
What is Data Engineering and Why AWS?
Data engineering is a critical discipline that focuses on managing and utilizing large-scale data sets to drive business insights, improve decision-making, and optimize operations. Amazon Web Services (AWS) has emerged as a leading platform for data engineering solutions due to its scalability, reliability, and extensive suite of tools and services. The “data engineering AWS” combination offers numerous benefits, including:
- Scalability: AWS enables data engineers to handle massive data volumes with ease, ensuring that systems can grow and adapt to evolving business needs.
- Reliability: AWS provides robust, secure, and highly available infrastructure, minimizing the risk of data loss and downtime.
- Extensive tools and services: AWS offers a wide range of data engineering services, such as Amazon S3, Amazon Kinesis, Amazon Redshift, and AWS Glue, which can be combined to create powerful and flexible data engineering architectures.
Data engineering AWS solutions are designed to support various use cases, from real-time data processing and analytics to batch processing and machine learning. By leveraging AWS’s capabilities, data engineers can focus on creating value from data rather than managing infrastructure, resulting in faster time-to-market, lower costs, and increased innovation.

Core AWS Services for Data Engineering
Amazon Web Services (AWS) offers a wide range of services specifically designed for data engineering. Here, we introduce some of the primary AWS services for data engineering and explain their functionalities:
- Amazon S3 (Simple Storage Service): Amazon S3 is an object storage service that offers industry-leading scalability, data availability, security, and performance. Data engineers use Amazon S3 to store and retrieve any amount of data, from any device, at any time. S3 can serve as a data lake, storing raw, semi-structured, and structured data, and it integrates seamlessly with other AWS services.
- Amazon Kinesis: Amazon Kinesis is a platform for real-time streaming data processing. It enables data engineers to ingest, process, and analyze real-time streaming data, such as video, audio, application logs, website clickstreams, and IoT telemetry data, for machine learning, analytics, and other applications. Kinesis offers various services, including Kinesis Data Streams, Kinesis Data Firehose, and Kinesis Data Analytics.
- Amazon Redshift: Amazon Redshift is a fully managed, petabyte-scale data warehouse service that makes it simple and cost-effective to analyze all of your data using standard SQL and your existing Business Intelligence (BI) tools. Data engineers use Amazon Redshift to run complex analytical queries against petabyte-scale datasets, enabling businesses to gain deep insights into their data.
- AWS Glue: AWS Glue is a fully managed extract, transform, and load (ETL) service that makes it easy to prepare and load data for analytics. Data engineers use AWS Glue to create and run an ETL job with a few clicks in the AWS Management Console, and it automatically handles the scheduling, execution, and monitoring of the job.
These services contribute to a robust data engineering architecture by providing scalable, reliable, and secure storage, processing, and analytics capabilities. By combining these services, data engineers can create powerful data engineering solutions tailored to their organization’s unique needs.
