
Understanding Docker Volumes: A Key Feature Explained
Docker volumes are a crucial feature in the Docker ecosystem, designed to persist data generated by Docker containers. This data remains accessible even after the container has stopped or been removed, ensuring that your valuable information is not lost. Docker volumes offer numerous benefits, such as improved data management, separation of concerns, and increased flexibility. By understanding and utilizing Docker volumes effectively, you can significantly enhance your container management experience.
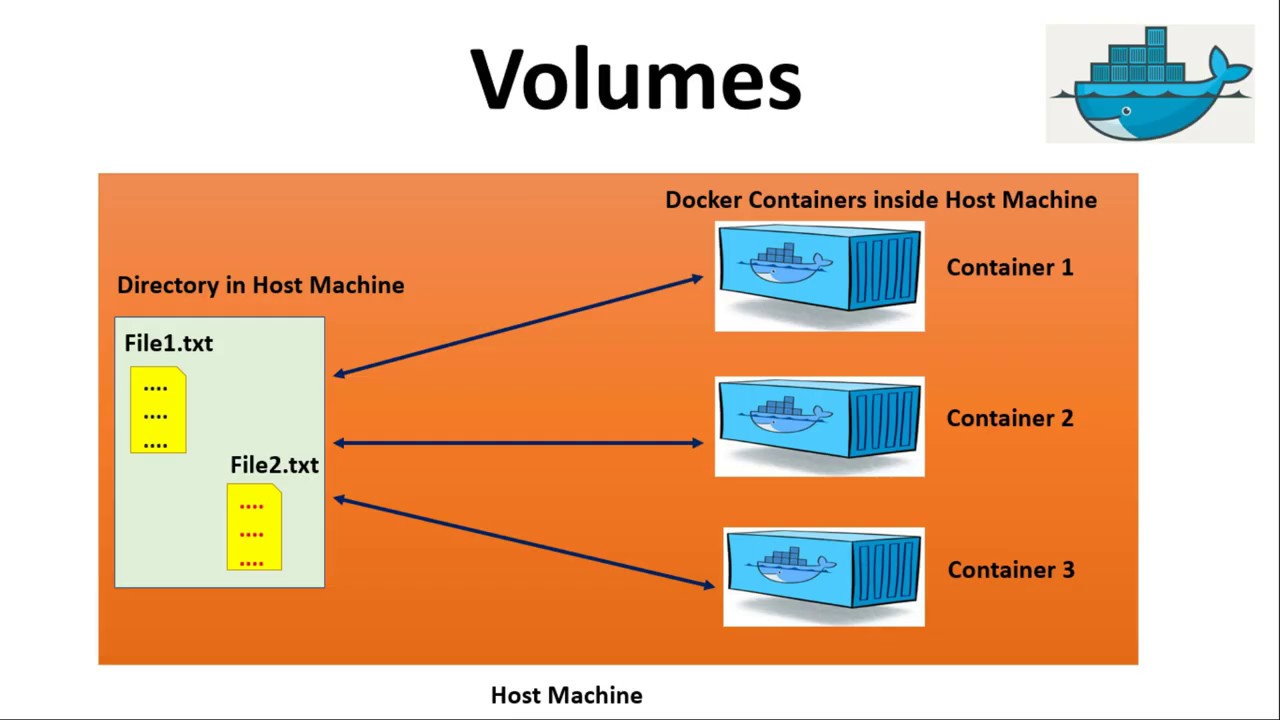
Docker volumes serve as a link between Docker containers and the host system’s file system. They allow data to be shared between containers and the host, making it possible to maintain data persistence and consistency. The Docker –volume flag is a primary command used to manage and manipulate volumes, providing developers with a powerful tool to handle data within their containerized applications.
How to Use Docker –volume Command: A Step-by-Step Guide
The Docker –volume flag is a powerful command that enables you to manage and manipulate Docker volumes effectively. By mastering its use, you can ensure proper data management and persistence for your containerized applications. Here is a clear, concise, and easy-to-understand tutorial on how to use the Docker –volume command:
- Specifying the volume name: When using the Docker –volume flag, you can assign a name to the volume by simply stating the name followed by a colon and the directory path, like so:
--volume myvolume:/path/in/container. - Mounting host directories: To mount a host directory as a volume, use the following format:
--volume /path/on/host:/path/in/container. This will allow data to be shared between the host and the container. - Setting volume permissions: You can set read and write permissions for volumes by adding the
:roor:rwflags after the directory path. For example, to mount a volume as read-only, use:--volume myvolume:/path/in/container:ro.
Here’s an example of using the Docker –volume flag to create and manage a volume:
$ docker volume create myvolume $ docker run -d --name mycontainer -v myvolume:/path/in/container myimage $ docker exec -it mycontainer bash # echo "Hello, World!" > /path/in/container/file.txt $ docker cp mycontainer:/path/in/container/file.txt /path/on/host In this example, we create a volume called “myvolume,” run a container called “mycontainer” using that volume, and then copy a file from the container to the host. This demonstrates the power and flexibility of the Docker –volume flag in managing data within containerized applications.

