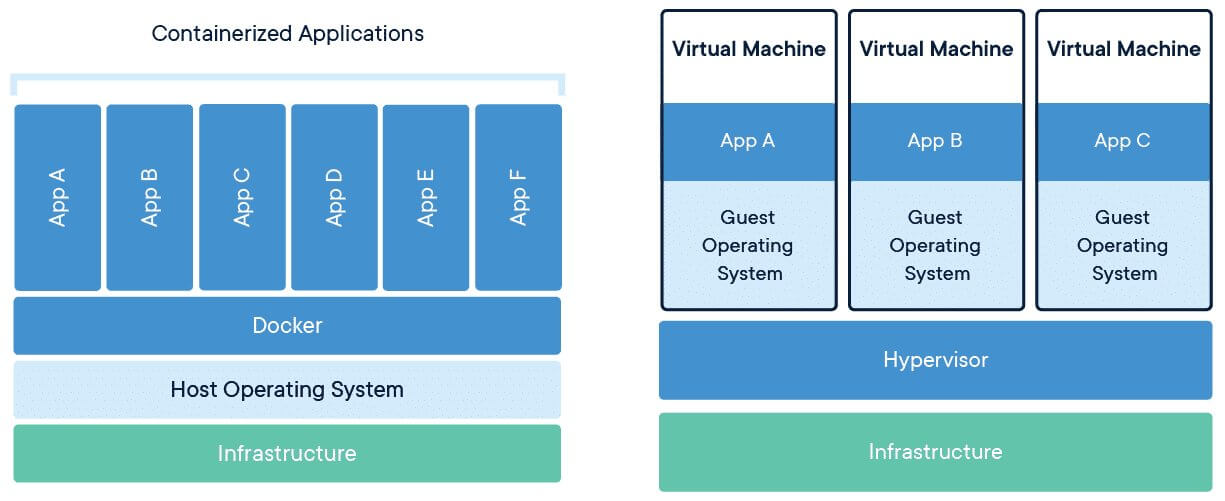
Docker volumes are a mechanism for persisting and managing data in Docker containers. They provide a way to decouple data storage from the container, allowing for data to be shared between containers and ensuring that data is not lost when a container is stopped or removed. This is in contrast to bind mounts, which directly mount a host directory or file into a container, and can lead to data loss or inconsistencies if not managed properly.
Using Docker volumes over bind mounts offers several benefits, including improved data persistence, easier data management, and increased flexibility. With volumes, data is stored separately from the container, making it easier to back up, restore, and migrate. Additionally, volumes can be shared between containers, allowing for data to be easily reused and reducing the need for duplication. This results in a more efficient and flexible Docker environment, where data can be managed independently of the containers that use it.
In summary, Docker volumes are a crucial component of any Docker environment, providing a reliable and flexible solution for data persistence and management. By understanding what Docker volumes are and how they can be used, you can ensure that your Docker infrastructure is robust, reliable, and scalable.
How to Create and Manage Docker Volumes
Docker volumes can be easily created, listed, and removed using the Docker CLI. Here is a step-by-step guide on how to manage Docker volumes:
Creating a Docker Volume
To create a new Docker volume, use the following command:
$ docker volume create my-volume
This will create a new volume named “my-volume” that can be used in your Docker containers.
Listing Docker Volumes
To list all the Docker volumes on your system, use the following command:
$ docker volume ls
This will display a list of all the volumes currently available on your system.
Inspecting a Docker Volume
To inspect a specific Docker volume and view its details, use the following command:
$ docker volume inspect my-volume
This will display detailed information about the “my-volume” volume, including its name, driver, mount point, and other relevant details.
Removing a Docker Volume
To remove a Docker volume, use the following command:
$ docker volume rm my-volume
This will remove the “my-volume” volume from your system. Note that you cannot remove a volume that is currently in use by a container.
In conclusion, managing Docker volumes is a straightforward process that can be easily accomplished using the Docker CLI. By following the steps outlined in this guide, you can create, list, inspect, and remove Docker volumes with ease.
Using Docker Volumes with Docker Compose
Docker Compose is a powerful tool for defining and running multi-container Docker applications. When using Docker Compose, you can easily define and use volumes to manage data persistence and sharing between containers. Here’s how:
Defining Volumes in a Docker Compose File
To define a volume in a Docker Compose file, use the following syntax:
Securing Docker Volumes: Best Practices and Recommendations
Docker volumes are an essential part of any Docker-based infrastructure, providing a way to persist and manage data in a containerized environment. However, with this convenience comes the need for proper security measures to protect sensitive data and prevent unauthorized access.