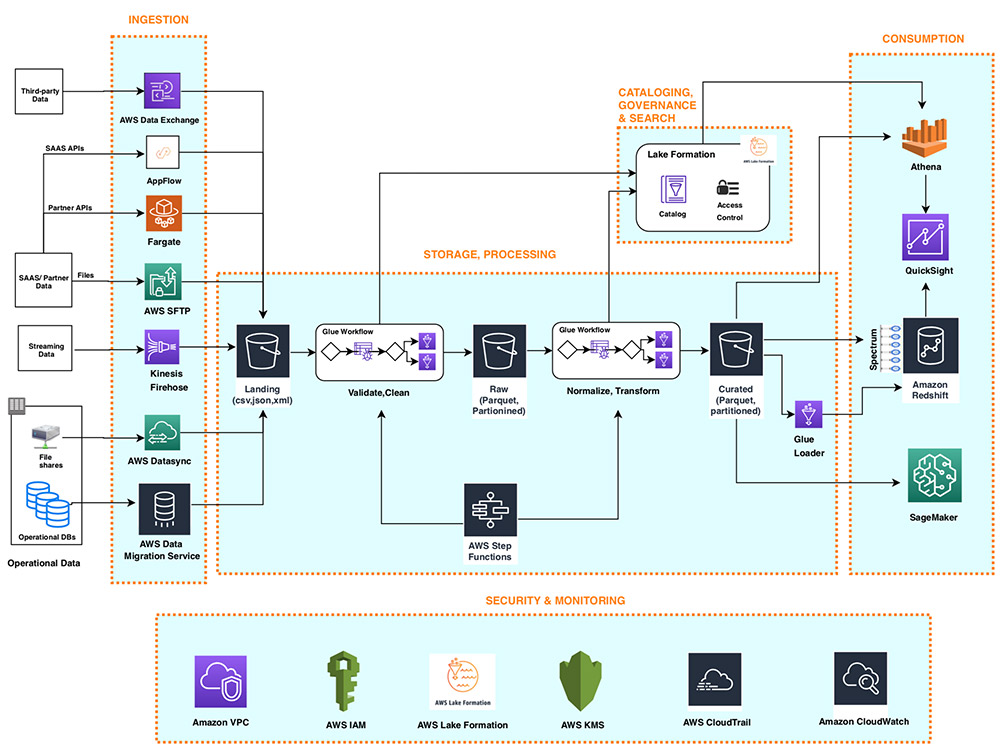
Designing Data Engineering Solutions with AWS: Best Practices
When designing data engineering solutions using Amazon Web Services (AWS), following best practices can help ensure optimal performance, scalability, and cost-effectiveness. Here are some best practices to consider:
- Data lake vs data warehouse architectures: Data lakes and data warehouses serve different purposes. Data lakes store raw, semi-structured, and structured data, while data warehouses store structured, cleaned, and transformed data for analytics. Choose the appropriate architecture based on your use case. AWS provides services like Amazon S3 for data lakes and Amazon Redshift for data warehouses.
- Data pipeline design: Design data pipelines that can handle various data sources, formats, and volumes. AWS offers services like AWS Glue and Amazon Kinesis to create, schedule, and monitor data pipelines. Ensure that your data pipelines are fault-tolerant, scalable, and can handle real-time and batch processing.
- Cost optimization strategies: To optimize costs, consider using AWS’s cost-saving features like reserved instances, spot instances, and data lifecycle management policies. Monitor and analyze usage patterns to identify cost-saving opportunities and optimize resource utilization.
By following these best practices, data engineers can design robust, scalable, and cost-effective data engineering solutions using AWS. These practices help ensure that data engineering solutions can handle large-scale data sets, provide real-time insights, and adapt to evolving business needs.

How to Migrate Data Engineering Workloads to AWS
Migrating data engineering workloads to Amazon Web Services (AWS) can help organizations take advantage of AWS’s scalability, reliability, and extensive suite of tools and services. Here is a step-by-step guide on how to migrate data engineering workloads to AWS:
- Assess current data engineering workloads: Evaluate the current data engineering workloads, including data sources, volumes, formats, and processing requirements. Identify the tools and services currently in use and assess their compatibility with AWS services.
- Choose data migration strategies: Based on the assessment, choose the appropriate data migration strategies. AWS offers various data migration tools, such as AWS DataSync, AWS Database Migration Service (DMS), and AWS Glue.
- Set up infrastructure: Set up the infrastructure on AWS, including data storage, processing, and analytics services. This may include Amazon S3, Amazon Kinesis, Amazon Redshift, and AWS Glue.
- Test the migration: Test the migration by running small-scale migration tests and validating the results. Ensure that the migrated data is accurate, complete, and accessible.
- Monitor and optimize: Monitor the performance and cost of the migrated data engineering workloads. Optimize resource utilization and cost by using AWS’s cost-saving features like reserved instances, spot instances, and data lifecycle management policies.
By following these steps, organizations can successfully migrate their data engineering workloads to AWS and take advantage of AWS’s scalability, reliability, and extensive suite of tools and services. Migrating to AWS can help organizations reduce costs, improve performance, and enable new data-driven use cases.