Different Types of Docker Volumes: Choosing the Right One for Your Needs
Docker offers several types of volumes, each with its unique features and use cases. Understanding the differences between them is crucial for making the right choice for your specific needs. Here, we discuss named volumes, bind mounts, and tmpfs volumes, providing examples and best practices for each:
Named Volumes
Named volumes are Docker’s native storage solution, managed by the Docker daemon. They are created using the docker volume create command and can be used across multiple containers. Named volumes offer several benefits, such as automatic data persistence, consistent naming, and the ability to be managed independently of containers.
Bind Mounts
Bind mounts allow you to mount a directory or file from the host system to a container. They are useful for sharing configuration files, libraries, or other data between the host and the container. However, bind mounts do not offer the same level of data persistence as named volumes, as they are tied to the host file system and can be affected by host file changes.
tmpfs Volumes
tmpfs volumes are stored in the host system’s volatile memory (RAM), rather than on disk. They are useful for storing temporary data that does not require persistence after the container is stopped. However, since data in tmpfs volumes is not stored on disk, it will be lost once the container is stopped or the host is rebooted.
When deciding which type of volume to use, consider the following:
- Data persistence: If you need to ensure data persistence, named volumes are the best choice. Bind mounts can also provide persistence, but they are more susceptible to host file changes.
- Performance: tmpfs volumes offer the best performance, as they are stored in memory. However, they should only be used for storing temporary data.
- Data isolation: Named volumes provide better data isolation, as they are managed independently of the host file system.
- Use cases: Named volumes are ideal for storing application data, while bind mounts are useful for sharing configuration files or libraries. tmpfs volumes are best suited for storing temporary data, such as caching or session data.
By understanding the different types of Docker volumes and their use cases, you can make informed decisions about which volume type to use in your projects, ensuring optimal data management and persistence for your containerized applications.
Docker Volume Plugins: Enhancing Data Management Capabilities
Docker volume plugins are third-party extensions that enhance the functionality of Docker volumes, providing additional data management features and capabilities. These plugins can help manage network-attached storage, cloud storage, and other third-party storage solutions, making it easier to work with complex data storage requirements in containerized environments.
Some popular Docker volume plugins include:
- Portworx: Portworx is a cloud-native storage platform designed for containerized applications. It offers features such as dynamic volume provisioning, data management, and data protection for Docker volumes. Portworx supports various storage environments, including public, private, and hybrid clouds.
- NetApp Trident: NetApp Trident is a dynamic storage provisioner for containerized applications. It enables the automated provisioning of storage for Docker volumes, supporting various storage backends, such as NetApp ONTAP, SolidFire, and E-Series. Trident also provides data management features, such as snapshotting, cloning, and backup.
- Rancher Longhorn: Rancher Longhorn is a distributed block storage system for containerized applications. It offers features such as data replication, data durability, and data persistence for Docker volumes. Longhorn is designed to be highly available, scalable, and resilient, making it suitable for production workloads.
- Robin Systems: Robin Storage is a container-native storage solution that provides high-performance, persistent storage for containerized applications. It offers features such as automatic data placement, data protection, and data management for Docker volumes. Robin Storage is built for cloud-native environments and supports various storage backends, including public, private, and hybrid clouds.
When choosing a Docker volume plugin, consider the following:
- Supported storage environments: Ensure the plugin supports the storage environment you are using, whether it’s a public, private, or hybrid cloud.
- Data management features: Look for plugins that offer the data management features you need, such as snapshotting, cloning, and backup.
- Performance and scalability: Evaluate the plugin’s performance and scalability to ensure it can handle your workload requirements.
- Integration and compatibility: Ensure the plugin integrates with your existing infrastructure and is compatible with your current tools and processes.
By leveraging Docker volume plugins, you can extend the functionality of Docker volumes, enabling better data management, increased flexibility, and improved data protection for your containerized applications.

Security Best Practices for Docker Volumes: Keeping Your Data Safe
Implementing security best practices for Docker volumes is crucial for protecting sensitive data and preventing unauthorized access. Here are some recommendations to help ensure the security of your Docker volumes:
Limit Access to Volumes
To minimize the risk of unauthorized access, it’s essential to limit the number of users and services that can access a volume. You can achieve this by using Docker’s built-in access control mechanisms, such as user namespaces and Docker’s internal access control lists (ACLs). Additionally, you can configure volume permissions to restrict access to specific users or groups on the host system.
Use Read-Only Volumes
When possible, use read-only volumes to limit the potential impact of a security breach. Read-only volumes prevent applications from modifying data, reducing the risk of data corruption or unauthorized modifications. To create a read-only volume, add the :ro flag when using the Docker –volume command:
$ docker run -d --name mycontainer -v myvolume:/path/in/container:ro myimageEncrypt Data
Encrypting data stored in Docker volumes can help protect sensitive information in case of a security breach. You can use various encryption techniques, such as encrypting data at rest, encrypting data in transit, or using encrypted communication channels between the host and the container. Docker supports encryption for data at rest using third-party plugins, such as the containership/docker-volume-encryption plugin.