Volume Permissions
One of the most basic security considerations for Docker volumes is volume permissions. By default, volumes are owned by the root user and group, which can pose a security risk if the container running on the volume is compromised. To mitigate this risk, it's recommended to change the ownership and permissions of the volume to match the user and group running the container.
Data Encryption
Another important security consideration for Docker volumes is data encryption. Encrypting data at rest and in transit can help protect sensitive information from unauthorized access and ensure compliance with data privacy regulations. Docker provides built-in support for data encryption through the use of encryption keys and algorithms.
Access Control
Access control is also a critical component of Docker volume security. By controlling who has access to a volume and what actions they can perform, you can prevent unauthorized access and reduce the risk of data breaches. Docker provides several access control mechanisms, including role-based access control (RBAC), access control lists (ACLs), and network policies.
Best Practices
To ensure the security of your Docker volumes, follow these best practices:
Regularly review and update volume permissions to ensure they match the user and group running the container.
Use data encryption to protect sensitive information and ensure compliance with data privacy regulations.
Implement access control mechanisms to prevent unauthorized access and reduce the risk of data breaches.
Regularly monitor and audit volume activity to detect and respond to security incidents.
By following these best practices and recommendations, you can help ensure the security and integrity of your Docker volumes and protect your containerized environment from potential threats.
Real-World Examples of Docker Volumes in Action
Docker volumes have become an essential tool for managing data persistence and consistency in containerized environments. They offer numerous benefits over traditional bind mounts, including better performance, easier management, and more robust security. In this section, we will explore some real-world examples of how Docker volumes are used in production environments and the challenges and solutions of using volumes in large-scale applications.
Example 1: Persisting Data Across Container Restarts
One of the most common use cases for Docker volumes is to persist data across container restarts. For example, consider a web application that stores user-generated content in a local file system. If the container is stopped or restarted, all the data will be lost. However, by using a Docker volume, the data can be persisted even if the container is stopped or restarted.
Example 2: Sharing Data Between Containers
Another common use case for Docker volumes is to share data between containers. For example, consider a microservices architecture where multiple containers need to access the same data. By using a Docker volume, the data can be shared between containers, ensuring consistency and reducing data duplication.
Example 3: Backing Up and Restoring Data
Docker volumes can also be used to back up and restore data. By creating a backup of a volume, the data can be easily restored in case of a failure or disaster. This is especially useful in large-scale environments where data loss can result in significant downtime and financial losses.
Challenges and Solutions
While Docker volumes offer numerous benefits, they can also present some challenges in large-scale environments. For example, managing and monitoring volumes can become complex and time-consuming as the number of volumes and containers grows. To address these challenges, several solutions are available, including:
Using a centralized management tool, such as Docker Swarm or Kubernetes, to manage and monitor volumes and containers.
Implementing automation and orchestration tools, such as Ansible or Terraform, to automate the creation, configuration, and deletion of volumes and containers.
Using a third-party plugin, such as Flocker or Convoy, to enhance data management capabilities and provide additional features, such as data replication and backup.
By using these solutions, organizations can overcome the challenges of managing and monitoring Docker volumes in large-scale environments and ensure a more robust and reliable Docker infrastructure.
Docker Volume Plugins: Enhancing Data Management Capabilities
Docker volume plugins are third-party extensions that can be used to enhance the data management capabilities of Docker environments. They provide additional features and functionality beyond what is offered by the default Docker volume driver, such as data replication, backup, and disaster recovery. In this section, we will introduce Docker volume plugins and provide examples of popular plugins and their use cases.
What are Docker Volume Plugins?
Docker volume plugins are third-party extensions that can be installed and used in Docker environments to enhance data management capabilities. They provide additional features and functionality beyond what is offered by the default Docker volume driver, such as data replication, backup, and disaster recovery. Plugins can be developed by third-party vendors or the Docker community and are available through the Docker Hub or other package managers.
Popular Docker Volume Plugins
There are several popular Docker volume plugins available, each with its own unique features and use cases. Here are some examples:
Flocker: Flocker is a data volume management tool for Docker containers that allows users to manage data volumes across multiple hosts. It provides features such as data migration, backup, and disaster recovery.
Convoy: Convoy is a container-native storage solution that provides persistent storage for Docker containers. It allows users to create and manage volumes, snapshots, and replicas, and supports multiple storage backends.
RexRay: RexRay is a storage orchestration tool for Docker that provides a unified interface for managing storage across multiple platforms. It supports multiple storage backends, including local storage, network storage, and cloud storage.
