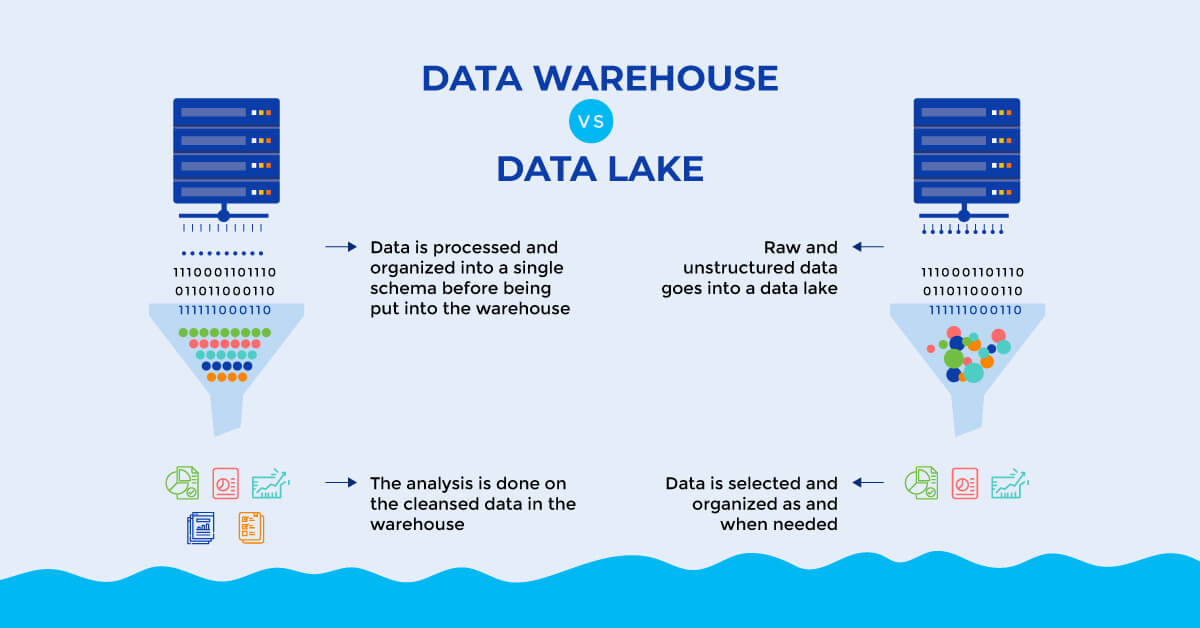
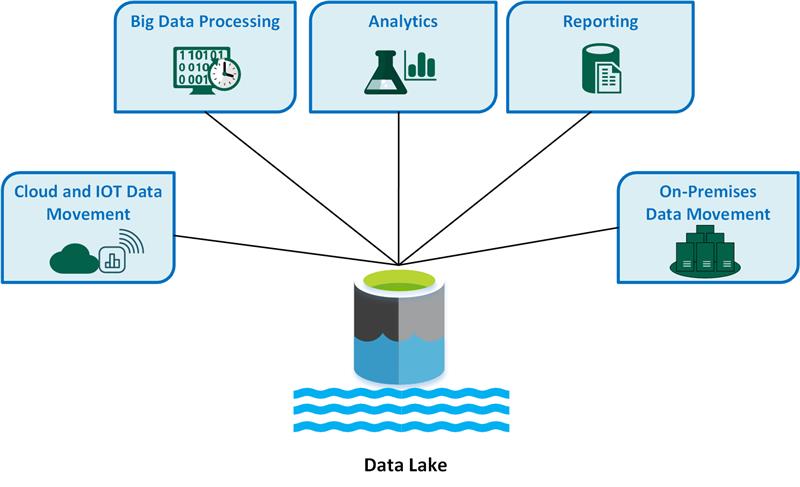
A data lake is a centralized, scalable, and flexible data management system that stores and manages large volumes of structured and unstructured data. Unlike traditional data storage systems, data lakes provide a more cost-effective and efficient way to store and process data, enabling organizations to gain valuable insights from their data and make informed business decisions. The importance of data lakes lies in their ability to handle the increasing volume, variety, and velocity of data generated by modern businesses, providing a single source of truth for data analytics and reporting.
