
What is AWS Data Architecture?
AWS (Amazon Web Services) data architecture is a collection of services and tools that enable organizations to build, deploy, and manage secure and scalable data solutions in the cloud. It offers a wide range of data storage and processing services, including Amazon S3, Amazon DynamoDB, Amazon Redshift, Amazon Kinesis, and AWS Glue, among others. These services work together to provide a robust and flexible data architecture that can be customized to meet specific business needs.
In today’s data-driven world, AWS data architecture plays a critical role in modern data management. It allows organizations to collect, store, process, and analyze data in a secure and scalable way, enabling them to make data-driven decisions, improve operational efficiency, and gain a competitive advantage in their respective markets. With its pay-as-you-go pricing model, AWS data architecture offers a cost-effective solution for organizations of all sizes, from startups to large enterprises.
Key Components of AWS Data Architecture
AWS data architecture is composed of several key components that work together to provide a robust and flexible data management solution. These components include:
- Amazon S3: A highly scalable and durable object storage service that enables organizations to store and retrieve large amounts of data from anywhere on the web.
- Amazon DynamoDB: A fast and fully managed NoSQL database service that provides single-digit millisecond performance at any scale.
- Amazon Redshift: A fully managed, petabyte-scale data warehouse service that makes it simple and cost-effective to analyze all of an organization’s data using SQL and standard business intelligence tools.
- Amazon Kinesis: A platform for real-time streaming data processing that enables organizations to ingest, process, and analyze real-time, streaming data such as video, audio, application logs, website clickstreams, and IoT telemetry data for machine learning, analytics, and other applications.
- AWS Glue: A fully managed extract, transform, and load (ETL) service that makes it easy for organizations to move data between data stores.
These components can be used together or separately, depending on the specific needs of the organization. For example, an organization might use Amazon S3 to store large amounts of data, Amazon Redshift to analyze that data, and AWS Glue to move data between Amazon S3 and Amazon Redshift. By using these components together, organizations can create a robust and flexible data architecture that can scale to meet their changing needs.
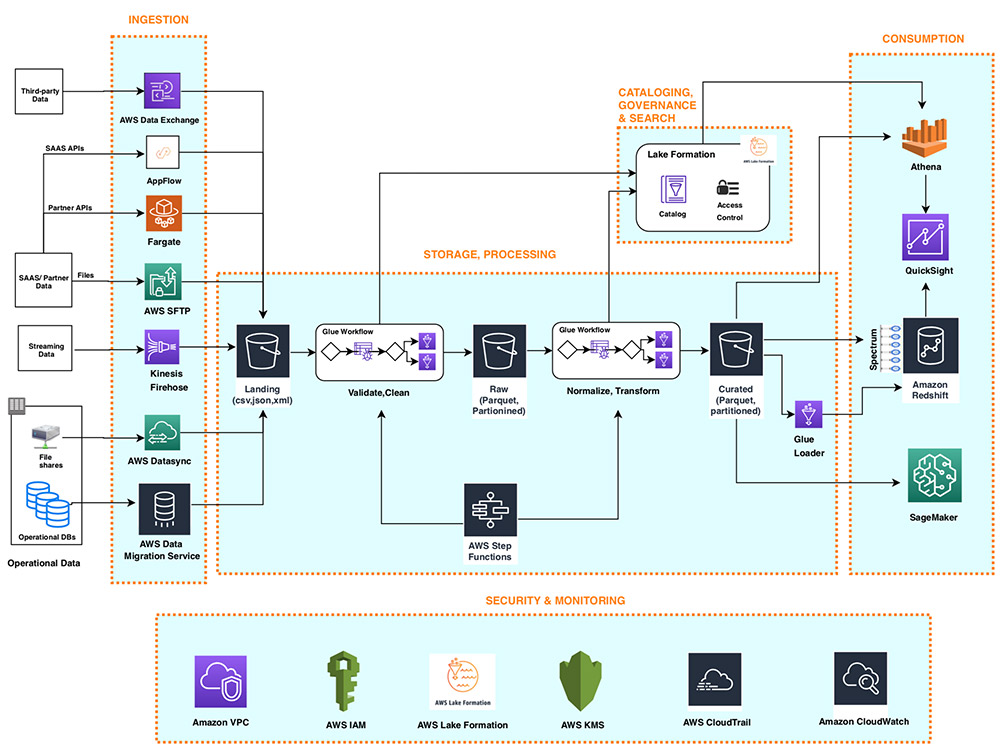
Designing an Effective AWS Data Architecture
Designing an effective AWS data architecture requires careful consideration of several key factors, including data security, scalability, and performance. Here are some best practices to keep in mind when designing your AWS data architecture:
- Data Security: Data security should be a top priority when designing your AWS data architecture. AWS provides several tools and services to help secure your data, including Identity and Access Management (IAM), Key Management Service (KMS), and AWS Certificate Manager. Use these tools to control access to your data, encrypt sensitive data, and manage SSL/TLS certificates.