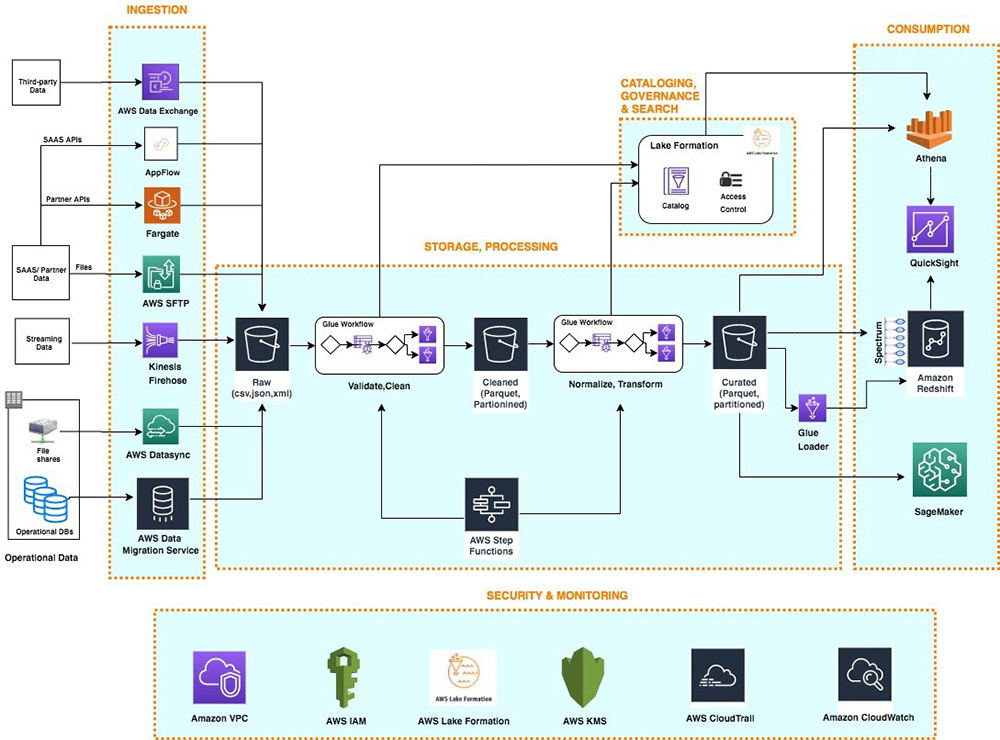
Real-World Data Engineering Use Cases on AWS: Success Stories
Amazon Web Services (AWS) has become a leading platform for data engineering solutions due to its scalability, reliability, and extensive suite of tools and services. Here are some real-world data engineering use cases on AWS, highlighting the challenges, solutions, and benefits of each case study:
Use Case 1: Real-Time Data Processing for IoT Devices
A manufacturing company wanted to process and analyze data from IoT devices in real-time to improve operational efficiency. By using AWS IoT, Amazon Kinesis, and AWS Lambda, the company was able to ingest, process, and analyze data from IoT devices in real-time, resulting in improved operational efficiency and reduced downtime.
Use Case 2: Data Lake Implementation for Large-Scale Data Analytics
A media company wanted to implement a data lake for large-scale data analytics. By using Amazon S3, AWS Glue, and Amazon Athena, the company was able to create a scalable and cost-effective data lake that could handle large volumes of data and enable real-time analytics, resulting in improved customer engagement and revenue growth.
Use Case 3: Data Warehouse Modernization for Improved Performance and Scalability
A retail company wanted to modernize its data warehouse for improved performance and scalability. By using Amazon Redshift, the company was able to migrate its data warehouse to the cloud and improve query performance by up to 10x, resulting in improved customer insights and revenue growth.
These use cases demonstrate the power and flexibility of AWS for data engineering solutions. By using AWS’s suite of tools and services, organizations can overcome the challenges of managing and utilizing large-scale data sets, resulting in improved operational efficiency, customer engagement, and revenue growth.
Security and Compliance in AWS Data Engineering
Security and compliance are critical considerations in data engineering, and Amazon Web Services (AWS) provides several measures to ensure data is secure and compliant. Here are some of the security and compliance measures available in AWS for data engineering:
- Data encryption: AWS provides several data encryption options, including server-side encryption (SSE) for Amazon S3, client-side encryption, and encryption in transit using Transport Layer Security (TLS). Data encryption ensures that data is protected from unauthorized access and complies with data privacy regulations.
