
What is AWS Glue and Why Should You Care?
AWS Glue is a fully managed Extract, Transform, and Load (ETL) service that simplifies the process of preparing and loading data for analytics, machine learning, and application development. As a serverless and scalable solution, AWS Glue helps organizations efficiently handle their data processing needs without the hassle of managing infrastructure. The service is designed to automate and simplify various aspects of ETL operations, allowing data engineers, data scientists, and developers to focus on deriving insights and building data-driven applications.
The core components of AWS Glue include the Database Catalog, Crawlers, Jobs, and Triggers. The Database Catalog serves as a central repository for metadata, storing information about data stores, tables, and relationships. Crawlers automatically scan data stores, identify data formats, and populate the Database Catalog with new and updated metadata. Jobs are the actual ETL processes that extract data from sources, transform it according to specified rules, and load it into target data stores. Triggers automate job scheduling and execution based on events or time-based schedules.
When it comes to aws glue examples, there are numerous use cases that demonstrate the power and versatility of this service. For instance, AWS Glue can be used to:
- Integrate data from various sources, such as relational databases, NoSQL databases, and SaaS applications, into a centralized data lake for analytics and machine learning.
- Cleanse and standardize data, ensuring consistency and accuracy across data sources.
- Transform data into formats suitable for specific analytics tools, such as data marts or data warehouses.
- Automate data workflows, reducing manual intervention and minimizing the risk of errors.
- Monitor and manage data pipelines, ensuring optimal performance and resource utilization.
By leveraging AWS Glue, organizations can unlock the true potential of their data, enabling data-driven decision-making and fueling innovation.

Getting Started with AWS Glue: A Gentle Introduction
AWS Glue is a fully managed ETL service that simplifies the process of preparing and loading data for analytics, machine learning, and application development. The service comprises several components that work together to extract, transform, and load data. These components include the Database Catalog, Crawlers, Jobs, and Triggers.
The Database Catalog is a central repository that stores metadata about data stores, tables, and relationships. It enables AWS Glue to manage and discover data across various data stores, such as Amazon S3, Amazon Redshift, and Amazon RDS. The Database Catalog also provides a unified metadata view, making it easier to manage and query data.
Crawlers are automated scripts that scan data stores and identify data formats, schema, and other metadata. They populate the Database Catalog with this information, ensuring that the metadata is always up-to-date. Crawlers can be scheduled to run at regular intervals or triggered by events, such as the availability of new data.
Jobs are the actual ETL processes that extract data from sources, transform it according to specified rules, and load it into target data stores. Jobs can be created using the AWS Glue Visual Job Editor or by writing code in Python or Scala. Jobs can be scheduled to run at specific times or triggered by events, such as the completion of a previous job or the availability of new data.
Triggers are automated events that initiate jobs based on specific conditions. For example, a trigger can be set up to start a job when new data is available in a source data store or when a previous job has completed successfully. Triggers can also be used to schedule jobs to run at regular intervals.
When working with aws glue examples, understanding these components and how they work together is crucial for building effective ETL pipelines. By leveraging the power of AWS Glue, organizations can streamline their data processing workflows, enabling data-driven decision-making and fueling innovation.
Transforming Data with AWS Glue: Hands-On Examples
AWS Glue provides a powerful and flexible environment for transforming data to meet various business requirements. In this section, we’ll explore some common data transformations using AWS Glue, including filtering, aggregating, and joining data.
Filtering Data
Filtering is a process of selecting a subset of data based on specific conditions. In AWS Glue, you can use the Filter transformation to achieve this. For example, you can filter sales data to include only transactions that occurred in a specific region or during a particular time frame.
Aggregating Data
Aggregating data involves combining data points to provide summary information. AWS Glue supports various aggregation functions, such as count, sum, avg, min, and max. You can use the GroupBy transformation to group data based on specific columns and then apply aggregation functions.
