
Data Engineer Role and Responsibilities: An Overview
A data engineer plays a critical role in modern organizations, responsible for designing, building, and maintaining the data infrastructure required for data analysis and machine learning purposes. By enabling data-driven decision-making, data engineers help organizations improve operational efficiency, reduce costs, and drive innovation. So, what does a data engineer do? Data engineers are responsible for creating and managing data pipelines, which involve extracting, transforming, and loading (ETL) data from various sources into a centralized data warehouse or data lake. They must ensure that data is accurate, complete, and consistent, and that it is available in a format that is easily accessible for data scientists, analysts, and other stakeholders.
In addition to building data pipelines, data engineers are responsible for optimizing data warehousing solutions for big data, implementing machine learning algorithms for predictive analytics, and ensuring data security and privacy. They must also be able to work closely with data scientists, analysts, and other stakeholders to understand their data needs and deliver solutions that meet those needs.
To be successful in this role, data engineers must have a strong background in programming languages such as Python and SQL, as well as experience with big data processing frameworks such as Hadoop and Spark. They must also have a deep understanding of data warehousing solutions such as Amazon Redshift and Google BigQuery, and be able to design and implement data models that are scalable, efficient, and easy to maintain.
In summary, data engineers play a critical role in enabling data-driven decision-making for organizations. By designing, building, and maintaining data infrastructure, they help organizations improve operational efficiency, reduce costs, and drive innovation. If you’re interested in a career in data engineering, now is a great time to get started, as demand for data engineering talent is expected to continue to grow in the coming years.

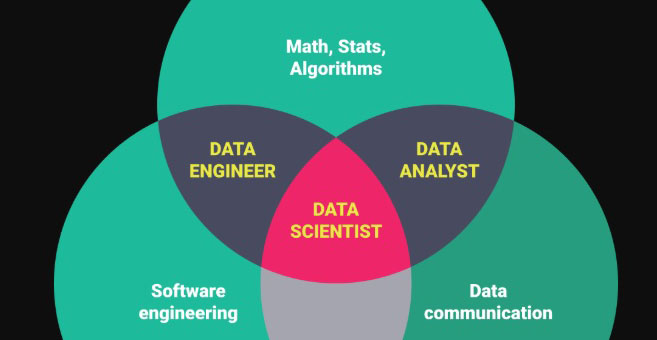
Data Engineer vs Data Scientist: Key Differences
While data engineers and data scientists both play crucial roles in data-driven organizations, their skill sets and responsibilities are distinct. So, what’s the difference between a data engineer and a data scientist? Data engineers are responsible for designing, building, and maintaining the data infrastructure required for data analysis and machine learning purposes. They focus on data integration, processing, and storage, ensuring that data is accurate, complete, and consistent. Data engineers are also responsible for implementing data security and privacy measures, as well as optimizing data warehousing solutions for big data.
Data scientists, on the other hand, are responsible for analyzing and modeling data to extract insights and inform business decisions. They focus on statistical analysis, machine learning, and data visualization, using programming languages such as Python and R to build predictive models and analyze data. Data scientists are also responsible for communicating their findings to stakeholders, using data visualization tools and other techniques to make complex data accessible and understandable.
While data engineers and data scientists have distinct roles, they often work closely together to deliver data-driven solutions. Data engineers provide the data infrastructure and processing power required for data analysis, while data scientists provide the insights and models required to inform business decisions. Effective collaboration between data engineers and data scientists is essential for delivering high-quality data-driven solutions that meet business needs.
To become a data engineer, it’s important to have a strong background in programming languages such as Python and SQL, as well as experience with big data processing frameworks such as Hadoop and Spark. Data engineers should also have a deep understanding of data warehousing solutions such as Amazon Redshift and Google BigQuery, and be able to design and implement data models that are scalable, efficient, and easy to maintain.
In summary, while data engineers and data scientists have distinct roles and skill sets, they often work closely together to deliver data-driven solutions. Data engineers are responsible for designing, building, and maintaining the data infrastructure required for data analysis and machine learning purposes, while data scientists are responsible for analyzing and modeling data to extract insights and inform business decisions. Effective collaboration between data engineers and data scientists is essential for delivering high-quality data-driven solutions that meet business needs.

How to Become a Data Engineer: Skills and Qualifications
Data engineering is a rapidly growing field, with increasing demand for skilled professionals who can design, build, and maintain data infrastructure for data analysis and machine learning purposes. So, how can you become a data engineer? To become a data engineer, you typically need a strong background in programming languages such as Python and SQL, as well as experience with big data processing frameworks such as Hadoop and Spark. You should also have a deep understanding of data warehousing solutions such as Amazon Redshift and Google BigQuery, and be able to design and implement data models that are scalable, efficient, and easy to maintain.