Data lakes offer several advantages over traditional data storage systems, including scalability, flexibility, and cost-effectiveness. Scalability allows data lakes to handle large volumes of data, while flexibility enables them to store and process various data types, such as structured, semi-structured, and unstructured data. Cost-effectiveness is achieved through the use of open-source technologies and commodity hardware, reducing the overall cost of data storage and processing.
In summary, data lakes are an essential component of modern data management systems, providing a scalable, flexible, and cost-effective way to store and process large volumes of data. By gaining valuable insights from their data, organizations can make informed business decisions, improve operational efficiency, and gain a competitive advantage in their industry.
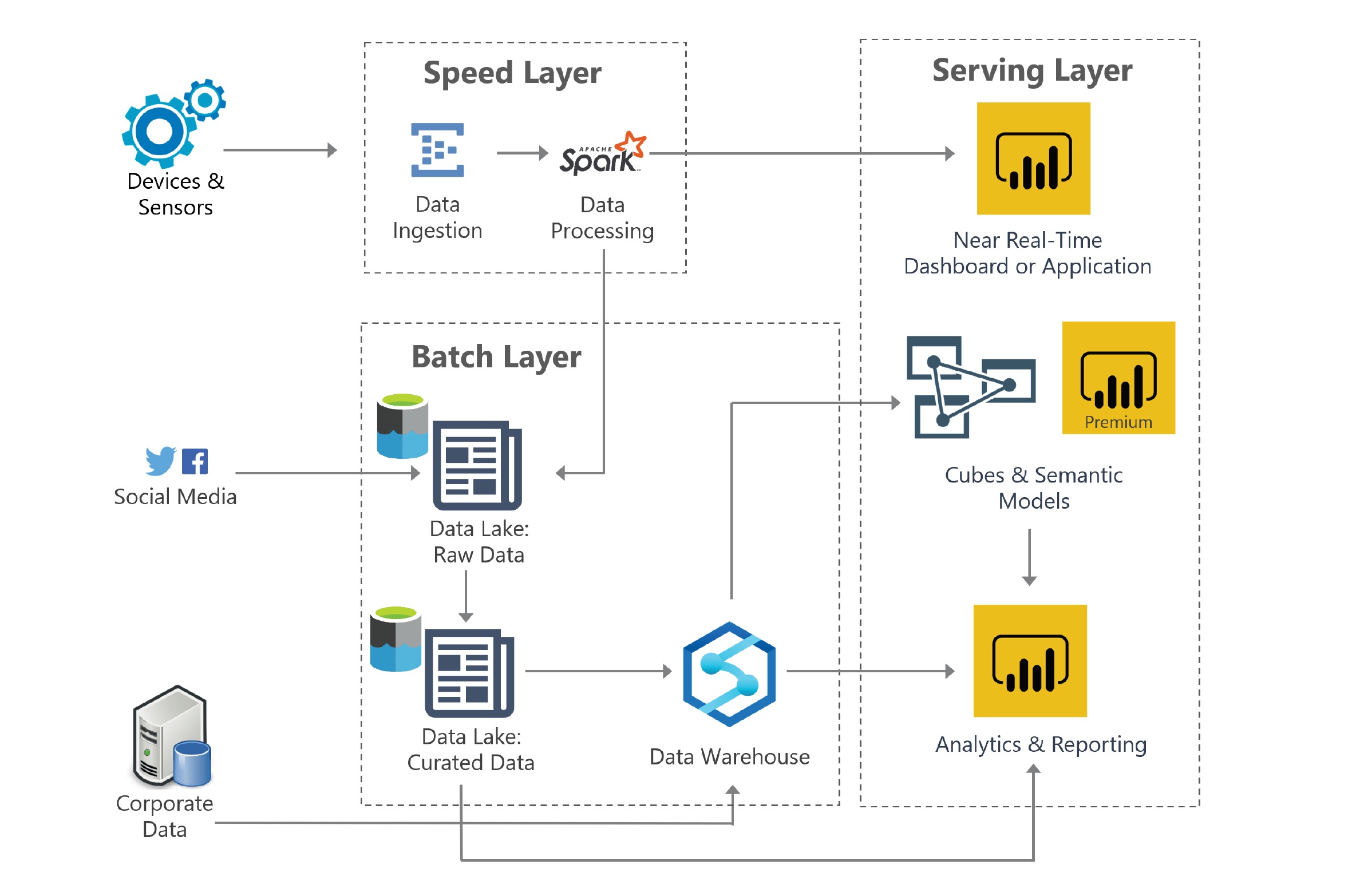
Key Components of a Data Lake Architecture
A data lake architecture consists of several key components that work together to create a seamless data management system. These components include data ingestion, data storage, data processing, and data access. Understanding these components and how they interact is essential for building and maintaining a successful data lake.