Joining Data
Joining data is the process of combining data from two or more tables based on a common column or set of columns. AWS Glue supports various join types, such as inner, left outer, right outer, and full outer joins. You can use the Join transformation to combine data from different sources.
In the following example, we’ll demonstrate how to filter, aggregate, and join data using AWS Glue:
Example: Filtering, Aggregating, and Joining Data
Suppose we have two datasets: sales and products. The sales dataset contains sales transactions, while the products dataset contains product information.
sales: transaction\_id, product\_id, region, price, quantity, timestampproducts: product\_id, product\_name, category, price
Our goal is to calculate the total sales revenue for each product category in a specific region.
To achieve this, we’ll perform the following steps:
- Filter the
salesdataset to include only transactions from a specific region. - Join the filtered
salesdataset with theproductsdataset based on theproduct\_idcolumn. - Calculate the total revenue for each product category by aggregating the price and quantity columns.
- Use descriptive names for triggers to make them easy to identify and manage.
- Specify a retries policy for triggers to handle failures and ensure that jobs are retried as needed.
- Monitor trigger logs to diagnose and troubleshoot issues with data pipelines.
- Use event-based triggers to respond to changes in data sources and ensure timely processing of data.
- Use the appropriate instance type and size for your jobs. AWS Glue provides a variety of instance types and sizes to choose from, each with different compute, memory, and network capabilities. Choose the instance type and size that best meets your job’s requirements.
- Use the minimum number of workers required to complete the job. AWS Glue allows you to specify the number of workers for your job. Use the minimum number of workers required to complete the job, as additional workers can increase costs without providing significant benefits.
- Use job bookmarks to skip processed data. Job bookmarks allow you to save the last processed record for a job, so you can skip processed data in subsequent runs. By using job bookmarks, you can reduce processing time and costs.
- Use AWS Glue metrics to monitor job performance. AWS Glue provides a variety of metrics, such as CPU utilization, memory usage, and network traffic, that you can use to monitor job performance. Use these metrics to identify performance bottlenecks and optimize your jobs.
- Use CloudWatch logs to diagnose issues. AWS Glue integrates with CloudWatch, which allows you to view logs and diagnose issues. Use CloudWatch logs to identify errors, warnings, and other issues that may affect job performance.
- Use the AWS Glue visual job editor to debug issues. The visual job editor allows you to see the flow of data through your job and identify issues. Use the visual job editor to debug issues and optimize your job.
- Use the AWS Glue error log to diagnose issues. AWS Glue provides an error log that you can use to diagnose issues. Use the error log to identify errors, warnings, and other issues that may affect job performance.
- Use encryption to protect data at rest and in transit. AWS Glue supports encryption using AWS Key Management Service (KMS) and SSL/TLS.
- Use AWS Identity and Access Management (IAM) to control access to AWS Glue resources. Use IAM roles and policies to grant access to specific users and groups.
- Use AWS CloudTrail to monitor API calls and user activity. AWS CloudTrail provides detailed logs of API calls and user activity, which can be used to detect and respond to security threats.
- Use AWS Glue Data Catalog to manage metadata. AWS Glue Data Catalog provides a central repository for metadata, which can be used to discover, understand, and manage data.
- Use AWS Glue Crawlers to automatically discover and catalog data. AWS Glue Crawlers can automatically discover and catalog data from a variety of sources, including Amazon S3, Amazon RDS, and Amazon DynamoDB.
- Use AWS Glue Classifiers to classify data. AWS Glue Classifiers can be used to classify data based on specific criteria, such as data type, format, and schema.
- Use AWS Glue Data Catalog to manage metadata. AWS Glue Data Catalog provides a central repository for metadata, which can be used to demonstrate compliance with data regulations.
- Use AWS Glue Crawlers to automatically discover and catalog data. AWS Glue Crawlers can automatically discover and catalog data from a variety of sources, including Amazon S3, Amazon RDS, and Amazon DynamoDB.
