
What is a Recurrent Neural Network?
Recurrent Neural Networks (RNNs) are a type of artificial neural network that excel at recognizing patterns in sequences of data, such as text, genomes, handwriting, or spoken words. Unlike other neural networks, RNNs have a unique feature: they can store information about previous inputs in memory, allowing them to learn from experience and make predictions based on that knowledge.
RNNs are particularly well-suited for processing sequential data because they have a form of internal memory, which captures information about what has been calculated so far. In other words, RNNs have loops that allow information to be passed from one step in the network to the next. This feature enables RNNs to learn from the context present in the sequence data, making them highly effective for tasks such as natural language processing, speech recognition, time series prediction, and music generation.
The concept of hidden states is crucial to understanding how RNNs function. Hidden states are vectors of information that represent the summary of the sequence seen so far. At each time step, the RNN updates the hidden state by incorporating the new input and the previous hidden state. This process allows the RNN to maintain an understanding of the sequence context and use it to make predictions or generate outputs.
Training RNNs involves optimizing their internal parameters using the backpropagation through time algorithm. This algorithm extends the standard backpropagation algorithm to handle sequences of data by unrolling the network across time steps. However, training RNNs can be challenging due to the vanishing and exploding gradient problems, which can hinder the network’s ability to learn long-term dependencies in the data.
In summary, Recurrent Neural Networks are a powerful class of artificial neural networks designed to recognize patterns in sequences of data by storing information about previous inputs in memory. Their unique architecture and ability to learn from context make them invaluable for various applications, including natural language processing, speech recognition, time series prediction, and music generation. Despite the challenges in training RNNs, they remain a vital tool in the machine learning toolbox, offering significant potential for innovation and creativity in problem-solving.
How do Recurrent Neural Networks Work?
Recurrent Neural Networks (RNNs) are designed to process sequential data by maintaining a form of internal memory that captures information about previous inputs. This memory mechanism enables RNNs to recognize patterns in sequences of data and make predictions based on that knowledge.
The internal workings of RNNs revolve around the concept of hidden states. Hidden states are vectors of information that represent the summary of the sequence seen so far. At each time step, the RNN updates the hidden state by incorporating the new input and the previous hidden state. This process allows the RNN to maintain an understanding of the sequence context and use it to make predictions or generate outputs.
Mathematically, the hidden state at time step t, denoted as h(t), can be calculated as follows:
h(t) = f(W * x(t) + U * h(t-1) + b)
where:
x(t) is the input at time step t
W and U are the weight matrices for the input and previous hidden state, respectively
b is the bias term
f is the activation function, such as the hyperbolic tangent or rectified linear unit (ReLU) function
The backpropagation through time (BPTT) algorithm is used to train RNNs. BPTT extends the standard backpropagation algorithm to handle sequences of data by unrolling the network across time steps. During training, the weights and biases are adjusted to minimize the difference between the predicted output and the actual target value.
However, training RNNs can be challenging due to the vanishing and exploding gradient problems. The vanishing gradient problem occurs when the gradients used to update the weights become too small, making it difficult for the network to learn long-term dependencies in the data. The exploding gradient problem, on the other hand, happens when the gradients become too large, causing the weights to oscillate or diverge.
To illustrate the concept of RNNs, consider a simple example where the task is to predict the next word in a sentence. Suppose the input sequence is [“I”, “like”, “to”, “eat”], and the RNN has already processed the first three words. At this point, the hidden state h(3) encapsulates the context of the sentence up to “to”. When the input “eat” is presented, the RNN updates the hidden state to h(4) and generates a probability distribution over the vocabulary space to predict the next word.
In summary, Recurrent Neural Networks work by maintaining internal memory through hidden states, which capture information about previous inputs. The backpropagation through time algorithm is used to train RNNs, but the vanishing and exploding gradient problems can make training challenging. Despite these challenges, RNNs remain a powerful tool for processing sequential data, as demonstrated in applications such as natural language processing, speech recognition, time series prediction, and music generation.