Data Ingestion
Data ingestion is the process of collecting and transferring data from various sources into the data lake. Data can be ingested in real-time or in batches, depending on the data source and the business requirements. Data ingestion techniques include batch processing, stream processing, and change data capture. Each technique has its advantages and disadvantages, and the choice of technique depends on the specific use case and the data source.
Data Storage
Data storage is the process of storing and organizing data in the data lake. Data can be stored in a variety of formats, including structured, semi-structured, and unstructured data. Data storage technologies include Hadoop Distributed File System (HDFS), Amazon Simple Storage Service (S3), and Microsoft Azure Data Lake Storage. The choice of data storage technology depends on the specific use case, the data volume, and the data access requirements.
Data Processing
Data processing is the process of transforming and enriching data in the data lake. Data processing techniques include SQL, NoSQL, and Hadoop. SQL is used for structured data processing, while NoSQL is used for unstructured data processing. Hadoop is used for distributed data processing, enabling the processing of large volumes of data in parallel. The choice of data processing technique depends on the specific use case, the data type, and the data processing requirements.
Data Access
Data access is the process of accessing and analyzing data in the data lake. Data access technologies include Apache Hive, Apache Pig, and Apache Spark. These technologies provide a variety of data access methods, including SQL, NoSQL, and machine learning. The choice of data access technology depends on the specific use case, the data type, and the data access requirements.
In summary, a data lake architecture consists of several key components, including data ingestion, data storage, data processing, and data access. Understanding these components and how they interact is essential for building and maintaining a successful data lake. By choosing the right tools and techniques for each component, organizations can create a seamless data management system that provides valuable insights and drives business value.
Setting Up Your Data Lake: A Step-by-Step Guide
Setting up a data lake can seem like a daunting task, but with the right tools and a clear plan, it can be a straightforward process. In this section, we will provide a step-by-step guide on how to set up a data lake, including choosing the right tools, configuring the architecture, and testing the system.
Step 1: Define Your Requirements
The first step in setting up a data lake is to define your requirements. This includes identifying the data sources, the data volume, the data types, and the data access requirements. By defining your requirements upfront, you can ensure that you choose the right tools and configure the architecture to meet your specific needs.
Step 2: Choose the Right Tools
The next step is to choose the right tools for your data lake. This includes selecting a data storage technology, a data processing engine, and a data access layer. Some popular data lake tools include Hadoop, Apache Spark, and Amazon S3. When choosing tools, consider factors such as scalability, flexibility, and cost-effectiveness.
Step 3: Configure the Architecture
Once you have chosen your tools, the next step is to configure the data lake architecture. This includes setting up the data storage, data processing, and data access components. When configuring the architecture, ensure that the components are integrated seamlessly and that the system is optimized for performance.
Step 4: Test the System
After configuring the architecture, the next step is to test the system. This includes loading data into the data lake, processing the data, and accessing the data through the data access layer. Testing the system ensures that it is functioning correctly and that it meets your specific requirements.
Step 5: Monitor and Optimize the System
Once the data lake is up and running, the final step is to monitor and optimize the system. This includes monitoring system performance, troubleshooting issues, and scaling the system as needed. Regular maintenance and optimization ensure that the data lake continues to meet your specific needs and provides valuable insights for your business.
In summary, setting up a data lake involves defining your requirements, choosing the right tools, configuring the architecture, testing the system, and monitoring and optimizing the system. By following these steps, you can create a successful data lake that provides valuable insights and drives business value. Remember to choose tools that are scalable, flexible, and cost-effective, and to optimize the system for performance and efficiency.