Use Cases for Docker Volume Plugins
Docker volume plugins can be used in a variety of use cases, such as:
Managing data volumes across multiple hosts
Providing persistent storage for Docker containers
Implementing data replication and backup strategies
Enforcing data encryption and access control policies
Integrating with external storage systems, such as network file systems or cloud storage services
Best Practices for Using Docker Volume Plugins
When using Docker volume plugins, it is important to follow best practices to ensure a secure and reliable Docker environment. Here are some recommendations:
Verify the authenticity and security of the plugin before installing it
Configure the plugin with appropriate permissions and access controls
Monitor the plugin for errors and performance issues
By following these best practices, organizations can leverage the power of Docker volume plugins to enhance data management capabilities and provide a more robust and reliable Docker infrastructure.
Comparing Docker Volumes to Other Data Management Solutions
Docker volumes are a powerful tool for managing data persistence and consistency in containerized environments. However, they are not the only solution available for data management in Docker. In this section, we will compare Docker volumes to other data management solutions, such as network file systems, cloud storage services, and container-native storage, and discuss the pros and cons of each solution. We will also provide recommendations on when to use each solution.
Network File Systems
Network file systems (NFS) are a popular solution for sharing files and data across multiple hosts. They provide a centralized storage location that can be accessed by multiple clients. NFS can be used with Docker to provide persistent storage for containers. However, NFS has some limitations, such as slower performance compared to local storage and potential issues with data consistency and availability.
Cloud Storage Services
Cloud storage services, such as Amazon Elastic Block Store (EBS) or Google Persistent Disks, provide scalable and flexible storage options for containerized environments. They can be used with Docker to provide persistent storage for containers and offer features such as data replication, backup, and disaster recovery. However, cloud storage services can be more expensive than local storage and may introduce additional latency and performance issues.
Container-Native Storage
Container-native storage is a storage solution that is specifically designed for containerized environments. It provides a unified storage layer that can be used by multiple containers and services. Container-native storage offers features such as data replication, backup, and disaster recovery, and can be integrated with other container orchestration tools, such as Kubernetes or Docker Swarm. However, container-native storage can be more complex to set up and manage compared to other storage solutions.
When to Use Each Solution
The choice of data management solution depends on several factors, such as the size and complexity of the Docker environment, the required features and functionality, and the available budget. Here are some recommendations on when to use each solution:
Use Docker volumes for simple use cases that require basic data persistence and consistency.
Use network file systems for sharing files and data across multiple hosts, but be aware of the potential performance and consistency issues.
Use cloud storage services for scalable and flexible storage options, but be prepared for the additional cost and potential latency issues.
Use container-native storage for complex containerized environments that require advanced features and functionality, but be prepared for the additional complexity and management overhead.
By understanding the strengths and limitations of each data management solution, organizations can make informed decisions on how to best manage data persistence and consistency in their Docker environments.
The Future of Docker Volumes: Trends and Developments
Docker volumes have become an essential tool for managing data persistence and consistency in containerized environments. As containerization technology continues to evolve, so do the trends and developments in data management for container environments. In this section, we will discuss the future of Docker volumes and the trends and developments in data management for container environments, including container-native storage, serverless computing, and edge computing.
Container-Native Storage
Container-native storage is a storage solution that is specifically designed for containerized environments. It provides a unified storage layer that can be used by multiple containers and services. Container-native storage offers features such as data replication, backup, and disaster recovery, and can be integrated with other container orchestration tools, such as Kubernetes or Docker Swarm. In the future, we can expect to see more advanced features and functionality in container-native storage, such as dynamic provisioning, auto-scaling, and policy-based management.
Serverless Computing
Serverless computing is a cloud computing model where the cloud provider manages the infrastructure and dynamically allocates resources as needed. Serverless computing can be used with containerized environments to provide a more scalable and flexible infrastructure. In the future, we can expect to see more integration between Docker volumes and serverless computing platforms, such as AWS Lambda or Google Cloud Functions, to provide a more seamless data management experience.
Edge Computing
Edge computing is a computing model where data processing and analysis are performed closer to the source of the data, rather than in a centralized data center. Edge computing can be used with containerized environments to provide a more distributed and scalable infrastructure. In the future, we can expect to see more integration between Docker volumes and edge computing platforms, such as IoT devices or edge gateways, to provide a more efficient and secure data management experience.
Best Practices for the Future of Docker Volumes
As the trends and developments in data management for container environments continue to evolve, it is important to follow best practices to ensure a secure and reliable Docker environment. Here are some recommendations:
Stay up-to-date with the latest trends and developments in data management for container environments.
Implement security best practices, such as volume permissions, data encryption, and access control, to protect sensitive data.
Monitor the Docker environment for errors and performance issues, and regularly update the Docker environment and its components.
Test new features and functionality in a non-production environment before deploying them in production.
By following these best practices, organizations can leverage the power of Docker volumes and the future trends and developments in data management for container environments to provide a more efficient, secure, and scalable infrastructure.