- Scalability: Scalability is another important consideration when designing your AWS data architecture. AWS provides several highly scalable data storage and processing services, including Amazon S3, Amazon DynamoDB, and Amazon Redshift. Use these services to store and process large volumes of data, and to scale your data architecture up or down as needed to meet changing business requirements.
- Performance: Performance is also critical when designing your AWS data architecture. AWS provides several tools and services to help optimize the performance of your data architecture, including Amazon CloudWatch, AWS X-Ray, and AWS Auto Scaling. Use these tools to monitor the performance of your data architecture, diagnose and troubleshoot performance issues, and automatically scale your data architecture up or down to maintain optimal performance.
When designing your AWS data architecture, it’s important to choose the right data storage and processing services based on your specific use cases and requirements. For example, if you need to store and analyze large volumes of structured data, Amazon Redshift might be the best choice. If you need to store and process large volumes of unstructured data, Amazon S3 might be a better fit. And if you need a highly scalable NoSQL database, Amazon DynamoDB might be the way to go.
How to Migrate Data to AWS Data Architecture
Migrating data to AWS data architecture can be a complex process, but it can also provide significant benefits in terms of scalability, security, and performance. Here’s a step-by-step guide to help you migrate your data to AWS data architecture:
- Data Assessment: The first step in migrating data to AWS data architecture is to assess your current data infrastructure. Identify the data sources, data volumes, and data types that you need to migrate. Evaluate the performance, scalability, and security of your current data infrastructure, and identify any areas for improvement.
- Data Migration Planning: Once you’ve assessed your current data infrastructure, the next step is to plan your data migration. Identify the AWS data storage and processing services that you’ll use to store and process your data. Create a migration plan that outlines the steps you’ll take to migrate your data, including any data transformations or data cleansing that you need to perform.
- Data Migration Execution: With your data migration plan in place, the next step is to execute the migration. Use AWS data migration tools, such as AWS Data Migration Service (DMS) or AWS Database Migration Service (DMS), to migrate your data to AWS data architecture. Monitor the migration process to ensure that it’s proceeding smoothly, and address any issues or errors that arise.
When migrating data to AWS data architecture, there are several tools and services that can help simplify and accelerate the process. For example, AWS Data Migration Service (DMS) can migrate data from a variety of data sources to AWS data storage services, such as Amazon S3 or Amazon DynamoDB. AWS Database Migration Service (DMS) can migrate data from one database platform to another, such as from Oracle to Amazon Aurora.
In addition to these tools and services, AWS also provides several best practices to help ensure a successful data migration. For example, AWS recommends performing a dry run of the migration to identify any issues or errors that might arise. AWS also recommends testing the migration in a non-production environment before migrating data in a production environment.
