
Unraveling the Basics: Understanding the “Import from SQL” Functionality
Data analysis and management are crucial aspects of modern businesses and research, and SQL databases are a popular choice for storing and organizing vast amounts of data. However, to derive valuable insights and make informed decisions, it is essential to extract and import this data into a suitable environment for processing and analysis. This is where the “import from SQL” functionality comes into play, offering a seamless bridge between SQL databases and data analysis tools such as Python.
The “import from SQL” process involves extracting data from SQL databases and importing it into a preferred data analysis environment, such as Python. This approach enables data professionals to leverage the power of SQL for data manipulation and retrieval while harnessing the capabilities of Python for data visualization, machine learning, and advanced analytics.
By mastering the art of importing data from SQL, data analysts, scientists, and engineers can significantly streamline their workflows, reduce manual effort, and minimize the risk of errors. Moreover, the ability to import SQL data into Python allows for greater flexibility in data manipulation, enabling users to clean, transform, and prepare data for various downstream applications, such as predictive modeling, statistical analysis, and business intelligence.
In summary, the “import from SQL” functionality is an indispensable skill for data professionals, offering a powerful and efficient means of integrating SQL databases with Python-based data analysis workflows. By harnessing this capability, data professionals can unlock the full potential of their data, derive valuable insights, and make informed decisions to drive business success and innovation.

Identifying Suitable Tools: Selecting the Right Python Libraries
When it comes to importing data from SQL databases into Python, choosing the right libraries is paramount for a seamless and efficient experience. Among the myriad of available options, three libraries stand out for their versatility, ease of use, and robust functionality: sqlite3, sqlalchemy, and pandas.
The sqlite3 library is a built-in Python module that provides a user-friendly interface for interacting with SQLite databases. SQLite is a self-contained, file-based database system, making it an excellent choice for local data storage and manipulation. Leveraging the sqlite3 library, data professionals can execute SQL queries, fetch results, and manipulate data directly within Python, without requiring external dependencies or setup procedures.
For more advanced SQL database management, the sqlalchemy library is an excellent choice. Sqlalchemy is a SQL toolkit and Object-Relational Mapping (ORM) system that enables Python developers to interact with various SQL databases, including MySQL, PostgreSQL, and Oracle, among others. By abstracting the complexities of SQL syntax and database-specific dialects, sqlalchemy simplifies the data import process, allowing users to focus on data analysis and manipulation rather than low-level database management tasks.
Last but not least, the pandas library is an indispensable tool for data manipulation and analysis within Python. Specifically designed for working with tabular data, pandas provides a range of data structures, such as Series and DataFrames, that facilitate efficient data storage, cleaning, and transformation. Moreover, pandas integrates seamlessly with both sqlite3 and sqlalchemy, enabling users to import SQL data directly into DataFrames for further processing and analysis.
In conclusion, selecting the right Python libraries is crucial for a successful and efficient “import from SQL” experience. By leveraging the capabilities of sqlite3, sqlalchemy, and pandas, data professionals can streamline their workflows, reduce manual effort, and focus on deriving valuable insights from their data.

Establishing Connections: Building a Bridge to Your SQL Database
Before diving into the world of SQL data import, it is essential to establish a reliable connection between your Python environment and your SQL database. This connection serves as a bridge, enabling seamless data transfer between the two systems. In this section, we will explore the process of creating a connection using the popular Python libraries sqlite3, sqlalchemy, and pandas.
Connecting with sqlite3
As a built-in Python module, sqlite3 simplifies the connection process. To create a connection with a SQLite database, you can use the following code snippet:
import sqlite3 conn = sqlite3.connect('my_database.db') In this example, ‘my_database.db’ represents the SQLite database file you wish to connect to. If the file does not exist, sqlite3 will create it automatically upon connection.
Connecting with sqlalchemy
When working with more advanced SQL databases, sqlalchemy offers a unified and flexible approach to connection management. To establish a connection using sqlalchemy, you can use the following code:
from sqlalchemy import create_engine engine = create_engine('mysql+pymysql://username:password@localhost/mydatabase') In this example, replace ‘username’, ‘password’, and ‘mydatabase’ with the appropriate credentials for your specific SQL database. The ‘mysql+pymysql’ component indicates the database dialect and driver to use for the connection.