Populating Your Data Lake: Data Ingestion Techniques
Populating a data lake is the process of loading data into the system for storage and analysis. There are several data ingestion techniques available, each with its advantages and disadvantages. In this section, we will discuss various data ingestion techniques, including batch processing, stream processing, and change data capture, and provide examples of when to use each technique.
Batch Processing
Batch processing is the traditional method of data ingestion, where data is collected and processed in batches at regular intervals. This technique is useful when dealing with large volumes of data that do not require real-time processing. Batch processing is also useful when dealing with data sources that are not available in real-time, such as log files or social media data.
Stream Processing
Processing Data in a Data Lake: Tools and Techniques
Data processing is a critical component of a data lake architecture. Once data has been ingested into the system, it needs to be processed and transformed into a usable format for analysis. In this section, we will introduce various data processing tools and techniques, including SQL, NoSQL, and Hadoop, and explain how they can be used to transform and enrich data in a data lake.
SQL
SQL (Structured Query Language) is a standard language for managing and manipulating relational databases. SQL is a powerful tool for processing structured data in a data lake, allowing users to perform complex queries and transformations on large datasets. SQL is also useful for integrating data from multiple sources, as it provides a standardized way to access and manipulate data.
NoSQL
NoSQL (Not Only SQL) is a term used to describe non-relational databases that are designed to handle large volumes of unstructured or semi-structured data. NoSQL databases are useful for storing and processing data that does not fit neatly into a relational model, such as JSON or XML data. NoSQL databases provide flexible schema design, allowing users to store and retrieve data in a variety of formats.
Hadoop
Hadoop is an open-source framework for distributed data processing. Hadoop provides a scalable and cost-effective way to process large volumes of data, allowing users to perform complex transformations and analyses on data stored in a data lake. Hadoop includes several tools for data processing, including MapReduce, Hive, and Pig.
Examples of When to Use Each Tool
SQL is best suited for processing structured data, such as data stored in a relational database. NoSQL is best suited for storing and processing unstructured or semi-structured data, such as data stored in a JSON or XML format. Hadoop is best suited for processing large volumes of data, such as data stored in a data lake.
In conclusion, data processing is a critical component of a data lake architecture. SQL, NoSQL, and Hadoop are powerful tools for processing and transforming data in a data lake. By understanding the strengths and weaknesses of each tool, data engineers can choose the right tool for the job and ensure that their data lake is optimized for performance and efficiency.
Securing Your Data Lake: Best Practices and Strategies
Data security is a critical concern for any organization that handles sensitive data. Data lakes, which store large volumes of data, are no exception. In this section, we will discuss the importance of data security in a data lake, and provide best practices and strategies for securing the system. We will also mention the role of access control, encryption, and auditing in maintaining data security.
Access Control
Access control is the process of managing who has access to the data lake and what level of access they have. Access control can be implemented using a variety of techniques, including role-based access control (RBAC), attribute-based access control (ABAC), and discretionary access control (DAC). By implementing access control, organizations can ensure that only authorized users have access to sensitive data, reducing the risk of data breaches and unauthorized access.
Encryption
Encryption is the process of converting data into a code to prevent unauthorized access. Encryption can be used to protect data at rest, data in transit, and data in use. By encrypting data, organizations can ensure that even if data is intercepted or accessed by unauthorized users, it will be unreadable and useless. Encryption can be implemented using a variety of techniques, including symmetric encryption and asymmetric encryption.
Auditing
Auditing is the process of monitoring and recording data lake activity to detect and respond to security threats. Auditing can be used to track user activity, identify suspicious behavior, and investigate security incidents. By implementing auditing, organizations can ensure that they have a complete record of all data lake activity, making it easier to detect and respond to security threats.
Best Practices and Strategies
To ensure the security of a data lake, organizations should follow best practices and strategies, including:
Implementing access control, encryption, and auditing to protect data at rest, data in transit, and data in use.
Regularly monitoring and reviewing data lake activity to detect and respond to security threats.
Providing training and awareness programs to educate users on data security best practices.
Regularly testing and updating data lake security measures to ensure that they are effective and up-to-date.
In conclusion, data security is a critical concern for any organization that handles sensitive data. By implementing access control, encryption, and auditing, organizations can ensure that their data lakes are secure and protected from unauthorized access and data breaches. By following best practices and strategies, organizations can ensure that their data lakes are optimized for performance, efficiency, and security.