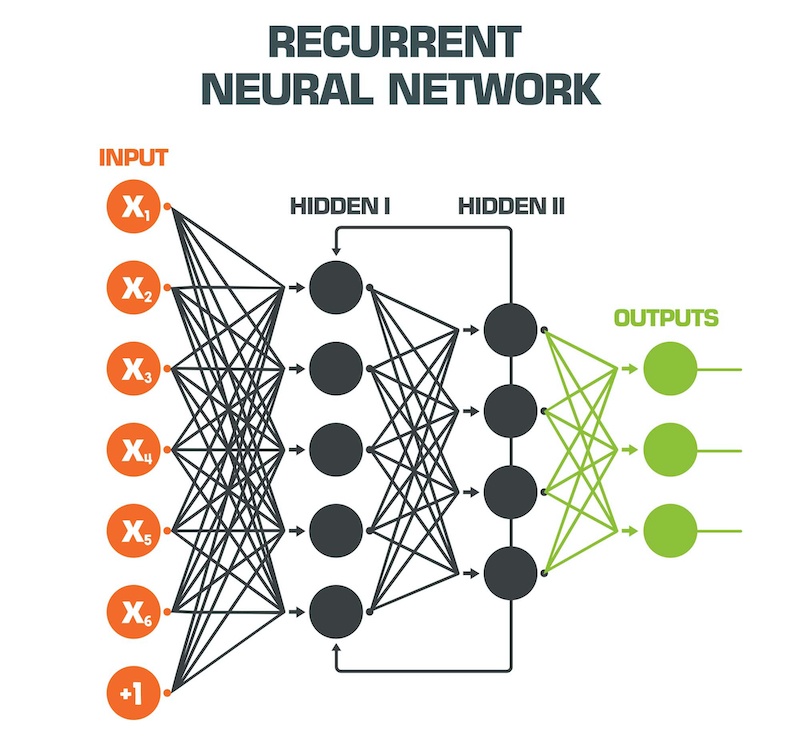
Use Cases and Applications of Recurrent Neural Networks
Recurrent Neural Networks (RNNs) have proven to be highly effective in various applications, particularly those involving sequential data. Some of the primary use cases and applications of RNNs include:
1. Natural Language Processing (NLP)
RNNs are widely used in NLP tasks, such as language modeling, sentiment analysis, and machine translation. They can capture the context present in text data, making them well-suited for understanding the nuances of human language. However, RNNs can struggle with long sequences due to the vanishing gradient problem, which may lead to poor performance in certain NLP scenarios.
2. Speech Recognition
RNNs are instrumental in converting spoken language into written text, as they can model the temporal dependencies present in audio data. By analyzing the patterns in speech signals, RNNs can effectively transcribe spoken words into written form. However, RNNs may face challenges in handling noisy audio data, which can negatively impact their performance.
3. Time Series Prediction
RNNs excel at predicting future values in time series data, such as stock prices, weather patterns, or sensor readings. By learning the patterns and trends in historical data, RNNs can generate accurate predictions for future time points. Nevertheless, RNNs may struggle with seasonal or periodic patterns that are not easily captured by their internal memory mechanisms.
4. Music Generation
RNNs can be used to generate musical compositions by learning the patterns and structures present in various musical styles. By analyzing sequences of notes, RNNs can generate new musical phrases that mimic the style of the input data. However, RNNs may not fully capture the complexities of human-composed music, leading to generated compositions that may sound less sophisticated than their original counterparts.
In summary, Recurrent Neural Networks have numerous applications in various domains, including natural language processing, speech recognition, time series prediction, and music generation. While RNNs offer several advantages in these scenarios, they also have limitations, such as the vanishing gradient problem and difficulty handling noisy or complex data. Despite these challenges, RNNs remain a powerful tool for processing sequential data, offering significant potential for innovation and creativity in problem-solving.
