
Understanding Numerical Data in Python
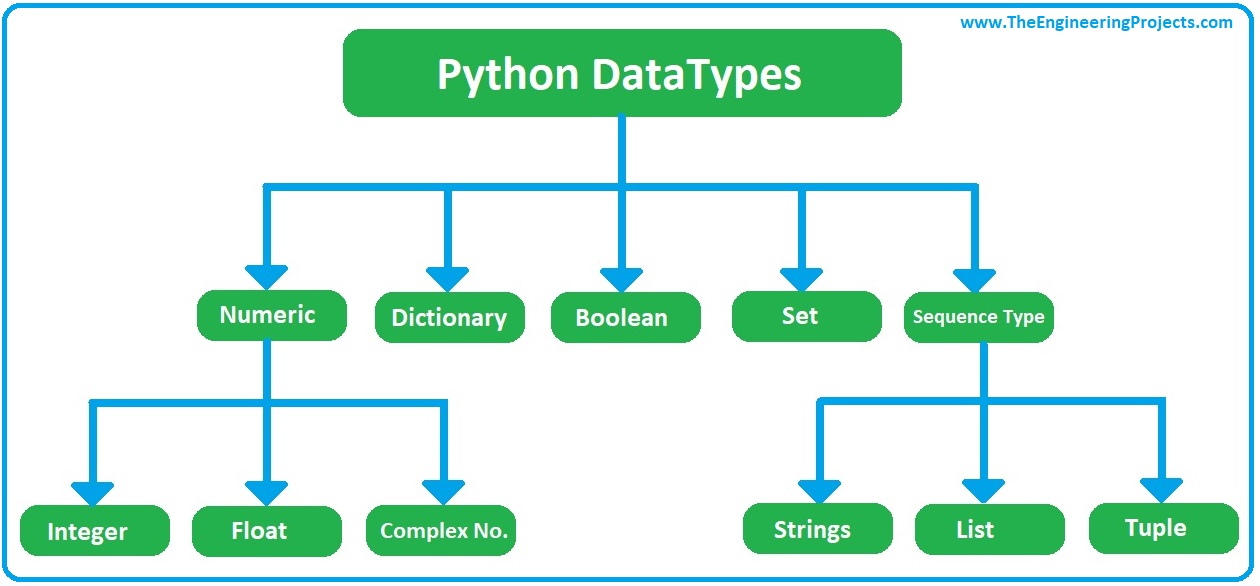
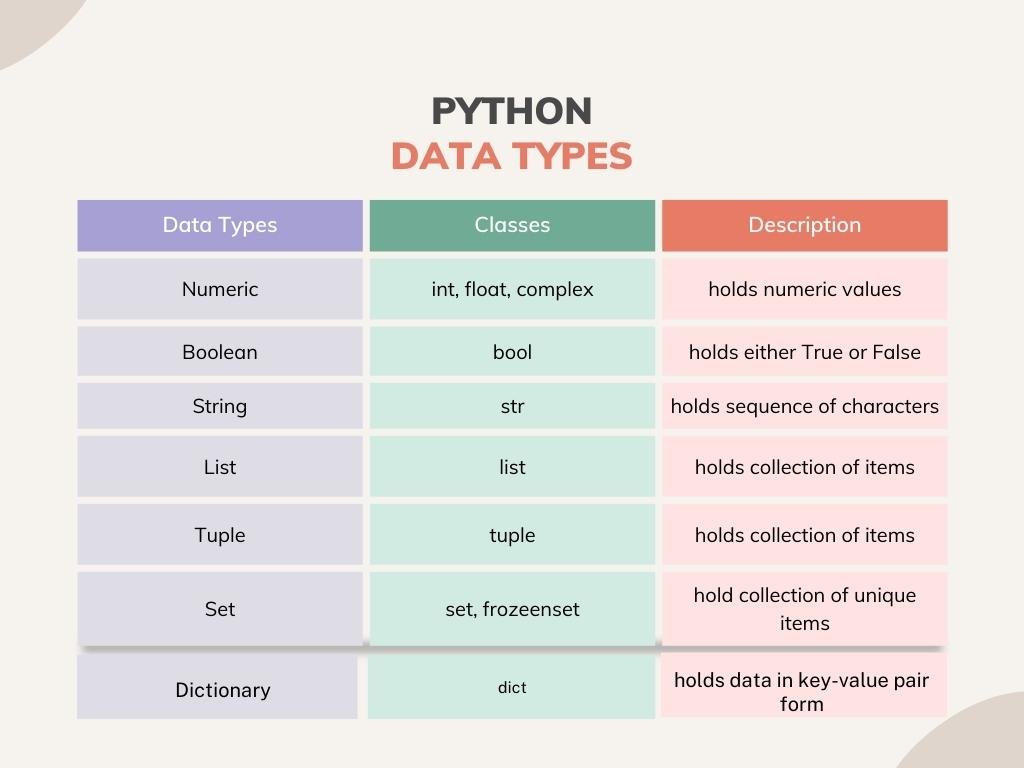
Python is a powerful language for handling numerical data, which is also known as quantitative data. Numerical data can be discrete, such as integers, or continuous, like floating-point numbers and complex numbers. Python’s built-in data types, such as int, float, and complex, facilitate the manipulation and analysis of numerical data. These data types enable programmers to perform arithmetic operations, comparisons, and various mathematical functions with ease.