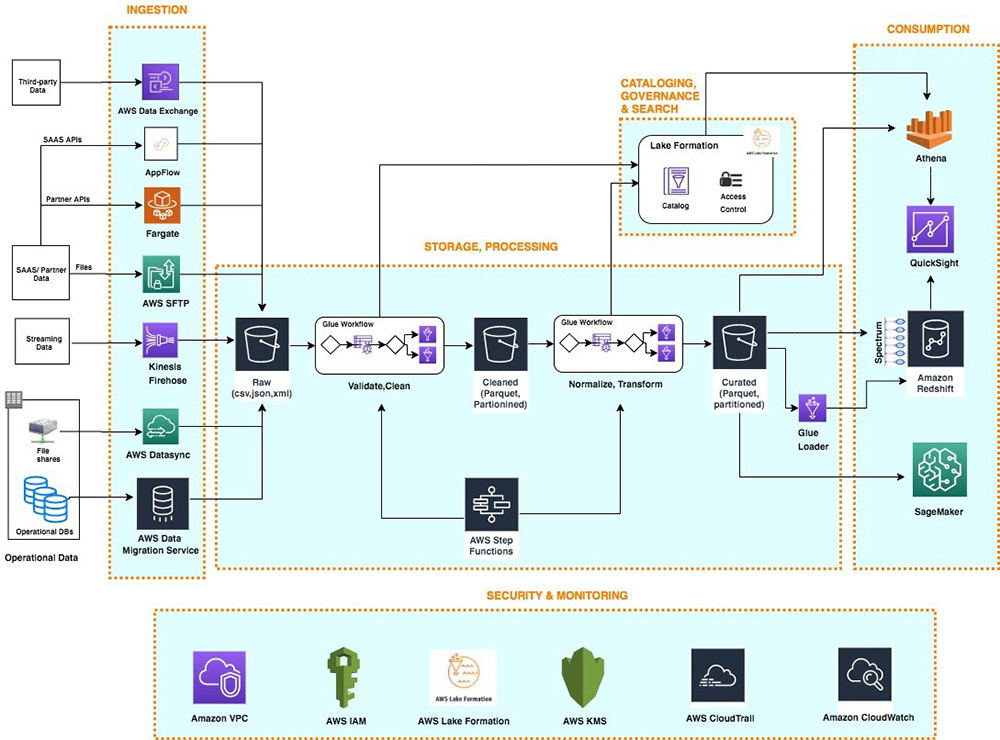
Real-World Examples of AWS Data Architecture
AWS data architecture is being used by organizations across a wide range of industries and domains to achieve their business objectives. Here are some real-world examples of successful AWS data architecture implementations:
- Netflix: Netflix, the world’s leading streaming entertainment service, uses AWS data architecture to store and process massive volumes of data. Netflix uses Amazon S3 to store petabytes of data, including video content, application logs, and metadata. Netflix also uses Amazon DynamoDB to store and process user data, including user profiles, viewing history, and preferences. By using AWS data architecture, Netflix has been able to achieve high levels of scalability, reliability, and performance.
- Airbnb: Airbnb, the world’s largest community-driven hospitality company, uses AWS data architecture to store and process large volumes of data. Airbnb uses Amazon S3 to store and process user data, including user profiles, reservations, and listings. Airbnb also uses Amazon Redshift to store and process data for business intelligence and analytics. By using AWS data architecture, Airbnb has been able to achieve high levels of scalability, security, and performance.
- NASA: NASA, the United States government agency responsible for space exploration, uses AWS data architecture to store and process large volumes of scientific data. NASA uses Amazon S3 to store and process data from space missions, including images, videos, and sensor data. NASA also uses Amazon Glue to extract, transform, and load data into data lakes for analysis and visualization. By using AWS data architecture, NASA has been able to achieve high levels of scalability, security, and performance.
These are just a few examples of how organizations are leveraging AWS data architecture to achieve their business objectives. By using AWS data architecture, these organizations have been able to achieve high levels of scalability, security, and performance, while also reducing costs and improving operational efficiency.
Challenges and Considerations in AWS Data Architecture
While AWS data architecture offers many benefits, it also comes with its own set of challenges and considerations. Here are some of the most common challenges and considerations in AWS data architecture, and how to address them:
- Data Integration: Data integration is the process of combining data from different sources into a unified view. In AWS data architecture, data integration can be challenging due to the variety of data sources and formats. To address this challenge, organizations can use AWS Glue, a fully managed extract, transform, and load (ETL) service that makes it easy to move data between data stores. AWS Glue can automate the process of data integration, reducing the time and effort required to integrate data from different sources.