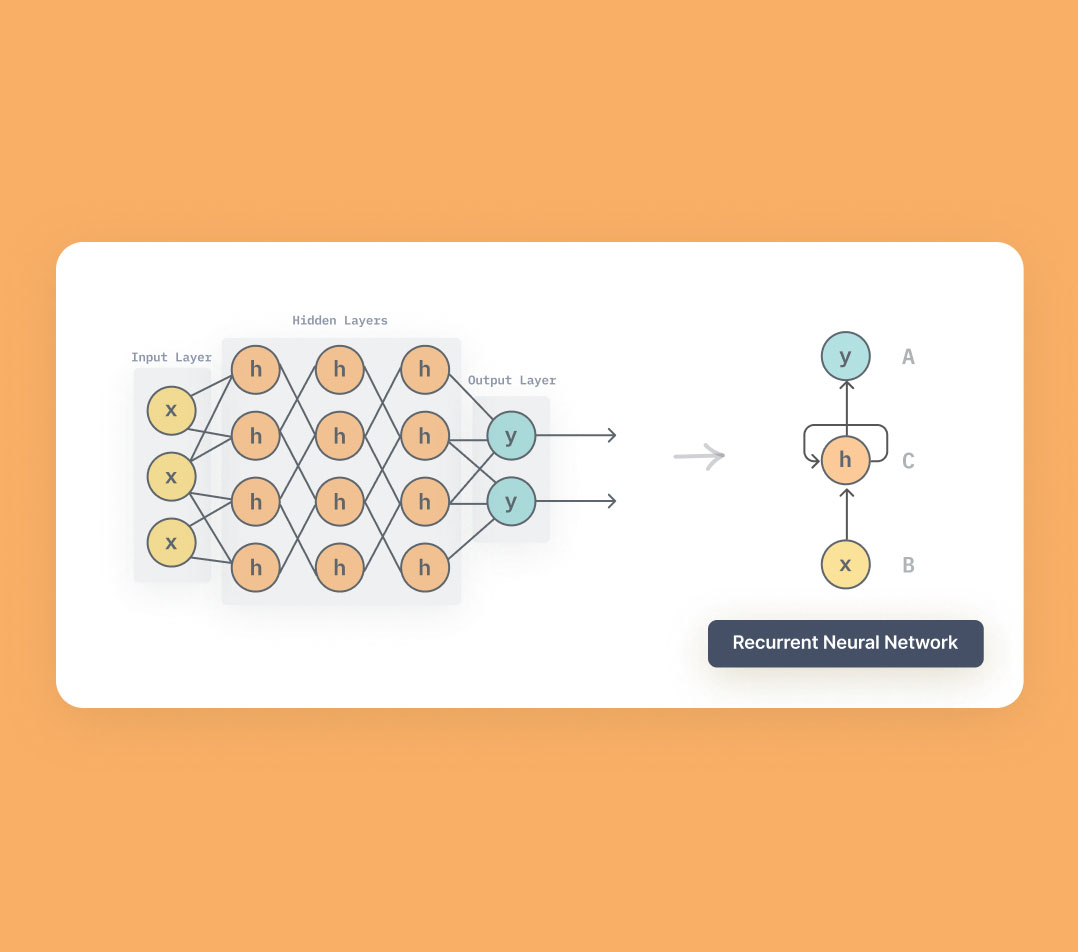
Popular Recurrent Neural Network Architectures
While the basic Recurrent Neural Network (RNN) architecture provides a foundation for processing sequential data, several popular variants have been developed to address specific challenges, such as the vanishing and exploding gradient problems. Two prominent RNN architectures are Long Short-Term Memory (LSTM) and Gated Recurrent Units (GRU).
1. Long Short-Term Memory (LSTM)
LSTM is a type of RNN designed to address the vanishing gradient problem, enabling the network to learn long-term dependencies in the data. The key innovation in LSTM is the introduction of memory cells and gating mechanisms that control the flow of information through the network. An LSTM unit consists of three primary components: the input gate, the forget gate, and the output gate. The input gate determines which new information should be stored in the memory cell, the forget gate decides which information should be discarded from the memory cell, and the output gate controls which information should be used to compute the output activation.
