
What is an Apache Spark Cluster and Why is it Important?
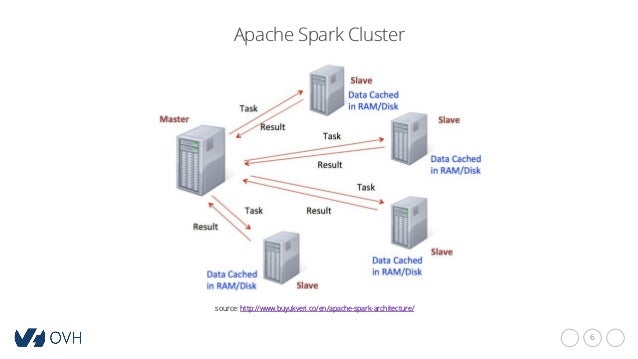
An Apache Spark Cluster is a distributed computing system designed for big data processing and analytics. It is built on top of the core Apache Spark engine, which provides an API for programming data-intensive applications. The cluster consists of a driver program that runs the main application logic and manages the execution of tasks on a collection of worker nodes or executors.
Using a cluster offers several benefits for data processing, including improved performance, scalability, and fault-tolerance. A cluster can process large datasets in parallel, reducing the time and resources required for data processing. It can also handle increasing data volumes and computational demands by adding more nodes to the cluster. Additionally, a cluster can automatically recover from node failures, ensuring the continuity and reliability of data processing.
The Apache Spark Cluster is particularly useful for applications that require real-time or near-real-time data processing, such as stream processing, machine learning, and graph processing. It can also integrate with various data storage systems, such as Hadoop Distributed File System (HDFS), Cassandra, and Amazon S3, providing flexibility and versatility for data processing and analytics.
In summary, an Apache Spark Cluster is a powerful and scalable computing system that can handle complex data processing tasks and enable real-time insights and analytics. Its importance lies in its ability to process large datasets efficiently, reliably, and flexibly, making it a popular choice for big data applications and use cases.

Key Components of an Apache Spark Cluster
An Apache Spark Cluster consists of several key components that work together to process data. These components include the driver, executors, and cluster manager. Understanding their functions and interactions is essential for optimizing the performance and efficiency of your cluster.
Driver
The driver is the main program that runs the Spark application and manages the execution of tasks on the cluster. It creates a SparkContext object that represents the connection to the cluster and provides an interface for submitting and monitoring jobs. The driver splits the application code into smaller units called tasks and distributes them across the executors for parallel processing.
Executors
Executors are the worker nodes that perform the actual data processing in a Spark Cluster. They run in-memory computations and provide a cache for data that can be reused across multiple tasks. Executors communicate with the driver to receive tasks and report progress and status. They also store the results of the tasks in a distributed file system or a database.
Cluster Manager
The cluster manager is the component that manages the resources and allocations of the cluster. It is responsible for creating and terminating executors, monitoring their health and status, and managing the scheduling and prioritization of tasks. The cluster manager can be a standalone component or integrated with other resource managers, such as Mesos or YARN.
How They Work Together
The driver, executors, and cluster manager work together to process data in a Spark Cluster. The driver submits tasks to the cluster manager, which allocates resources and schedules the tasks on the executors. The executors perform the computations and store the results in a distributed file system or a database. The driver monitors the progress and status of the tasks and provides feedback to the user.
In summary, the driver, executors, and cluster manager are the main components of an Apache Spark Cluster. Understanding their functions and interactions is crucial for optimizing the performance and efficiency of your cluster. By leveraging these components, you can process large datasets in parallel, handle increasing data volumes and computational demands, and enable real-time insights and analytics.
Choosing the Right Cluster Manager for Your Apache Spark Cluster
When setting up an Apache Spark Cluster, choosing the right cluster manager is a critical decision that can impact the performance, scalability, and fault-tolerance of your data processing. There are several cluster managers available for Apache Spark, each with its own features and benefits. In this section, we will compare the most popular cluster managers and provide guidelines for choosing the best one for your use case.
Standalone
The Standalone cluster manager is a simple, lightweight option that comes bundled with Apache Spark. It is easy to set up and manage, requiring only a few configuration files and a single command to start. Standalone is a good choice for small to medium-sized clusters, where resource allocation and scheduling are not a major concern.
Mesos
Apache Mesos is a general-purpose cluster manager that can manage resources across multiple frameworks, including Apache Spark. Mesos provides fine-grained resource sharing and isolation, allowing multiple applications to share the same resources efficiently. Mesos is a good choice for large-scale clusters, where resource allocation and scheduling are critical for performance and scalability.