Maintaining and Optimizing Your Data Lake: Tips and Tricks
Maintaining and optimizing a data lake is essential to ensure its long-term success. In this section, we will provide tips and tricks for maintaining and optimizing a data lake, including monitoring system performance, troubleshooting issues, and scaling the system as needed. By following these best practices, organizations can ensure that their data lakes are running smoothly, efficiently, and securely.
Monitoring System Performance
Monitoring system performance is critical to ensuring that the data lake is running optimally. By monitoring system performance, organizations can detect and address issues before they become major problems. Some key performance metrics to monitor include CPU usage, memory usage, disk usage, and network traffic. By monitoring these metrics, organizations can identify bottlenecks, optimize system performance, and prevent system failures.
Troubleshooting Issues
Troubleshooting issues is an essential part of maintaining a data lake. By identifying and addressing issues promptly, organizations can prevent system failures and data loss. Some common issues that can arise in a data lake include data corruption, data loss, and system failures. By implementing a robust troubleshooting process, organizations can quickly identify and address these issues, minimizing downtime and ensuring data integrity.
Scaling the System
Scaling the system is critical to ensuring that the data lake can handle increasing data volumes and user demands. By scaling the system, organizations can ensure that the data lake can handle growing data volumes and user demands without compromising system performance or data integrity. Some common scaling techniques include horizontal scaling, vertical scaling, and distributed computing.
Best Practices and Strategies
To maintain and optimize a data lake, organizations should follow best practices and strategies, including:
Monitoring system performance regularly to detect and address issues before they become major problems.
Implementing a robust troubleshooting process to quickly identify and address issues.
Scaling the system as needed to handle increasing data volumes and user demands.
Implementing regular backups and disaster recovery plans to ensure data integrity and availability.
Regularly testing and updating data lake security measures to ensure that they are effective and up-to-date.
In conclusion, maintaining and optimizing a data lake is essential to ensure its long-term success. By monitoring system performance, troubleshooting issues, and scaling the system as needed, organizations can ensure that their data lakes are running smoothly, efficiently, and securely. By following best practices and strategies, organizations can ensure that their data lakes are optimized for performance, efficiency, and security.
Real-World Data Lake Use Cases: Success Stories and Lessons Learned
Data lakes have become increasingly popular in recent years, and many organizations have successfully implemented them to drive business value. In this section, we will discuss real-world data lake use cases, highlighting success stories and lessons learned. By examining these use cases, organizations can gain insights into how data lakes can be used to drive business value and the key factors that contribute to a successful implementation.
Healthcare
Healthcare organizations have been using data lakes to improve patient outcomes and reduce costs. For example, one healthcare organization used a data lake to analyze patient data and identify patterns that could predict patient readmissions. By using this information to proactively intervene, the organization was able to reduce readmissions by 20%. Another healthcare organization used a data lake to analyze patient data and identify high-risk patients, allowing them to provide targeted interventions and improve patient outcomes.
Finance
Financial institutions have been using data lakes to improve fraud detection and risk management. For example, one financial institution used a data lake to analyze transaction data and identify patterns that could indicate fraudulent activity. By using this information to proactively intervene, the organization was able to reduce fraud by 30%. Another financial institution used a data lake to analyze risk data and identify potential risks, allowing them to proactively manage risk and reduce losses.
Retail
Retail organizations have been using data lakes to improve customer engagement and sales. For example, one retail organization used a data lake to analyze customer data and identify patterns that could indicate customer preferences. By using this information to personalize marketing campaigns, the organization was able to increase sales by 20%. Another retail organization used a data lake to analyze sales data and identify trends, allowing them to optimize inventory and reduce costs.
Defining clear business objectives and use cases for the data lake.
Choosing the right tools and technologies for the data lake architecture.
Implementing robust data governance and security measures.
Regularly monitoring and optimizing the data lake to ensure its long-term success.
Providing training and support to users to ensure they can effectively use the data lake.
In conclusion, data lakes have become increasingly popular in recent years, and many organizations have successfully implemented them to drive business value. By examining real-world use cases, organizations can gain insights into how data lakes can be used to drive business value and the key factors that contribute to a successful implementation. By following best practices and lessons learned, organizations can ensure a successful data lake implementation and drive business value for years to come.