- Access control: AWS provides several access control mechanisms, including Identity and Access Management (IAM) policies, access control lists (ACLs), and bucket policies for Amazon S3. Access control ensures that only authorized users and services can access the data.
- Audit logging: AWS provides audit logging capabilities, including AWS CloudTrail and Amazon S3 server access logging. Audit logging enables organizations to track user activity and ensure compliance with regulatory requirements.
In addition to these measures, AWS also provides several compliance reports and certifications, including SOC 1, SOC 2, ISO 27001, and HIPAA. These reports and certifications help organizations demonstrate compliance with various regulatory requirements and industry standards.
By implementing these security and compliance measures, organizations can ensure that their data engineering solutions are secure, compliant, and meet regulatory requirements. AWS provides a robust set of tools and services to help organizations implement these measures and maintain a secure and compliant data engineering environment.

Monitoring and Troubleshooting AWS Data Engineering Systems
Monitoring and troubleshooting are essential aspects of maintaining a reliable and performant data engineering system on Amazon Web Services (AWS). Here are some strategies for monitoring and troubleshooting AWS data engineering systems:
- Performance monitoring: AWS provides several performance monitoring tools, including Amazon CloudWatch, which can be used to monitor the performance of AWS services such as Amazon S3, Amazon Kinesis, and Amazon Redshift. Performance monitoring enables organizations to identify and resolve performance issues before they impact users.
- Log analysis: AWS services generate logs that can be used to troubleshoot issues and identify trends. For example, Amazon S3 access logs can be used to identify unauthorized access attempts, while Amazon Kinesis logs can be used to troubleshoot data processing issues. Log analysis enables organizations to identify and resolve issues quickly and efficiently.
- Alerting: AWS provides alerting mechanisms, including Amazon CloudWatch Alarms, which can be used to notify organizations of performance issues or other issues that require attention. Alerting enables organizations to respond to issues quickly and efficiently, minimizing the impact on users.
In addition to these strategies, AWS provides several tools and services to help organizations monitor and troubleshoot their data engineering systems. For example, AWS X-Ray can be used to analyze and debug distributed applications, while AWS Personal Health Dashboard provides personalized information about the health of AWS services.
By implementing these monitoring and troubleshooting strategies, organizations can ensure that their data engineering systems are reliable, performant, and meet user needs. AWS provides a robust set of tools and services to help organizations monitor and troubleshoot their data engineering systems, enabling organizations to focus on delivering value to their users.
Continuous Learning and Improvement in AWS Data Engineering
Continuous learning and improvement are essential for staying up-to-date with the latest features, best practices, and industry trends in AWS data engineering. Here are some strategies for continuous learning and improvement in AWS data engineering:
- AWS documentation: AWS provides extensive documentation for its services, including data engineering services. Regularly reviewing AWS documentation can help organizations stay up-to-date with the latest features and best practices for AWS data engineering.
- AWS blogs and forums: AWS operates several blogs and forums, including the AWS Big Data Blog and the AWS Data Blog, which provide insights and best practices for AWS data engineering. Regularly reviewing these resources can help organizations stay up-to-date with the latest trends and best practices in AWS data engineering.
- AWS training and certification: AWS offers several training and certification programs, including the AWS Certified Big Data – Specialty certification, which can help organizations develop the skills and knowledge needed to design and implement AWS data engineering solutions. Regularly participating in AWS training and certification programs can help organizations stay up-to-date with the latest features and best practices for AWS data engineering.
In addition to these strategies, organizations should also consider participating in AWS user groups and conferences, which provide opportunities to network with other AWS users and learn from their experiences. AWS also provides several tools and services for monitoring and optimizing AWS data engineering systems, including Amazon CloudWatch, AWS X-Ray, and AWS Personal Health Dashboard, which can help organizations identify and address performance issues and other issues that may impact their data engineering systems.
By implementing these strategies for continuous learning and improvement, organizations can ensure that their AWS data engineering solutions are optimized for performance, reliability, and security. AWS provides a robust set of tools and services for data engineering, and by staying up-to-date with the latest features and best practices, organizations can take full advantage of these capabilities to deliver value to their users.