YARN
Apache Hadoop YARN (Yet Another Resource Negotiator) is a cluster manager that is integrated with the Hadoop ecosystem. YARN provides a central resource manager that can manage resources across multiple applications, including Apache Spark. YARN is a good choice for organizations that already use Hadoop and want to leverage their existing infrastructure for Apache Spark.
Guidelines for Choosing the Right Cluster Manager
When choosing the right cluster manager for your Apache Spark Cluster, consider the following factors:
- Size and complexity of the cluster: For small to medium-sized clusters, Standalone is a good choice. For large-scale clusters, Mesos or YARN may be more appropriate.
- Resource allocation and scheduling: If resource allocation and scheduling are critical for performance and scalability, Mesos is a good choice. If you already use Hadoop, YARN may be a better option.
- Integration with other frameworks: If you plan to use other frameworks, such as Apache HBase or Apache Storm, Mesos may be a better choice due to its support for multiple frameworks.
- Ease of use and maintenance: Standalone is the easiest to set up and manage, while Mesos and YARN require more configuration and maintenance.
In summary, choosing the right cluster manager for your Apache Spark Cluster depends on several factors, including the size and complexity of the cluster, resource allocation and scheduling, integration with other frameworks, and ease of use and maintenance. By considering these factors, you can choose the best cluster manager for your needs and optimize the performance and efficiency of your data processing.
How to Set Up an Apache Spark Cluster: A Step-by-Step Guide
Setting up an Apache Spark Cluster can seem like a daunting task, especially for beginners. However, with the right guidance and tools, it can be a straightforward and rewarding experience. In this section, we will provide a detailed, beginner-friendly guide on how to set up an Apache Spark Cluster, using the Standalone cluster manager as an example.
Step 1: Download and Install Apache Spark
The first step is to download and install Apache Spark from the official website (https://spark.apache.org/downloads.html). Choose the version that matches your operating system and hardware requirements. Follow the installation instructions provided by Apache Spark, which typically involve extracting the downloaded file and setting the environment variables.
Step 2: Start the Standalone Cluster Manager
Once Apache Spark is installed, start the Standalone cluster manager by running the following command in the terminal:
./sbin/start-master.sh This command will start the Standalone master node, which will manage the resources and allocations of the cluster. You can access the web interface of the Standalone master node by opening a web browser and navigating to the following URL:
spark://:7077 Replace
Step 3: Start the Worker Nodes
To start the worker nodes, run the following command on each node, replacing
./sbin/start-slave.sh spark://:7077 This command will start the Standalone worker nodes, which will perform the actual data processing in the cluster.
Step 4: Test the Cluster
To test the cluster, run the following SparkPi example provided by Apache Spark:
./bin/spark-submit examples/src/main/python/pi.py --master spark://:7077 --executors 3 --total-executor-cores 6 --conf "spark.executor.memory=1g" This command will submit the SparkPi example to the Standalone cluster, using three executors with two cores each and one gigabyte of memory per executor. The SparkPi example will calculate the value of pi using the Monte Carlo method and print the result to the console.
Congratulations! You have successfully set up an Apache Spark Cluster using the Standalone cluster manager. You can now use the cluster for data processing, analytics, and machine learning tasks.
In summary, setting up an Apache Spark Cluster involves downloading and installing Apache Spark, starting the Standalone cluster manager, starting the worker nodes, and testing the cluster. By following these steps, you can create a powerful and scalable computing system for big data processing and analytics.
Optimizing Your Apache Spark Cluster for Peak Performance
Setting up an Apache Spark Cluster is just the beginning of your big data processing journey. To get the most out of your cluster, you need to optimize it for peak performance. In this section, we will share tips and best practices for optimizing your Apache Spark Cluster, such as tuning Spark configurations, caching data, and using partitioning. These techniques can improve the speed and efficiency of your data processing, and help you overcome common challenges and limitations.
Tip 1: Tune Spark Configurations
Spark configurations are the settings that control how Spark runs on your cluster. By default, Spark uses conservative settings that prioritize stability over performance. However, you can tune these settings to optimize Spark for your specific workload and hardware. Some common Spark configurations to tune include:
spark.executor.memory: The amount of memory to allocate to each executor.spark.executor.cores: The number of cores to allocate to each executor.spark.executor.instances: The number of executors to launch.spark.driver.memory: The amount of memory to allocate to the driver program.spark.sql.shuffle.partitions: The number of partitions to use for shuffle operations.
To tune these configurations, you can use the Spark configuration API, or set them as command-line options when submitting a Spark job. It’s important to monitor the performance and resource usage of your cluster, and adjust the configurations accordingly.