Connecting with pandas
Pandas integrates seamlessly with both sqlite3 and sqlalchemy, allowing you to create connections using either library. For sqlite3, you can use the following code:
import sqlite3 import pandas as pd conn = sqlite3.connect('my_database.db') df = pd.read_sql_query('SELECT * FROM my_table', conn) For sqlalchemy, the code is as follows:
from sqlalchemy import create_engine import pandas as pd engine = create_engine('mysql+pymysql://username:password@localhost/mydatabase') df = pd.read_sql_query('SELECT * FROM my_table', engine) In both examples, ‘my_table’ represents the table you wish to import data from. By leveraging pandas, you can directly import SQL data into a DataFrame, enabling further data manipulation and analysis.
In conclusion, establishing a connection between your Python environment and SQL database is a crucial step in the “import from SQL” process. By utilizing the powerful libraries sqlite3, sqlalchemy, and pandas, data professionals can create robust, reliable, and efficient connections, ensuring smooth data transfer and seamless integration between SQL databases and Python-based data analysis workflows.
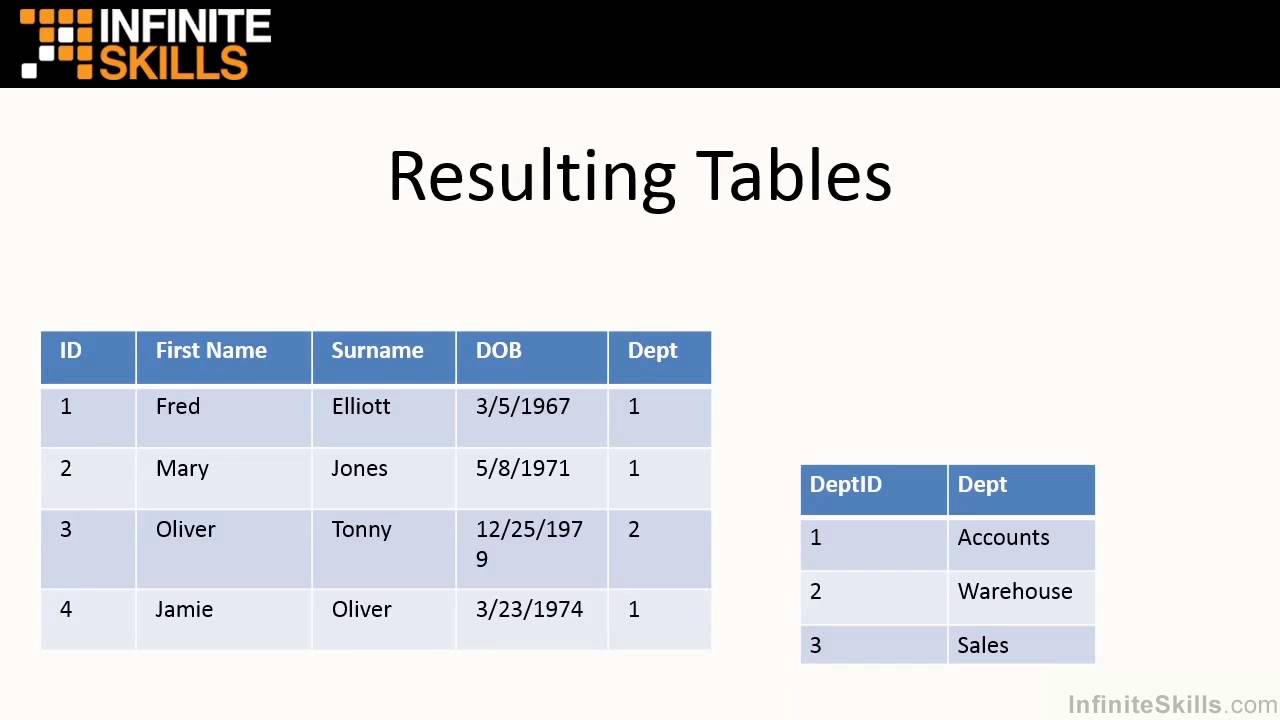
Navigating SQL Queries: Extracting Relevant Data
Once a connection has been established between your Python environment and SQL database, the next step is to navigate the vast expanse of data using SQL queries. Crafting effective SQL queries is an art, enabling you to filter, sort, and extract the desired data in a structured and organized manner. In this section, we will discuss the process of crafting SQL queries to prepare data for import into your Python environment.