Data engineering roles often require a bachelor’s degree in computer science, engineering, or a related field. However, many data engineers also have advanced degrees, such as a master’s degree in data engineering, data science, or a related field. In addition to formal education, data engineers should have a strong understanding of data architecture, data modeling, and data warehousing.
In addition to technical skills, data engineers should also have strong communication and collaboration skills, as they often work closely with data scientists, analysts, and other stakeholders to deliver data-driven solutions. Data engineers should be able to explain complex technical concepts in simple terms, and work effectively with cross-functional teams to deliver high-quality data-driven solutions.
To gain experience in data engineering, consider taking online courses or participating in data engineering bootcamps. Many organizations also offer internships or apprenticeships in data engineering, providing valuable hands-on experience and the opportunity to work on real-world data engineering projects.
In summary, to become a data engineer, you need a strong background in programming languages, big data processing frameworks, and data warehousing solutions. You should also have a deep understanding of data architecture, data modeling, and data warehousing, as well as strong communication and collaboration skills. Consider pursuing a bachelor’s or advanced degree in a related field, and gain experience through online courses, bootcamps, or internships. With the right skills and experience, you can build a successful career in data engineering and help organizations leverage their data to drive business success.

Real-World Data Engineering Solutions: Case Studies and Examples
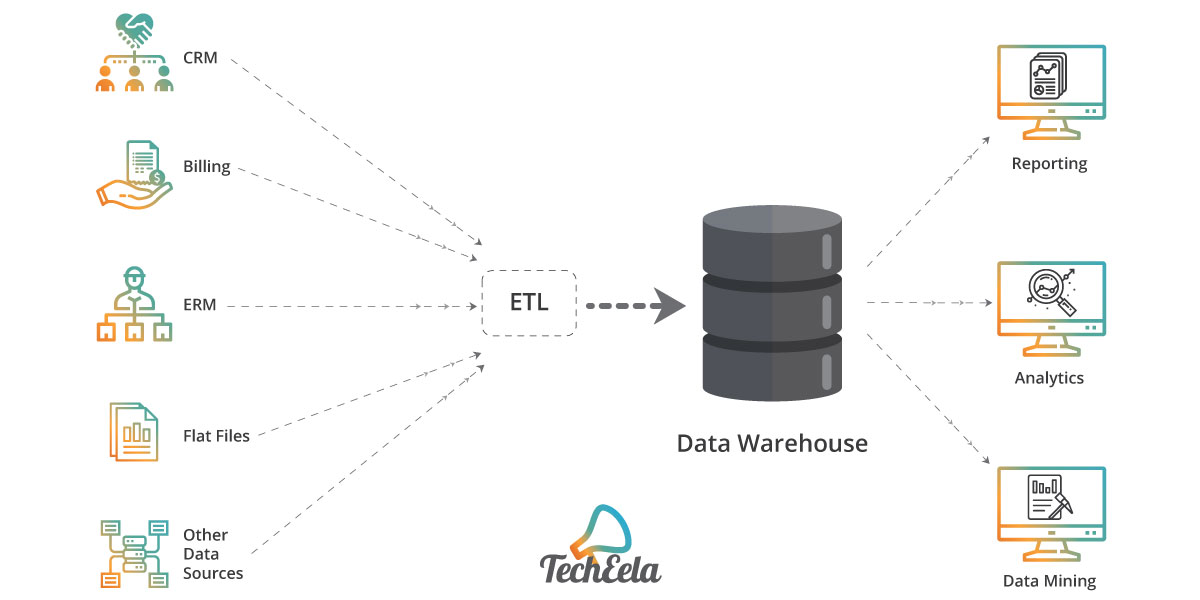
Data engineering plays a critical role in enabling data-driven decision-making for organizations. By designing, building, and maintaining data infrastructure, data engineers help organizations leverage their data to gain insights, improve operational efficiency, and drive innovation. Here are some examples of real-world data engineering solutions: Building Data Pipelines for ETL (Extract, Transform, Load) Processes
Data pipelines are essential for moving data between systems and transforming it into a usable format for analysis. Data engineers are responsible for building and maintaining these data pipelines, ensuring that data is accurate, complete, and consistent. For example, a data engineer at a retail company might build a data pipeline to extract sales data from various sources, transform it into a standardized format, and load it into a data warehouse for analysis.
Optimizing Data Warehousing Solutions for Big Data
Data warehousing solutions are essential for storing and managing large volumes of data. However, traditional data warehousing solutions can struggle to handle the volume, variety, and velocity of big data. Data engineers are responsible for optimizing data warehousing solutions for big data, ensuring that data is stored and managed efficiently and effectively. For example, a data engineer at a healthcare company might optimize a data warehousing solution to handle large volumes of genomic data, enabling researchers to analyze the data and gain insights into disease patterns and treatment outcomes.