2. Gated Recurrent Units (GRU)
GRU is a simplified version of LSTM that combines the input and forget gates into a single update gate, reducing the overall complexity of the network. This simplification allows GRU to have fewer parameters than LSTM, making it faster to train and implement. Like LSTM, GRU uses memory cells and gating mechanisms to control the flow of information through the network. However, GRU has only two gates: the update gate and the reset gate. The update gate determines how much of the past and present information should be combined, while the reset gate decides how much of the past information should be forgotten.
Both LSTM and GRU have proven to be effective in various applications, such as natural language processing, speech recognition, and time series prediction. The choice between LSTM and GRU often depends on the specific problem requirements and the available computational resources.
In summary, Long Short-Term Memory (LSTM) and Gated Recurrent Units (GRU) are two popular RNN architectures that address the vanishing and exploding gradient problems. LSTM uses memory cells and gating mechanisms to learn long-term dependencies, while GRU simplifies the LSTM architecture by combining the input and forget gates into a single update gate. Both LSTM and GRU have demonstrated success in various applications, and the choice between them depends on the specific problem requirements and available resources.

Training and Implementing Recurrent Neural Networks
Training Recurrent Neural Networks (RNNs) involves several steps, including data preprocessing, model selection, and evaluation metrics. Here, we will discuss these aspects in detail and provide tips for successful implementation.
1. Data Preprocessing
Data preprocessing is a crucial step in training RNNs, as it ensures that the input data is in a format suitable for the network. Preprocessing techniques include tokenization, normalization, and padding. Tokenization involves breaking down sequences into individual tokens, such as words or characters. Normalization scales the input data to a common range, while padding adds artificial tokens to sequences to ensure uniform sequence lengths.
2. Model Selection
Selecting the appropriate RNN architecture is essential for successful training. Basic RNNs, Long Short-Term Memory (LSTM) networks, and Gated Recurrent Units (GRU) are common RNN architectures. The choice of architecture depends on the specific problem requirements and the available computational resources. LSTM and GRU networks are often preferred for tasks requiring the modeling of long-term dependencies.
3. Evaluation Metrics
Evaluation metrics are used to assess the performance of RNNs during training and testing. Common evaluation metrics include accuracy, perplexity, and loss. Accuracy measures the proportion of correct predictions, while perplexity quantifies the uncertainty of the network’s predictions. Loss measures the difference between the predicted and actual outputs, guiding the optimization process during training.
Challenges of Training RNNs
Training RNNs can be challenging due to the vanishing and exploding gradient problems, which can hinder the network’s ability to learn long-term dependencies. Techniques such as gradient clipping, weight initialization, and regularization can help mitigate these issues. Additionally, monitoring the training process using visualizations and early stopping can prevent overfitting and improve overall performance.
Tips for Successful Implementation
To successfully implement RNNs, consider the following tips:
- Start with a simple architecture and gradually increase complexity as needed.
- Experiment with different hyperparameters, such as learning rate, batch size, and sequence length.
- Use pre-trained models and transfer learning to leverage existing knowledge and reduce training time.
- Monitor the training process using visualizations and evaluation metrics to ensure stable learning and prevent overfitting.
In summary, training Recurrent Neural Networks involves data preprocessing, model selection, and evaluation metrics. Challenges such as the vanishing and exploding gradient problems can be mitigated using various techniques. By following best practices and tips for successful implementation, RNNs can be effectively trained and applied to various applications, such as natural language processing, speech recognition, and time series prediction.