The Anatomy of a SQL Query
A SQL query typically consists of the following components:
- SELECT clause: Specifies the columns or expressions to include in the query result.
- FROM clause: Identifies the table(s) from which to retrieve data.
- WHERE clause: Filters data based on specified conditions.
- GROUP BY clause: Groups rows based on common values in specified columns.
- ORDER BY clause: Sorts the query result based on specified columns and sort orders.
Filtering Data with the WHERE Clause
The WHERE clause is a powerful tool for filtering data based on specific conditions. For example, to retrieve all records from the ’employees’ table where the ‘salary’ column is greater than 50,000, you can use the following SQL query:
SELECT * FROM employees WHERE salary > 50000; Sorting Data with the ORDER BY Clause
The ORDER BY clause enables you to sort the query result based on one or more columns. For instance, to retrieve all records from the ‘sales’ table and sort them by the ‘date’ column in descending order, you can use the following SQL query:
SELECT * FROM sales ORDER BY date DESC; Joining Tables with the JOIN Clause
When working with multiple tables, the JOIN clause allows you to combine rows from two or more tables based on a related column. For example, to retrieve all records from the ‘orders’ table and the ‘customers’ table where the ‘customer\_id’ column is common to both tables, you can use the following SQL query:
SELECT * FROM orders INNER JOIN customers ON orders.customer_id = customers.customer_id; Preparing Data for Import
By mastering the art of crafting SQL queries, you can effectively filter, sort, and extract the desired data, preparing it for import into your Python environment. This process is crucial for ensuring that only relevant and organized data is imported, reducing manual effort and enhancing the overall efficiency of the “import from SQL” workflow.
In conclusion, navigating SQL queries is an essential skill for data professionals seeking to import data from SQL databases into Python. By understanding the anatomy of a SQL query and mastering techniques such as filtering, sorting, and joining tables, data professionals can efficiently extract and prepare data for import, ensuring a seamless and successful “import from SQL” experience.
Importing Data: Bridging the Gap Between SQL and Python
With a solid understanding of SQL queries and a connection established between your Python environment and SQL database, you are now ready to import SQL data into Python data structures. In this section, we will illustrate the process of importing SQL data using popular Python libraries, ensuring a smooth and successful data transfer.
Importing Data with sqlite3
To import data from a SQLite database into a Python data structure using the sqlite3 library, you can use the following code snippet:
import sqlite3 import pandas as pd
Connect to the SQLite database
conn = sqlite3.connect('my_database.db')
Define the SQL query
query = 'SELECT * FROM my_table'
Execute the SQL query and store the result in a pandas DataFrame
df = pd.read_sql_query(query, conn)
Close the connection
conn.close()
In this example, the sqlite3 library is used to establish a connection with the SQLite database, and the pandas library is utilized to import the query result into a DataFrame. Once the data has been imported, the connection is closed to release any resources.
Importing Data with sqlalchemy
When working with more advanced SQL databases, the sqlalchemy library can be used to import data into Python data structures. The following code snippet demonstrates the process:
from sqlalchemy import create_engine import pandas as pd
Create an engine for connecting to the database
engine = create_engine('mysql+pymysql://username:password@localhost/mydatabase')
Define the SQL query
query = 'SELECT * FROM my_table'
Execute the SQL query and store the result in a pandas DataFrame
df = pd.read_sql_query(query, engine)
In this example, the sqlalchemy library is used to create an engine for connecting to the database, and the pandas library is utilized to import the query result into a DataFrame. Note that the engine object can be reused for multiple queries, making it an efficient choice for large-scale data import operations.
