
What is Amazon Neptune and How it Benefits Your Business
Amazon Neptune is a fully managed graph database service that offers efficient processing of complex data relationships. As a powerful and flexible solution, Neptune is designed to handle diverse data models and query patterns, making it an ideal choice for businesses in New Jersey seeking to manage and analyze large volumes of interconnected data. One of the primary benefits of Amazon Neptune is its ability to deliver improved performance, scalability, and security. By automating time-consuming administrative tasks, Neptune enables businesses to focus on application development and innovation. Additionally, its high availability and durability features ensure that data remains accessible and secure, even in the event of failures or disruptions.
Amazon Neptune’s Data Model: Understanding Property Graphs
Amazon Neptune employs a data model based on property graphs, a flexible and intuitive structure for managing complex relationships between data points. In a property graph, nodes represent entities, and edges represent the relationships between them. Each node and edge can have associated properties, which are key-value pairs that store additional information.
Property graphs are particularly well-suited for handling highly connected data, such as social networks, recommendation engines, and knowledge graphs. By using a property graph model, Neptune can efficiently process complex queries that involve traversing multiple relationships between nodes. This capability is essential for businesses in New Jersey that need to analyze large volumes of interconnected data.
For example, a retail business in New Jersey could use Amazon Neptune to build a recommendation engine that suggests products based on a customer’s browsing history and the purchase patterns of similar customers. By storing customer and product data as nodes and their relationships as edges, the retailer can quickly and efficiently query the graph to generate personalized recommendations.

How to Set Up Amazon Neptune in New Jersey
Setting up Amazon Neptune in New Jersey involves several key steps, including selecting the right instance type, configuring the database, and connecting to the service. By following these best practices, businesses can ensure a smooth and successful deployment.
Selecting the Right Instance Type
Amazon Neptune offers a range of instance types optimized for different workloads and use cases. When selecting an instance type for your Neptune deployment in New Jersey, consider factors such as the size and complexity of your dataset, the expected query volume, and your budget constraints.
Configuring the Database
Once you have selected an instance type, you will need to configure your Neptune database. This includes setting up the database schema, defining security policies, and configuring backup and recovery options. It is essential to follow AWS best practices for database configuration to ensure optimal performance and security.
Connecting to the Service
After configuring your database, you can connect to the Amazon Neptune service in New Jersey using a variety of tools and libraries. AWS provides SDKs and CLI tools for popular programming languages, making it easy to interact with your Neptune database from your application code. Additionally, you can use third-party tools such as Neptune Workbench or open-source libraries such as the Neptune Java client to manage and query your database.

Key Features of Amazon Neptune for Businesses in New Jersey
Amazon Neptune offers several key features that make it an attractive option for businesses in New Jersey. These features include low latency, high availability, and seamless integration with other AWS services.
Low Latency
Amazon Neptune is designed to deliver fast query performance, even for complex graph traversals. By using a combination of advanced caching techniques and efficient indexing strategies, Neptune can return query results in milliseconds, making it an ideal choice for real-time applications that require instant access to data.
High Availability
Amazon Neptune offers high availability through automatic failover and data replication. In the event of a failure, Neptune can automatically failover to a standby replica, ensuring that your application remains available and responsive. Additionally, Neptune replicates data across multiple availability zones, providing an additional layer of protection against data loss or downtime.
Seamless Integration with Other AWS Services
Amazon Neptune is part of the AWS ecosystem, which means that it integrates seamlessly with other AWS services such as Lambda, API Gateway, and SageMaker. By using Neptune in conjunction with these services, businesses in New Jersey can build end-to-end solutions that leverage the full power of the AWS platform.
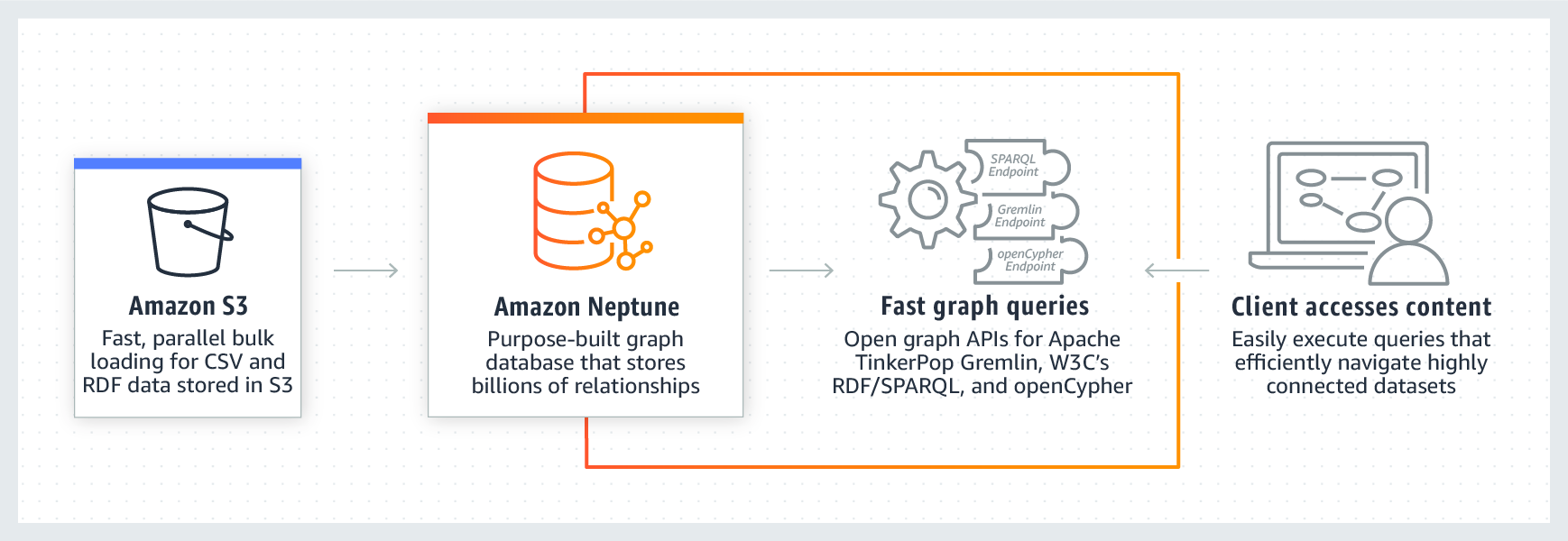
Real-World Applications of Amazon Neptune in New Jersey
Businesses in New Jersey are leveraging the power of Amazon Neptune to improve their operations and gain a competitive edge. Here are some examples of how companies in various industries are using Neptune to drive innovation and efficiency.
Social Media Analysis
A marketing agency in New Jersey uses Amazon Neptune to analyze social media data for its clients. By using Neptune’s property graph model, the agency can quickly and efficiently traverse complex social media networks and identify trends and insights that help its clients optimize their social media strategies.
Recommendation Engines
An e-commerce company in New Jersey uses Amazon Neptune to build recommendation engines that suggest products to its customers based on their browsing and purchasing history. By using Neptune’s low-latency query performance, the company can deliver real-time recommendations that increase customer engagement and sales.
Fraud Detection
A financial institution in New Jersey uses Amazon Neptune to detect and prevent fraud. By using Neptune’s graph database to model complex relationships between financial transactions, the institution can quickly identify suspicious patterns and take action to prevent fraudulent activity.
Best Practices for Using Amazon Neptune in New Jersey
To get the most out of Amazon Neptune in New Jersey, it’s essential to follow best practices for optimizing database performance, ensuring data security, and monitoring usage. Here are some tips to help you get started.
Optimizing Database Performance
To optimize database performance in Amazon Neptune, consider the following best practices:
- Use appropriate indexing strategies to improve query performance.
- Monitor query performance and identify bottlenecks using tools such as Amazon CloudWatch.
- Use connection pooling to manage database connections and reduce latency.
Ensuring Data Security
To ensure data security in Amazon Neptune, consider the following best practices:
- Use encryption at rest and in transit to protect data from unauthorized access.
- Implement appropriate access controls and authentication mechanisms to prevent unauthorized access.
- Regularly backup and restore data to ensure data availability and recoverability.
Monitoring Usage
To monitor usage in Amazon Neptune, consider the following best practices:
- Use Amazon CloudWatch to monitor database performance and identify trends and anomalies.
- Set up alarms and notifications to alert you of potential issues or problems.
- Regularly review usage metrics and adjust database configurations as needed to optimize performance and reduce costs.