- Use AWS Glue Classifiers to classify data. AWS Glue Classifiers can be used to classify data based on specific criteria, such as data type, format, and schema.
The following code snippet demonstrates how to implement this using AWS Glue:
# Filter sales dataset filtered_sales = sales_dyf.filter(sales_dyf.region == 'us-west-2')
Join sales and products datasets
joined_data = Join.apply(
filtered_sales,
products_dyf,
'product_id',
'product_id'
)
Aggregate data by category
aggregated_data = Aggregate.apply(
grouped_data,
'category',
[
Aggregate.avg('price'),
Aggregate.sum('quantity' * 'price')
],
'category',
'avg_price',
'total_revenue'
)
Display the result
print(aggregated_data.toDF().show())
This example demonstrates how to filter, aggregate, and join data using AWS Glue. By mastering these techniques, you can unlock the full potential of AWS Glue for data transformation and preparation.

Automating Data Pipelines with AWS Glue Triggers
AWS Glue Triggers provide a powerful mechanism for automating data pipelines. Triggers enable you to schedule jobs and respond to events, such as the completion of a previous job or the availability of new data. By automating data pipelines, you can improve efficiency, reduce errors, and ensure timely processing of data.
Scheduling Jobs with AWS Glue Triggers
You can schedule AWS Glue jobs to run at specific times or intervals using triggers. To schedule a job, you can create a new trigger and specify the schedule using a cron expression. For example, the following cron expression schedules a job to run every day at 6 AM:
0 6 * * ? Once the trigger is created, it will automatically start the specified job at the scheduled time.
Responding to Events with AWS Glue Triggers
In addition to scheduling jobs, you can also use triggers to respond to events, such as the completion of a previous job or the availability of new data. To create an event-based trigger, you can specify the event source and the action that should trigger the job. For example, you can create a trigger that starts a job when a specific S3 bucket is updated with new data.
Managing AWS Glue Triggers
You can manage AWS Glue triggers using the AWS Management Console, AWS CLI, or AWS SDKs. You can view the status of triggers, modify their settings, and disable or enable them as needed. By managing triggers effectively, you can ensure that your data pipelines are running smoothly and efficiently.
AWS Glue Triggers Best Practices
In summary, AWS Glue Triggers provide a powerful mechanism for automating data pipelines. By scheduling jobs and responding to events, you can improve efficiency, reduce errors, and ensure timely processing of data. By following best practices for managing triggers, you can ensure that your data pipelines are running smoothly and efficiently.
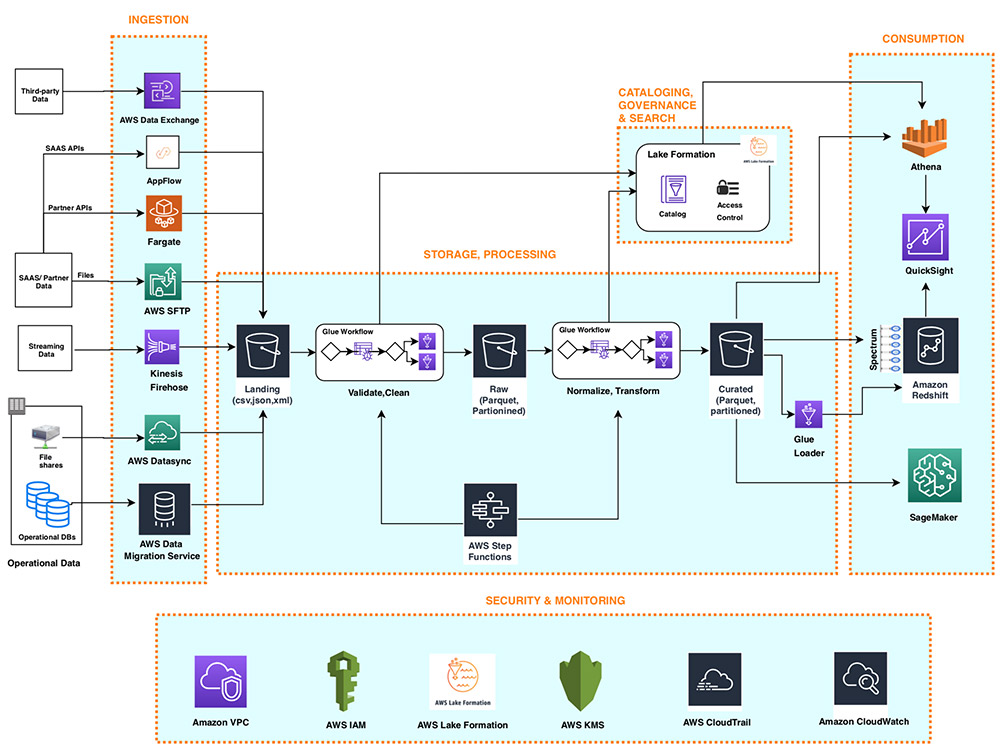
Scaling and Optimizing AWS Glue Jobs for Production
As your data processing needs grow, it’s essential to scale and optimize your AWS Glue jobs for production. By following best practices for managing resources, monitoring performance, and troubleshooting issues, you can ensure that your data pipelines are running smoothly and efficiently.