Importing Data with pandas.read\_sql()
For added convenience, the pandas library provides the read\_sql() function, which can be used to import SQL data directly into a DataFrame. The following code snippet demonstrates the process:
import pandas as pd from sqlalchemy import create_engine
Create an engine for connecting to the database
engine = create_engine('mysql+pymysql://username:password@localhost/mydatabase')
Define the SQL query
query = 'SELECT * FROM my_table'
Execute the SQL query and store the result in a pandas DataFrame
df = pd.read_sql(query, engine)
In this example, the pandas.read\_sql() function is used to execute the SQL query and import the data directly into a DataFrame. This approach simplifies the data import process, further streamlining your “import from SQL” workflow.
In conclusion, importing SQL data into Python data structures is a crucial step in the “import from SQL” process. By leveraging popular Python libraries such as sqlite3, sqlalchemy, and pandas, data professionals can efficiently bridge the gap between SQL databases and Python-based data analysis workflows, ensuring a seamless and successful data transfer.

Refining Data: Cleaning and Preparing SQL Data in Python
With SQL data successfully imported into Python data structures, the next step in the “import from SQL” process is to refine the data by cleaning, transforming, and preparing it for analysis. In this section, we will explore techniques for ensuring data quality and consistency within the Python environment.
Handling Missing Values
Missing data is a common issue when importing data from SQL databases. Python provides several methods for handling missing values, such as the dropna() and fillna() functions in the pandas library. For example, to remove rows containing missing values, you can use the following code:
import pandas as pd
Import data from SQL
df = pd.read_sql_query('SELECT * FROM my_table', engine)
Remove rows with missing values
df_clean = df.dropna()
Alternatively, to replace missing values with a specified value, such as 0, you can use the fillna() function:
# Replace missing values with 0 df_clean = df.fillna(0) Transforming Data Types
Data types may not always be imported as expected, requiring transformation to ensure data quality and consistency. The pandas library provides several functions for transforming data types, such as astype() and to\_datetime(). For example, to convert a column named ‘date’ to a datetime data type, you can use the following code:
df['date'] = pd.to_datetime(df['date']) Aggregating and Summarizing Data
Aggregating and summarizing data is often necessary to gain insights from SQL data. Python provides several functions for grouping, counting, and summarizing data, such as the groupby() and size() functions in the pandas library. For example, to count the number of records in each group of a grouped DataFrame, you can use the following code:
# Group data by a column and count records grouped_df = df.groupby('category').size() Standardizing Data
Standardizing data is essential for comparing and analyzing data from different sources. Python provides several methods for standardizing data, such as the StandardScaler() class in the sklearn library. For example, to standardize a column named ‘values’ in a DataFrame, you can use the following code:
from sklearn.preprocessing import StandardScaler
Initialize a StandardScaler object
scaler = StandardScaler()
Fit the scaler to the data and transform the column
df['values'] = scaler.fit_transform(df[['values']])
In conclusion, refining data is a crucial step in the “import from SQL” process, ensuring data quality and consistency within the Python environment. By leveraging powerful Python libraries and functions, data professionals can clean, transform, and prepare SQL data for analysis, paving the way for informed decision-making and data-driven insights.
Optimizing Performance: Strategies for Efficient Data Import
Importing data from SQL databases into Python can be a time-consuming process, particularly when dealing with large datasets. In this section, we will share best practices and optimization techniques to enhance the performance of the “import from SQL” process, reducing time and resource consumption.