- Data Governance: Data governance is the process of managing the availability, usability, integrity, and security of data. In AWS data architecture, data governance can be challenging due to the distributed nature of data storage and processing. To address this challenge, organizations can use AWS Lake Formation, a fully managed service that makes it easy to set up a secure data lake. AWS Lake Formation provides a centralized repository for data governance, enabling organizations to manage data access, data quality, and data security in a consistent and scalable way.
- Data Privacy: Data privacy is the process of protecting personal data from unauthorized access and use. In AWS data architecture, data privacy can be challenging due to the large volumes of personal data that are stored and processed. To address this challenge, organizations can use AWS Data Protection, a set of services that help organizations protect personal data in transit and at rest. AWS Data Protection includes services such as AWS Key Management Service (KMS), AWS Certificate Manager, and AWS Secrets Manager, which enable organizations to encrypt, manage, and secure personal data in a scalable and cost-effective way.
By addressing these challenges and considerations, organizations can ensure that their AWS data architecture is secure, scalable, and compliant with industry regulations and standards. With the right approach to data integration, data governance, and data privacy, organizations can leverage AWS data architecture to achieve their business objectives and gain a competitive advantage in their respective markets.

Future Trends in AWS Data Architecture
AWS data architecture is constantly evolving, with new trends and innovations emerging all the time. Here are some of the most exciting future trends in AWS data architecture, and how they are shaping the future of data management and analysis:
- Machine Learning: Machine learning is a type of artificial intelligence that enables systems to learn and improve from experience without being explicitly programmed. In AWS data architecture, machine learning is becoming increasingly important, with services such as Amazon SageMaker making it easier for organizations to build, train, and deploy machine learning models. By using machine learning, organizations can unlock new insights from their data, and make more accurate predictions about future trends and behaviors.
- Artificial Intelligence: Artificial intelligence (AI) is a broader category of technology that includes machine learning, as well as other techniques such as natural language processing and computer vision. In AWS data architecture, AI is becoming increasingly important, with services such as Amazon Lex and Amazon Rekognition enabling organizations to build intelligent applications that can understand and respond to human language and visual inputs. By using AI, organizations can create more engaging and personalized user experiences, and automate complex decision-making processes.
- Data Analytics: Data analytics is the process of examining data to draw insights and conclusions. In AWS data architecture, data analytics is becoming increasingly sophisticated, with services such as Amazon Kinesis enabling organizations to analyze real-time data streams in real-time. By using data analytics, organizations can gain a deeper understanding of their customers, products, and operations, and make more informed decisions about their business strategies.
By embracing these future trends in AWS data architecture, organizations can stay ahead of the curve, and gain a competitive advantage in their respective markets. With the right approach to machine learning, artificial intelligence, and data analytics, organizations can unlock new insights from their data, and create more intelligent, engaging, and personalized user experiences.
Conclusion: The Benefits of AWS Data Architecture
In today’s data-driven world, organizations need a robust and scalable data architecture to manage and analyze their growing volumes of data. AWS data architecture provides a powerful and flexible solution for modern data management, enabling organizations to collect, store, process, and analyze data in a secure and scalable way. By using AWS data architecture, organizations can unlock new insights from their data, and make more informed decisions about their business strategies.
Throughout this guide, we have explored the key components of AWS data architecture, including Amazon S3, Amazon DynamoDB, Amazon Redshift, Amazon Kinesis, and AWS Glue. We have also discussed the best practices for designing an effective AWS data architecture, and the challenges and considerations that organizations need to be aware of when implementing AWS data architecture. We have showcased real-world examples of successful AWS data architecture implementations, and explored the future trends and innovations in AWS data architecture, including machine learning, artificial intelligence, and data analytics.
In conclusion, AWS data architecture provides a powerful and flexible solution for modern data management, enabling organizations to collect, store, process, and analyze data in a secure and scalable way. By using AWS data architecture, organizations can unlock new insights from their data, and make more informed decisions about their business strategies. With its robust set of tools and services, AWS data architecture is an essential component of any modern data management strategy, and can help organizations gain a competitive advantage in their respective markets.