Managing Resources
When running AWS Glue jobs in production, it’s essential to manage resources effectively. Here are some best practices for managing resources:
Monitoring Performance
Monitoring the performance of your AWS Glue jobs is essential for identifying and troubleshooting issues. Here are some best practices for monitoring performance:
Troubleshooting Issues
Troubleshooting issues with AWS Glue jobs is essential for maintaining efficient data pipelines. Here are some best practices for troubleshooting issues:
In summary, scaling and optimizing AWS Glue jobs for production is essential for maintaining efficient data pipelines. By following best practices for managing resources, monitoring performance, and troubleshooting issues, you can ensure that your data pipelines are running smoothly and efficiently. By incorporating these best practices, you can unlock the full potential of AWS Glue for data processing and analytics.
Integrating AWS Glue with Other AWS Services
AWS Glue is a powerful ETL service that can integrate with a variety of other AWS services to prepare data for analytics, machine learning, and application development. By using AWS Glue in conjunction with other AWS services, you can unlock the full potential of your data and gain valuable insights.
Amazon S3
Amazon S3 is a highly scalable and durable object storage service that is commonly used as a data lake for storing large amounts of data. AWS Glue can extract data from Amazon S3, transform it, and load it into other data stores or analytics services. For example, you can use AWS Glue to extract data from Amazon S3, transform it using a Python or Scala script, and then load it into Amazon Redshift for analytics.
Amazon Redshift
Amazon Redshift is a fast, fully managed data warehouse service that makes it simple and cost-effective to analyze data using SQL and your existing business intelligence tools. AWS Glue can extract data from a variety of sources, transform it, and load it into Amazon Redshift for analysis. For example, you can use AWS Glue to extract data from multiple Amazon S3 buckets, transform it using a Python or Scala script, and then load it into Amazon Redshift for analysis.
Amazon Athena
Amazon Athena is an interactive query service that makes it easy to analyze data in Amazon S3 using standard SQL. AWS Glue can extract data from a variety of sources, transform it, and load it into Amazon S3 for analysis using Amazon Athena. For example, you can use AWS Glue to extract data from a MySQL database, transform it using a Python or Scala script, and then load it into Amazon S3 for analysis using Amazon Athena.
Machine Learning
AWS Glue can also be used to prepare data for machine learning. For example, you can use AWS Glue to extract data from a variety of sources, transform it using a Python or Scala script, and then load it into Amazon SageMaker for model training and deployment. By using AWS Glue to prepare data for machine learning, you can save time and reduce the complexity of data preparation.