Numerical data is often used in scientific computing, data analysis, machine learning, and statistical applications. Python’s NumPy and SciPy libraries provide additional tools and functions for handling numerical data, such as array operations, linear algebra, and signal processing. These libraries, combined with the powerful data manipulation capabilities of pandas, make Python an ideal choice for working with different types of data, including numerical data.
Working with Categorical Data in Python
Categorical data, also known as qualitative data, consists of labels or values that can be grouped into categories. Examples of categorical data include gender (male, female, or other), product categories (electronics, fashion, or home appliances), and customer satisfaction levels (satisfied, neutral, or dissatisfied). Working with categorical data is essential in data analysis, as it often provides valuable insights into patterns and trends.
Python’s pandas library is an excellent tool for handling categorical data. The library offers powerful data structures, such as Series and DataFrame, which enable efficient data manipulation and analysis. For instance, the Series object can store categorical data using the CategoricalDtype data type, which provides several benefits, including faster data processing, more efficient memory usage, and the ability to perform category-specific operations.
Additionally, pandas provides methods like cut, qcut, and astype to convert numerical or text data into categorical data. These functions enable data analysts to create custom categories and bins, making it easier to analyze and visualize the data. By understanding and effectively working with categorical data in Python, data professionals can unlock valuable insights and make informed decisions based on their analysis.
Managing Text Data in Python
Text data, or string data, is prevalent in various domains, including natural language processing (NLP), web scraping, and data journalism. Python’s built-in string module and external libraries, such as NLTK (Natural Language Toolkit) and spaCy, offer robust text processing capabilities, enabling data professionals to extract valuable insights from unstructured text data.
Python’s string module provides numerous functions for manipulating and processing text data, such as string concatenation, splitting, replacing, and formatting. Moreover, Python’s powerful regular expression module, re, allows for more advanced text processing tasks, such as pattern matching, searching, and replacing.
For NLP applications, libraries like NLTK and spaCy offer advanced text processing features, such as tokenization, part-of-speech tagging, named entity recognition, and sentiment analysis. These libraries enable data professionals to analyze and understand the meaning, context, and emotion behind text data, providing valuable insights for various industries, including marketing, customer support, and research.
In summary, managing text data in Python is essential for working with unstructured data. By leveraging Python’s built-in string module and external libraries like NLTK and spaCy, data professionals can unlock valuable insights from text data, enhancing decision-making and driving innovation in their respective fields.
Handling Date and Time Data in Python
Date and time data are essential in data analysis, reporting, and scheduling tasks. Python’s datetime and arrow libraries offer comprehensive tools for manipulating and formatting date and time data, ensuring accurate and consistent representation of temporal information.
Python’s built-in datetime module provides classes for handling dates, times, and timestamps. The datetime class combines date and time information, while the date and time classes (date and time) store only date or time components, respectively. The timedelta class represents time durations, enabling calculations such as date arithmetic and time difference calculations.
For more advanced date and time manipulations, the arrow library offers a more user-friendly and flexible API. Arrow supports various date and time formats, time zones, and parsing options, making it an ideal choice for handling complex date and time data.
When working with date and time data, it is crucial to consider time zones, daylight saving time adjustments, and potential data inconsistencies. Python’s pytz library provides time zone information and support, ensuring accurate time calculations and conversions. By employing these libraries and best practices, data professionals can effectively manage and analyze date and time data in Python, enhancing their data analysis capabilities and delivering valuable insights.
Visualizing Data with Python
Data visualization is a crucial aspect of data analysis and communication, enabling data professionals to present complex data in an intuitive, engaging, and easily digestible format. Python’s matplotlib, seaborn, and plotly libraries provide a wide range of visualization options for different data types, helping to reveal patterns, trends, and correlations that might otherwise go unnoticed.
Matplotlib is a versatile and widely-used data visualization library in Python, offering a variety of plot types, such as line charts, scatter plots, bar charts, and histograms. Matplotlib’s simple and consistent API allows users to create high-quality visualizations with minimal effort, making it an ideal choice for beginners and experts alike.
Seaborn is a statistical data visualization library built on top of Matplotlib, providing a higher-level interface for creating informative and attractive visualizations. Seaborn emphasizes the importance of aesthetics and best practices in data visualization, offering a range of pre-defined themes, color palettes, and styles. Seaborn’s heatmaps, pairplots, and distribution plots are particularly useful for exploring relationships between variables in large datasets.
Plotly is an interactive data visualization library that supports creating web-based visualizations, enabling users to create, customize, and share interactive plots, charts, and maps. Plotly’s API is flexible and supports various programming languages, including Python, R, and Julia. By incorporating interactivity into visualizations, data professionals can engage their audience, reveal hidden insights, and facilitate better decision-making.