Comparing Amazon Neptune to Other Database Services in New Jersey
When it comes to managing complex data relationships, Amazon Neptune offers several advantages over other database services available in New Jersey. Here’s a comparison of Neptune with Amazon RDS, Amazon DynamoDB, and self-managed graph databases.
Amazon Neptune vs. Amazon RDS
Amazon RDS is a relational database service that supports popular database engines such as MySQL, PostgreSQL, and Oracle. While RDS is an excellent choice for managing structured data, it may not be the best option for managing complex data relationships. Neptune, on the other hand, is specifically designed for managing graph data, offering faster query performance and more efficient data modeling.
Amazon Neptune vs. Amazon DynamoDB
Amazon DynamoDB is a NoSQL database service that offers fast and predictable performance with seamless scalability. While DynamoDB is an excellent choice for managing large volumes of unstructured data, it may not be the best option for managing complex data relationships. Neptune, with its support for property graphs, offers a more intuitive and efficient way to model and query complex data relationships.
Amazon Neptune vs. Self-Managed Graph Databases
Self-managed graph databases offer flexibility and control over database configurations and settings. However, they also require significant resources and expertise to manage and maintain. Neptune, as a fully managed graph database service, offers a more cost-effective and efficient way to manage complex data relationships, with automatic software patching, backups, and failover.
Getting Started with Amazon Neptune in New Jersey: A Step-by-Step Guide
Amazon Neptune is a fully managed graph database service that offers fast and efficient processing of complex data relationships. If you’re looking to get started with Neptune in New Jersey, here’s a step-by-step guide to help you along the way.
Step 1: Select an Instance Type
Amazon Neptune offers a range of instance types to suit different workload requirements. To select the right instance type for your needs, consider factors such as the size of your dataset, the complexity of your queries, and your budget constraints.
Step 2: Configure the Database
Once you’ve selected an instance type, you can proceed to configure your Neptune database. This includes setting up the database schema, defining security policies, and configuring backup and recovery options.
Step 3: Connect to the Service
After configuring your database, you can connect to the Amazon Neptune service in New Jersey using a variety of tools and libraries. AWS provides SDKs and CLI tools for popular programming languages, making it easy to interact with your Neptune database from your application code.
Step 4: Load Data into the Database
Once you’ve connected to the service, you can load data into your Neptune database. Neptune supports bulk data loading using the LOAD CSV command, making it easy to import large datasets in a single operation.
Step 5: Query the Database
After loading data into the database, you can start querying the database using the Neptune query language. Neptune supports both Gremlin and SPARQL query languages, making it easy to query graph data using a familiar syntax.
Step 6: Monitor Usage and Performance
To ensure optimal performance and availability, it’s essential to monitor usage and performance in your Neptune database. AWS provides tools such as Amazon CloudWatch and AWS Management Console to help you monitor database performance and identify trends and anomalies.