Tip 2: Cache Data
Caching data in memory can significantly improve the performance of Spark applications, especially for iterative algorithms or repeated queries. Spark provides a built-in cache mechanism that stores data in memory across multiple stages and tasks. To cache data, you can use the cache() or persist() methods of a DataFrame or RDD. You can also specify the storage level, such as MEMORY_ONLY, MEMORY_AND_DISK, or DISK_ONLY.
However, caching data also consumes memory, which can impact the performance of other tasks and stages. It’s important to monitor the memory usage of your cluster, and adjust the cache settings accordingly. You can use the Spark Web UI or the Spark History Server to monitor the cache usage and eviction rate.
Tip 3: Use Partitioning
Partitioning is the process of dividing data into smaller, more manageable chunks called partitions. Partitioning can improve the performance of Spark applications by reducing the amount of data that needs to be processed, shuffled, and transferred. Spark provides several partitioning strategies, such as hash partitioning, range partitioning, and custom partitioning.
To use partitioning, you can specify the number and strategy of partitions when creating a DataFrame or RDD. For example, you can use the repartition() or coalesce() methods to change the number of partitions, or the bucketBy() method to create custom partitions based on a column or expression.
However, partitioning also has some limitations and trade-offs. For example, creating too many partitions can increase the overhead of task scheduling and coordination, while creating too few partitions can lead to resource contention and load imbalance. It’s important to choose the right partitioning strategy and number of partitions for your specific workload and hardware.
In summary, optimizing your Apache Spark Cluster for peak performance involves tuning Spark configurations, caching data, and using partitioning. These techniques can improve the speed and efficiency of your data processing, and help you overcome common challenges and limitations. By following these tips and best practices, you can maximize the potential of your Apache Spark Cluster and achieve your big data processing goals.
Real-World Applications of Apache Spark Cluster
Apache Spark Cluster is a powerful and versatile tool for data processing and analytics, with a wide range of applications in various industries and domains. In this section, we will showcase some examples of how Apache Spark Cluster is used in real-world scenarios, and provide links to case studies, tutorials, and other resources for further reading.
Machine Learning
Apache Spark Cluster is widely used for machine learning applications, due to its support for distributed algorithms, in-memory computing, and scalable data processing. Spark MLlib, the machine learning library of Spark, provides a wide range of algorithms and tools for classification, regression, clustering, and recommendation. Some real-world use cases of Spark for machine learning include:
- Fraud detection: Spark can analyze large volumes of transactional data in real-time, and detect anomalies and patterns that indicate fraudulent activity.
- Predictive maintenance: Spark can analyze sensor data from industrial machines and equipment, and predict potential failures and downtime.
- Customer segmentation: Spark can analyze customer data from various sources, and segment customers based on their behavior, preferences, and needs.
For more information and examples of Spark for machine learning, you can check out the following resources:
- Spark MLlib documentation
- Machine learning with Apache Spark
- Machine learning with Apache Spark: A complete hands-on guide for beginners
Graph Processing
Apache Spark Cluster is also used for graph processing applications, due to its support for distributed graph computation and analysis. Spark GraphX, the graph processing library of Spark, provides a unified API for graph analytics, machine learning, and interactive visualization. Some real-world use cases of Spark for graph processing include:
- Social network analysis: Spark can analyze large-scale social networks, and identify communities, influencers, and patterns.
- Fraud detection: Spark can detect fraudulent behavior in financial networks, such as money laundering and terrorism financing.
- Recommendation engines: Spark can build recommendation engines for e-commerce, entertainment, and other applications.
For more information and examples of Spark for graph processing, you can check out the following resources:
- Spark GraphX documentation
- Graph processing with Apache Spark
- Graph processing with Apache Spark GraphX: A complete hands-on guide for beginners
Stream Processing
Apache Spark Cluster is used for stream processing applications, due to its support for real-time data ingestion, transformation, and aggregation. Spark Structured Streaming, the stream processing engine of Spark, provides a high-level API for building scalable and fault-tolerant stream processing pipelines. Some real-world use cases of Spark for stream processing include:
- Real-time analytics: Spark can analyze streaming data from various sources, such as sensors, logs, and social media, and provide real-time insights and alerts.
- Event-driven architectures: Spark can act as a message broker or a data pipeline, and process events and messages in real-time.
- Stateful applications: Spark can maintain state and context across multiple events and messages, and build stateful applications, such as recommendation engines, fraud detection, and personalization.