In summary, Python’s data visualization libraries, such as Matplotlib, Seaborn, and Plotly, empower data professionals to create compelling visualizations that reveal insights, engage audiences, and facilitate informed decision-making. By mastering these libraries and best practices, data professionals can unlock the full potential of data visualization and deliver valuable insights to their organizations and clients.
Storing and Retrieving Data in Python
Effective data storage and retrieval are vital for managing large datasets and long-term projects. Python’s SQLAlchemy, SQLite, and MongoEngine libraries support various database management systems and file formats, ensuring seamless data integration and access.
SQLAlchemy is a popular Object-Relational Mapping (ORM) library for Python, enabling developers to interact with relational databases, such as MySQL, PostgreSQL, and SQLite, using Python objects. SQLAlchemy simplifies the process of defining database schemas, executing queries, and managing database connections, making it an ideal choice for working with structured data.
SQLite is a lightweight, file-based relational database management system that stores data in a single file. Python’s sqlite3 library provides a simple and efficient interface for working with SQLite databases, allowing developers to create, modify, and query databases using familiar SQL syntax. SQLite is an excellent choice for small- to medium-sized projects, as it offers fast and reliable data storage without the need for external dependencies or setup.
MongoEngine is a Python Object-Document Mapper (ODM) for working with NoSQL databases, specifically MongoDB. MongoDB is a document-oriented database that stores data in JSON-like documents, enabling flexible and dynamic schema design. MongoEngine simplifies the process of working with MongoDB by providing a high-level, Pythonic API for defining documents, executing queries, and managing database connections. MongoEngine is particularly useful for handling hierarchical, nested, or unstructured data, as it allows for dynamic schema evolution and efficient data retrieval.
In summary, Python’s SQLAlchemy, SQLite, and MongoEngine libraries provide powerful tools for storing and retrieving data, ensuring seamless data integration and access for various database management systems and file formats. By mastering these libraries and best practices, data professionals can efficiently manage large datasets and long-term projects, delivering valuable insights and driving informed decision-making.
Applying Machine Learning to Data in Python
Machine learning is a powerful technique for uncovering hidden patterns and relationships in data. Python’s scikit-learn, TensorFlow, and Keras libraries offer a wide range of machine learning algorithms and tools for data analysis, enabling data professionals to build predictive models, classify data, and gain valuable insights.
Scikit-learn is a widely-used machine learning library for Python, providing a unified interface for various machine learning algorithms, such as linear regression, logistic regression, decision trees, random forests, and support vector machines. Scikit-learn’s simple and consistent API, along with its focus on best practices and performance, makes it an ideal choice for beginners and experts alike.
TensorFlow is an open-source machine learning framework developed by Google, offering a flexible platform for designing, training, and deploying machine learning models. TensorFlow supports various machine learning techniques, including deep learning, enabling data professionals to build complex and powerful models for tasks such as image recognition, natural language processing, and time series forecasting.
Keras is a high-level neural networks API, running on top of TensorFlow, Theano, or CNTK. Keras simplifies the process of designing and training deep learning models, offering a user-friendly, Pythonic API for building and customizing neural networks. Keras’ modular design and extensibility make it an excellent choice for rapid prototyping and experimentation in deep learning.
In summary, Python’s scikit-learn, TensorFlow, and Keras libraries provide robust and versatile tools for applying machine learning to data, enabling data professionals to build predictive models, classify data, and gain valuable insights. By mastering these libraries and best practices, data professionals can unlock the full potential of machine learning and deliver actionable insights to their organizations and clients.
Data Best Practices and Guidelines in Python
Adhering to best practices and guidelines ensures data integrity, reproducibility, and collaboration. This section covers essential data management principles, such as data versioning, documentation, and testing, enabling data professionals to maintain high-quality data and code.
Data Versioning
Data versioning is the process of tracking and managing changes to datasets over time, allowing data professionals to revert to previous versions if necessary. Tools like Git and DVC (Data Version Control) enable version control for data files, ensuring that changes are traceable and reproducible.
Documentation
Documentation is crucial for ensuring that data and code are easily understood by other team members or future collaborators. Clear, concise, and well-organized documentation should include information about data sources, data transformations, and code functionality. Tools like Sphinx, Google Docs, and ReadTheDocs can help create and manage documentation.
Testing
Testing is an essential aspect of data management, ensuring that code and data transformations function as intended. Unit tests, integration tests, and regression tests can help identify and address issues early in the development process. Python’s unittest and pytest libraries provide robust testing frameworks for data-related projects.
Collaboration
Collaboration is vital for successful data projects, as it enables teams to share knowledge, skills, and resources. Tools like GitHub, GitLab, and Bitbucket facilitate collaboration by providing version control, issue tracking, and code review capabilities. Additionally, platforms like Google Colab and Jupyter Notebook support real-time collaboration and code sharing, streamlining the development process.
In summary, data best practices and guidelines, such as data versioning, documentation, testing, and collaboration, are essential for maintaining data integrity, reproducibility, and collaboration. By incorporating these principles into data-related projects, data professionals can ensure high-quality data and code, driving informed decision-making and delivering value to their organizations and clients.