Data Security, Governance, and Compliance
When integrating AWS Glue with other AWS services, it’s essential to consider data security, governance, and compliance. AWS provides a variety of tools and services, such as AWS Identity and Access Management (IAM), AWS Key Management Service (KMS), and AWS CloudTrail, that you can use to secure and govern your data. By using these tools and services, you can ensure that your data is secure, compliant, and meets your organization’s governance requirements.
In summary, AWS Glue is a powerful ETL service that can integrate with a variety of other AWS services to prepare data for analytics, machine learning, and application development. By using AWS Glue in conjunction with other AWS services, you can unlock the full potential of your data and gain valuable insights. By following best practices for data security, governance, and compliance, you can ensure that your data is secure, compliant, and meets your organization’s governance requirements.

Best Practices for Designing and Implementing AWS Glue Solutions
When designing and implementing AWS Glue solutions, it’s essential to follow best practices to ensure that your data processing pipelines are efficient, scalable, and secure. Here are some best practices to consider:
Data Security
Data security is a critical consideration when designing and implementing AWS Glue solutions. Here are some best practices for ensuring data security:
Data Governance
Data governance is another critical consideration when designing and implementing AWS Glue solutions. Here are some best practices for ensuring data governance:
Data Compliance
Data compliance is a critical consideration when designing and implementing AWS Glue solutions. Here are some best practices for ensuring data compliance:
In summary, designing and implementing AWS Glue solutions requires careful consideration of data security, governance, and compliance. By following best practices, you can ensure that your data processing pipelines are efficient, scalable, and secure. By incorporating these best practices, you can unlock the full potential of AWS Glue for data processing and analytics.
Expanding Your Data Processing Capabilities with AWS Glue
AWS Glue is a powerful ETL service that can help organizations expand their data processing capabilities. By using AWS Glue, organizations can unlock the full potential of their data and gain valuable insights. Here are some ways that AWS Glue can help organizations expand their data processing capabilities:
Data Integration
AWS Glue can be used to integrate data from a variety of sources, including on-premises data stores, cloud-based data stores, and SaaS applications. By using AWS Glue, organizations can create a unified view of their data, which can be used for analytics, machine learning, and application development. For example, an organization could use AWS Glue to extract data from a MySQL database, transform it using a Python or Scala script, and then load it into Amazon S3 for analysis using Amazon Athena.
Data Migration
AWS Glue can be used to migrate data from one data store to another. For example, an organization could use AWS Glue to migrate data from an on-premises data store to Amazon S3 or Amazon Redshift. By using AWS Glue, organizations can automate the data migration process, reducing the time and effort required to migrate data.
Data Transformation
AWS Glue can be used to transform data in a variety of ways, including filtering, aggregating, and joining data. By using AWS Glue, organizations can automate the data transformation process, reducing the time and effort required to transform data. For example, an organization could use AWS Glue to filter data based on specific criteria, aggregate data using a specific function, or join data from multiple sources.
Data Preparation for Analytics and Machine Learning
AWS Glue can be used to prepare data for analytics and machine learning. For example, an organization could use AWS Glue to extract data from a variety of sources, transform it using a Python or Scala script, and then load it into Amazon SageMaker for model training and deployment. By using AWS Glue, organizations can automate the data preparation process, reducing the time and effort required to prepare data for analytics and machine learning.
Data Governance and Compliance
AWS Glue can be used to ensure data governance and compliance. For example, an organization could use AWS Glue to manage metadata, automatically discover and catalog data, and classify data based on specific criteria. By using AWS Glue, organizations can ensure that their data is secure, compliant, and meets their governance requirements.
In summary, AWS Glue is a powerful ETL service that can help organizations expand their data processing capabilities. By using AWS Glue, organizations can unlock the full potential of their data and gain valuable insights. By incorporating AWS Glue into their data processing pipelines, organizations can automate the data integration, migration, transformation, preparation, and governance processes, reducing the time and effort required to process data.