For more information and examples of Spark for stream processing, you can check out the following resources:
- Spark Structured Streaming documentation
- Stream processing with Apache Spark
- Real-time data processing with Apache Spark Structured Streaming: A complete hands-on guide for beginners
In summary, Apache Spark Cluster has a wide range of real-world applications in various industries and domains, such as machine learning, graph processing, and stream processing. By using Spark for these applications, organizations can gain insights, automate processes, and make data-driven decisions. For more information and examples of Spark for these applications, you can check out the resources provided in this section.
Challenges and Limitations of Apache Spark Cluster
While Apache Spark Cluster is a powerful and versatile tool for data processing and analytics, it also has some challenges and limitations that users should be aware of. In this section, we will discuss some of these challenges and limitations, and offer suggestions for overcoming them and maximizing the potential of your Apache Spark Cluster.
Hardware Requirements
Apache Spark Cluster requires significant hardware resources, such as CPU, memory, and storage, to run efficiently. The exact requirements depend on the size and complexity of your data and workload, but in general, you need a cluster with multiple nodes and sufficient resources to handle the load. If you don’t have the necessary hardware, you may experience performance issues, such as slow processing, out-of-memory errors, and node failures.
To overcome this challenge, you can:
- Upgrade your hardware: Invest in more powerful and scalable hardware, such as multi-core CPUs, high-memory nodes, and fast storage devices.
- Optimize your cluster: Use best practices for configuring and tuning your Apache Spark Cluster, such as setting the right number of executors, partitions, and memory allocations.
- Use cloud services: Consider using cloud-based services, such as Amazon EMR, Microsoft Azure HDInsight, or Google Cloud Dataproc, which provide pre-configured and managed Apache Spark Clusters with flexible pricing and scaling options.
Debugging and Maintenance
Debugging and maintaining an Apache Spark Cluster can be challenging, especially for large and complex clusters with multiple applications and users. You may encounter issues, such as job failures, data inconsistencies, and security breaches, that require careful investigation and resolution.
To overcome this challenge, you can:
- Use monitoring tools: Use monitoring tools, such as Spark UI, Ganglia, or Grafana, to track the performance and health of your cluster, and detect and diagnose issues in real-time.
- Follow best practices: Follow best practices for developing and deploying Apache Spark applications, such as testing, validation, error handling, and logging.
- Use automation tools: Use automation tools, such as Ansible, Chef, or Puppet, to automate the configuration, deployment, and scaling of your Apache Spark Cluster.
In summary, Apache Spark Cluster has some challenges and limitations, such as hardware requirements, debugging, and maintenance. However, by following best practices and using the right tools and services, you can overcome these obstacles and maximize the potential of your Apache Spark Cluster. For more information and resources on Apache Spark Cluster, you can check out the official documentation, community forums, and training materials.
The Future of Apache Spark Cluster: Trends and Developments
Apache Spark Cluster has been a game-changer in the field of data processing and analytics, enabling organizations to handle large-scale data with ease and efficiency. As the technology continues to evolve, we can expect new features, integrations, and use cases that will further enhance its capabilities and impact on data processing and analytics.
Real-Time Processing
One of the most exciting developments in Apache Spark Cluster is the ability to process data in real-time, using tools such as Spark Streaming and Structured Streaming. Real-time processing enables organizations to gain immediate insights from their data, respond to events and trends as they happen, and make data-driven decisions with confidence.
Machine Learning and AI
Another area of growth for Apache Spark Cluster is machine learning and artificial intelligence, with tools such as MLlib and GraphX providing powerful algorithms and frameworks for data scientists and engineers. With the rise of big data and the need for intelligent automation, machine learning and AI are becoming increasingly important for organizations seeking to gain a competitive edge.
Integration with Other Technologies
Apache Spark Cluster is also becoming more integrated with other technologies, such as Kafka, Cassandra, and Hadoop, enabling organizations to build end-to-end data pipelines and workflows. By combining the strengths of these technologies, organizations can create more robust, scalable, and flexible data architectures that can handle a wide range of data processing needs.
Speculations on the Future
While it’s hard to predict the future with certainty, some speculations on the future direction of Apache Spark Cluster include:
- Greater adoption of cloud-based services, as organizations seek to reduce costs, increase scalability, and improve agility.
- More sophisticated automation and orchestration tools, as organizations seek to streamline their data workflows and reduce manual intervention.
- Expanded use of graph processing and analytics, as organizations seek to uncover complex patterns and relationships in their data.
- Greater emphasis on data privacy and security, as organizations seek to protect their data and comply with regulations.
In summary, the future of Apache Spark Cluster looks bright, with new features, integrations, and use cases that will further enhance its capabilities and impact on data processing and analytics. By staying up-to-date with the latest trends and developments, organizations can leverage the full potential of Apache Spark Cluster and gain a competitive edge in their respective industries.