Implementing Machine Learning Algorithms for Predictive Analytics
Machine learning algorithms are essential for making predictions based on data. Data engineers are responsible for implementing these algorithms, ensuring that they are accurate, efficient, and scalable. For example, a data engineer at a financial services company might implement a machine learning algorithm to predict credit risk, enabling the company to make better-informed lending decisions.
Impact of Data Engineering Solutions on Business Outcomes and Decision-Making
Data engineering solutions can have a significant impact on business outcomes and decision-making. By enabling data-driven decision-making, data engineering solutions can help organizations improve operational efficiency, reduce costs, and drive innovation. For example, a data engineering solution at a manufacturing company might enable the company to optimize its supply chain, reducing costs and improving delivery times. A data engineering solution at a healthcare company might enable researchers to gain insights into disease patterns and treatment outcomes, leading to new treatments and improved patient outcomes.
In summary, data engineering solutions can have a significant impact on business outcomes and decision-making. By building data pipelines, optimizing data warehousing solutions, and implementing machine learning algorithms, data engineers help organizations leverage their data to gain insights, improve operational efficiency, and drive innovation. If you’re interested in a career in data engineering, now is a great time to get started, as demand for data engineering talent is expected to continue to grow in the coming years.
Data Engineering Tools and Technologies: A Comparison
Data engineering involves working with large volumes of data, and there are many tools and technologies available to help data engineers design, build, and maintain data infrastructure. Here are some of the most popular data engineering tools and technologies, compared and contrasted: Hadoop
Hadoop is an open-source framework for storing and processing large volumes of data. It is highly scalable and fault-tolerant, making it a popular choice for big data processing. However, Hadoop can be complex to set up and manage, and it may not be the best choice for real-time data processing.
Spark
Spark is a fast and general-purpose cluster computing system. It can be used for batch processing, real-time data streaming, machine learning, and graph processing. Spark is designed to be user-friendly and easy to use, with a simple API and support for multiple programming languages. However, Spark can be resource-intensive and may not be the best choice for very large datasets.
Flink
Flink is a stream processing framework that can process data in real-time. It is designed to be fast and efficient, with low-latency data processing and support for event time processing. Flink can be used for batch processing, real-time data streaming, and machine learning. However, Flink can be complex to set up and manage, and it may not be the best choice for very large datasets.
Selecting the Right Tools for the Job
When selecting data engineering tools and technologies, it is important to consider factors such as data volume, variety, and velocity. For example, if you are working with very large datasets, you may need to use a tool such as Hadoop or Spark that is designed for big data processing. If you need to process data in real-time, you may need to use a tool such as Flink that is designed for stream processing.
It is also important to consider the skills and experience of your data engineering team. Some tools and technologies may be more familiar to your team than others, and it may be easier to use tools that your team is already familiar with.
Emphasizing the Importance of Continuous Learning
The field of data engineering is constantly evolving, with new tools and technologies emerging all the time. To stay up-to-date with the latest trends and best practices, it is important for data engineers to engage in continuous learning. This may involve attending conferences, taking online courses, or reading industry publications.
In summary, there are many data engineering tools and technologies available, each with its own strengths and weaknesses. When selecting tools and technologies, it is important to consider factors such as data volume, variety, and velocity, as well as the skills and experience of your data engineering team. To stay up-to-date with the latest trends and best practices, data engineers should engage in continuous learning and stay up-to-date with the latest tools and technologies in the field.

Data Engineering Best Practices: Tips and Recommendations
Data engineering is a complex and constantly evolving field, and it is important for data engineers to follow best practices to ensure the success of their projects. Here are some tips and recommendations for data engineering best practices: Version Control for Data Pipelines
Version control is a critical best practice for data engineering, allowing data engineers to track changes to data pipelines and easily revert to previous versions if necessary. Version control can also help ensure that different team members are working on the same version of a data pipeline, reducing the risk of conflicts and errors.
Automated Testing and Monitoring
Automated testing and monitoring are essential for ensuring the reliability and accuracy of data pipelines. By automating testing and monitoring, data engineers can quickly identify and address issues before they become major problems. Automated testing and monitoring can also help ensure that data pipelines are meeting business requirements and delivering value to the organization.
Data Security and Privacy
Data security and privacy are critical considerations for data engineering projects. Data engineers should follow best practices for data encryption, access control, and other security measures to ensure that data is protected from unauthorized access or use. Data engineers should also be aware of privacy regulations such as GDPR and CCPA, and ensure that their data engineering projects are compliant with these regulations.
Continuous Integration and Delivery (CI/CD)
CI/CD is a best practice for software development, and it is also applicable to data engineering. By implementing CI/CD, data engineers can automate the build, test, and deployment of data pipelines, reducing the risk of errors and improving the speed and efficiency of data engineering projects.