Monitor Volume Activity
Monitoring volume activity can help you detect potential security threats and respond to them promptly. You can use various monitoring tools and techniques, such as auditing volume access logs, tracking file changes, and setting up alerts for suspicious activity. Monitoring volume activity can help you maintain a secure and compliant environment for your containerized applications.
By following these security best practices, you can help protect sensitive data and prevent unauthorized access when using Docker volumes. Remember to always stay up-to-date with the latest security patches and recommendations to ensure the ongoing security of your containerized applications.

Troubleshooting Docker Volumes: Common Issues and Solutions
Using Docker volumes can sometimes lead to issues related to permission errors, mounting failures, and data corruption. In this section, we’ll discuss common problems and their solutions, helping you quickly resolve any problems you may encounter when working with Docker volumes.
Permission Errors
Permission errors can occur when the user and group ownership of the volume or the host directory is not correctly set. To resolve this issue, ensure that the user and group ownership of the volume and the host directory match. You can use the chown command to change the ownership:
$ sudo chown -R $USER:$USER /path/to/host/directory Mounting Failures
Mounting failures can occur due to incorrect volume syntax, incorrect mount points, or conflicting mounts. To troubleshoot mounting failures, double-check the volume syntax, ensure that the mount point exists, and verify that no other mounts are conflicting with the volume mount.
Data Corruption
Data corruption can occur due to various reasons, such as hardware failures, software bugs, or incorrect file system configurations. To prevent data corruption, ensure that your file system is correctly configured, use data backup and recovery strategies, and monitor your containers and volumes for any signs of data corruption.
Additional Tips
- Check the Docker logs for any error messages related to volumes.
- Ensure that the volume and container are running on the same Docker host.
- Verify that the volume is correctly attached to the container.
- Check the volume size and available disk space on the host system.
By understanding these common issues and their solutions, you can effectively troubleshoot Docker volumes and ensure the smooth operation of your containerized applications. Remember to always monitor your containers and volumes for any signs of problems and take prompt action to resolve any issues that may arise.

Real-World Examples of Docker Volumes: Success Stories and Lessons Learned
Docker volumes have been used in various projects and applications, providing valuable insights into their successes and lessons learned. In this section, we’ll share some real-world examples of Docker volumes and discuss the key takeaways from these experiences.
Example 1: Data-Intensive Applications
Docker volumes have been used extensively in data-intensive applications, such as big data processing and analytics. By using named volumes, developers can easily manage and scale data storage, ensuring that data is accessible even after containers are stopped or removed. Lessons learned from these examples include the importance of monitoring volume performance and capacity, as well as the need for regular backups and disaster recovery strategies.
Example 2: Database Containers
Docker volumes have also been used in database containers, enabling data persistence and separation of concerns. By using Docker volumes, developers can ensure that data is not lost when containers are updated or replaced. Key takeaways from these examples include the importance of using read-only volumes for database configurations and the need for regular backups and disaster recovery strategies.
Example 3: DevOps and CI/CD Pipelines
Docker volumes have been used in DevOps and CI/CD pipelines, enabling developers to easily manage and share data between different stages of the development process. By using Docker volumes, developers can ensure that data is consistent and accessible across different environments. Lessons learned from these examples include the importance of versioning volumes and the need for automation and integration with CI/CD tools.
By learning from these real-world examples, you can gain valuable insights into the best practices and potential pitfalls of using Docker volumes in your own projects and applications. Remember to always monitor your containers and volumes for any signs of problems and take prompt action to resolve any issues that may arise.
.jpg)
The Future of Docker Volumes: Emerging Trends and Technologies
As Docker and containerization technology continue to evolve, so do the trends and technologies related to Docker volumes. In this section, we’ll explore some of the emerging trends and technologies that have the potential to shape the future of data management in containerized environments.
Container-Native Storage
Container-native storage is a storage architecture designed specifically for containerized environments. It provides a more integrated and streamlined approach to data management, enabling better performance, scalability, and ease of use. By using container-native storage solutions, such as Portworx, Robin Systems, or StorageOS, you can take advantage of advanced features, such as automatic data management, dynamic volume provisioning, and data protection.
Kubernetes Volumes
Kubernetes, the popular container orchestration platform, has its own concept of volumes, which is an abstraction of a directory containing data, which may be stored on a host or on a networked storage system. Kubernetes volumes provide a more flexible and dynamic approach to data management, enabling better integration with container orchestration and data management tools. By using Kubernetes volumes, you can take advantage of advanced features, such as dynamic provisioning, storage classes, and persistent volume claims.
Serverless Storage
Serverless storage is a new approach to data management that is designed to work seamlessly with serverless computing platforms, such as AWS Lambda, Azure Functions, or Google Cloud Functions. Serverless storage provides a more scalable and cost-effective approach to data management, enabling better integration with serverless computing and data management tools. By using serverless storage solutions, such as AWS S3, Azure Blob Storage, or Google Cloud Storage, you can take advantage of advanced features, such as automatic scaling, pay-per-use pricing, and data protection.
By staying up-to-date with these emerging trends and technologies, you can ensure that you are well-prepared for the future of data management in containerized environments. Remember to always monitor your containers and volumes for any signs of problems and take prompt action to resolve any issues that may arise.