Chunking Data
Chunking data is an effective strategy for importing large datasets in smaller, more manageable pieces. By breaking down the data into smaller chunks, you can reduce memory usage and accelerate the import process. The pandas library provides the read\_sql\_query() function, which supports chunksize parameter for chunking data. For example, to import data in chunks of 10,000 rows, you can use the following code:
import pandas as pd from sqlalchemy import create_engine
Create an engine for connecting to the database
engine = create_engine('mysql+pymysql://username:password@localhost/mydatabase')
Define the SQL query
query = 'SELECT * FROM my_table'
Import data in chunks of 10,000 rows
for chunk in pd.read_sql_query(query, engine, chunksize=10000):
# Process each chunk of data
process_data(chunk)
Parallel Processing
Parallel processing is another technique for improving the performance of the “import from SQL” process. By dividing the data into smaller pieces and processing them simultaneously, you can significantly reduce the overall import time. The multiprocessing library in Python provides tools for parallel processing, such as the Pool class and its map() method. For example, to process data in parallel using 4 processes, you can use the following code:
import pandas as pd from sqlalchemy import create_engine from multiprocessing import Pool
Create an engine for connecting to the database
engine = create_engine('mysql+pymysql://username:password@localhost/mydatabase')
Define the SQL query
query = 'SELECT * FROM my_table'
Initialize a Pool object with 4 processes
with Pool(4) as p:
# Import data in chunks and process them in parallel
p.map(process_data, pd.read_sql_query(query, engine, chunksize=10000))
Caching Query Results
Caching query results can also improve the performance of the “import from SQL” process. By storing the results of frequently used queries, you can reduce the number of database queries and accelerate the data import process. The popular caching libraries in Python include RocketCache, PyLibMCCache, and DiskCache. For example, to cache query results using RocketCache, you can use the following code:
from rocketcache import Cache
Initialize a Cache object with a size of 1 GB
cache = Cache(1024**3)
Define the SQL query
query = 'SELECT * FROM my_table'
Check if the query results are cached
if query in cache:
# Retrieve the cached query results
df = cache[query]
else:
# Import data from SQL and cache the query results
df = pd.read_sql_query(query, engine)
cache[query] = df
In conclusion, optimizing the performance of the “import from SQL” process is essential for handling large datasets and reducing time and resource consumption. By employing strategies such as chunking data, parallel processing, and caching query results, data professionals can significantly enhance the efficiency of the data import process, ensuring a seamless and productive experience.
Troubleshooting Common Issues: Overcoming Challenges in SQL Data Import
Importing data from SQL databases into Python can sometimes present challenges, ranging from connection issues to data formatting problems. In this section, we will address common pitfalls and offer practical solutions and troubleshooting tips to ensure a seamless experience when importing SQL data into Python.
Connection Issues
Connection issues are among the most common challenges when importing data from SQL databases. These problems can arise due to incorrect database credentials, firewall restrictions, or network connectivity issues. To troubleshoot connection issues, consider the following steps:
- Verify your database credentials, including the username, password, host, and port.
- Check if your database server is accessible from your current network.
- Ensure that your firewall settings allow incoming and outgoing connections to the database server.
- Consult your database administrator or IT support team for assistance in resolving connection issues.
Data Formatting Problems
Data formatting problems can also hinder the “import from SQL” process. These issues can arise due to inconsistent data types, missing values, or incorrect data encoding. To address data formatting problems, consider the following steps:
- Use SQL queries to filter and clean the data before importing it into Python.
- Employ data transformation techniques, such as the pandas library’s fillna() and astype() functions, to handle missing values and inconsistent data types.
- Verify the data encoding of your SQL database and ensure that it matches the encoding used in your Python environment.
- Consult the documentation of your chosen Python libraries and SQL database for guidance on handling data formatting issues.
Performance Bottlenecks
Performance bottlenecks can significantly impact the “import from SQL” process, particularly when dealing with large datasets. To overcome performance bottlenecks, consider the optimization techniques discussed in the previous section, such as chunking data, parallel processing, and caching query results.
Insufficient Memory
Insufficient memory can also pose challenges when importing SQL data into Python. To address memory issues, consider the following steps:
- Limit the amount of data imported at once by using SQL queries to filter and subset the data.
- Employ data compression techniques, such as zlib or bz2, to reduce the size of the data before importing it into Python.
- Upgrade your system’s memory or use cloud-based solutions to increase available memory resources.
In conclusion, troubleshooting common issues is an essential aspect of the “import from SQL” process. By understanding the challenges that can arise and employing practical solutions and troubleshooting tips, data professionals can ensure a seamless and productive experience when importing SQL data into Python.