Automating Repetitive Tasks
Data engineering often involves repetitive tasks such as data cleaning, transformation, and loading. By automating these tasks, data engineers can save time and reduce the risk of errors. Automation can also help ensure that data is consistent and accurate, improving the quality of data analysis and machine learning models.
Staying Up-to-Date with the Latest Technologies and Trends
The field of data engineering is constantly evolving, with new tools and technologies emerging all the time. To stay up-to-date with the latest trends and best practices, data engineers should engage in continuous learning and stay up-to-date with the latest technologies and trends in the field.
In summary, data engineering best practices are essential for ensuring the success of data engineering projects. By following best practices such as version control, automated testing and monitoring, data security and privacy, CI/CD, automating repetitive tasks, and staying up-to-date with the latest technologies and trends, data engineers can deliver high-quality data infrastructure that enables data-driven decision-making for organizations.
Data Engineering Trends and Future Directions
Data engineering is a rapidly evolving field, with new technologies and trends emerging all the time. Here are some of the most important trends and future directions in data engineering: The Rise of Serverless Computing
Serverless computing is an emerging trend in data engineering, allowing data engineers to build and run applications without having to manage servers or infrastructure. Serverless computing can help data engineers save time and reduce costs, and it is well-suited to data engineering tasks such as data processing and analytics.
The Impact of Artificial Intelligence and Machine Learning on Data Engineering
Artificial intelligence (AI) and machine learning (ML) are having a major impact on data engineering, enabling data engineers to build more sophisticated and intelligent data pipelines. AI and ML can help data engineers automate data cleaning, transformation, and loading tasks, and they can also be used to build predictive models and improve data analysis.
The Importance of Data Governance and Ethics
Data governance and ethics are becoming increasingly important in data engineering, as organizations seek to ensure that their data is accurate, reliable, and secure. Data engineers should be aware of best practices for data governance and ethics, and they should work closely with data governance teams to ensure that data is being used in a responsible and ethical manner.
The Need for Data Engineers to Stay Up-to-Date with the Latest Technologies and Trends
To be successful in data engineering, it is essential to stay up-to-date with the latest technologies and trends. Data engineers should engage in continuous learning, attending conferences, taking online courses, and reading industry publications to stay up-to-date with the latest developments in the field.
Preparing for the Future of Data Engineering
The future of data engineering is likely to be characterized by increasing complexity, as organizations seek to leverage larger and more diverse datasets for data-driven decision-making. To prepare for the future of data engineering, data engineers should focus on building a strong foundation in programming languages, big data processing frameworks, and data warehousing solutions. They should also develop strong communication and collaboration skills, and work closely with data scientists, analysts, and other stakeholders to ensure that data engineering projects are aligned with business goals and objectives.
In summary, data engineering is a rapidly evolving field, with new technologies and trends emerging all the time. To be successful in data engineering, it is essential to stay up-to-date with the latest trends and best practices, and to be prepared to adapt to changing circumstances. By focusing on building a strong foundation in programming languages, big data processing frameworks, and data warehousing solutions, and by developing strong communication and collaboration skills, data engineers can be well-positioned to succeed in the data-driven economy of the future.
Conclusion: The Value of Data Engineering for Business Success
Data engineering is a critical component of modern business, enabling organizations to harness the power of data for data-driven decision-making, improved operational efficiency, and innovation. By investing in data engineering talent and infrastructure, organizations can gain a competitive edge in today’s data-driven economy. Data engineers play a vital role in designing, building, and maintaining data infrastructure for data analysis and machine learning purposes. They are responsible for ensuring that data is accurate, reliable, and secure, and that data pipelines are scalable, efficient, and effective.
To be successful in data engineering, it is essential to have a strong foundation in programming languages, big data processing frameworks, and data warehousing solutions. However, technical skills are only part of the equation. Data engineers must also have strong communication and collaboration skills, and be able to work effectively with data scientists, analysts, and other stakeholders.
Real-world data engineering solutions can have a significant impact on business outcomes and decision-making. By building data pipelines for ETL processes, optimizing data warehousing solutions for big data, and implementing machine learning algorithms for predictive analytics, data engineers can help organizations make better decisions, improve operational efficiency, and drive innovation.
To stay up-to-date with the latest trends and best practices in data engineering, it is important to engage in continuous learning and stay up-to-date with the latest technologies and trends in the field. Emerging trends such as serverless computing, the impact of artificial intelligence and machine learning on data engineering, and the importance of data governance and ethics are all critical areas of focus for data engineers.
In summary, data engineering is a vital component of modern business, enabling data-driven decision-making, improved operational efficiency, and innovation. By investing in data engineering talent and infrastructure, organizations can gain a competitive edge in today’s data-driven economy. Data engineers play a critical role in designing, building, and maintaining data infrastructure, and must have a strong foundation in technical skills, communication and collaboration skills, and continuous learning to be successful in the field.