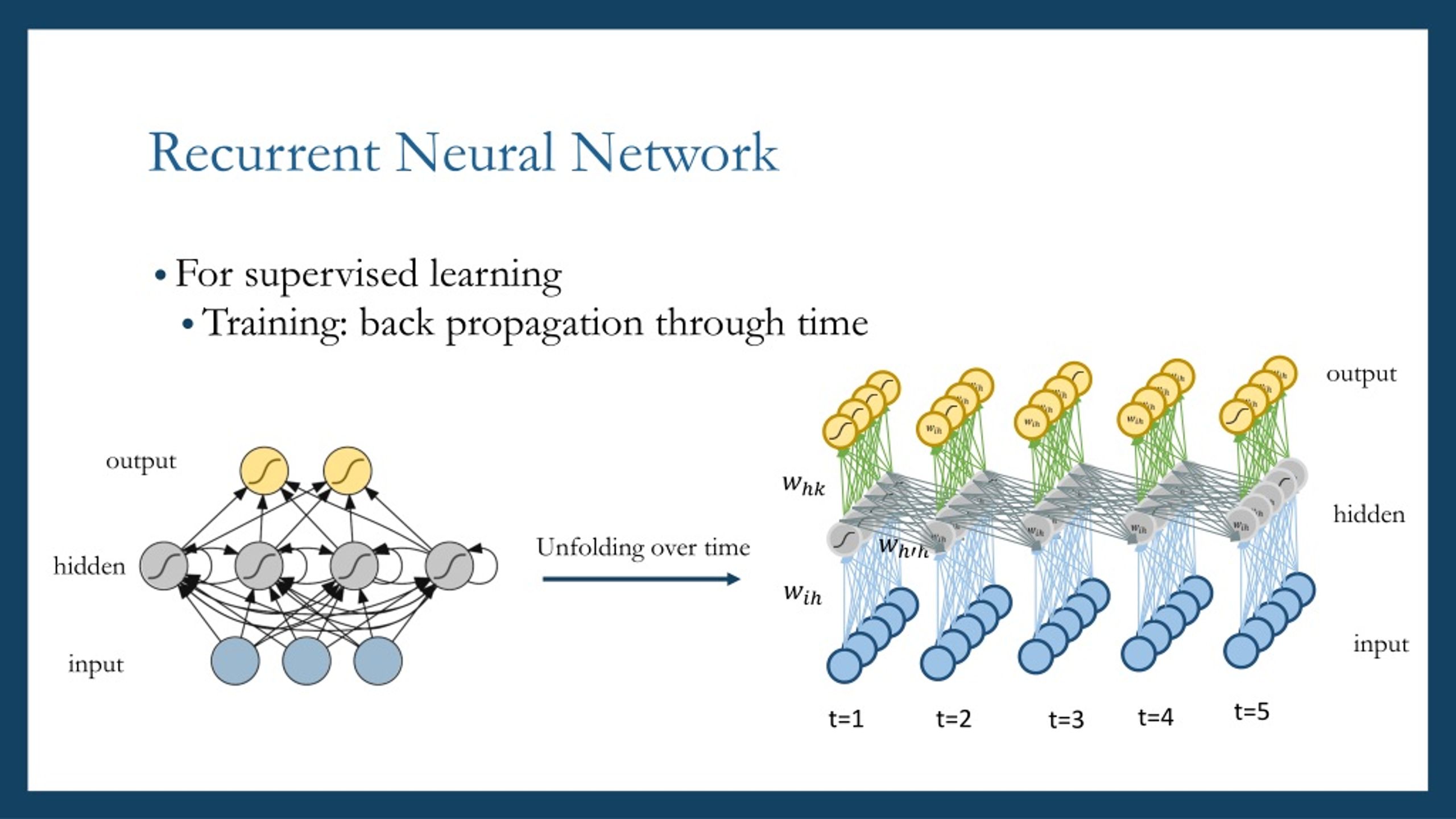
Comparing Recurrent Neural Networks to Other Neural Network Types
Recurrent Neural Networks (RNNs) are a powerful tool for processing sequential data, but they are not the only type of artificial neural network. Here, we will compare RNNs to other neural network types, such as Convolutional Neural Networks (CNNs) and Feedforward Neural Networks (FNNs), emphasizing their unique strengths and weaknesses and when to use them.
1. Recurrent Neural Networks (RNNs) vs. Feedforward Neural Networks (FNNs)
FNNs are the simplest type of artificial neural network, consisting of an input layer, one or more hidden layers, and an output layer. Unlike RNNs, FNNs do not have feedback connections and cannot process sequential data directly. However, FNNs are suitable for tasks with fixed-size input and output, such as image classification or regression problems.
2. Recurrent Neural Networks (RNNs) vs. Convolutional Neural Networks (CNNs)
CNNs are a specialized type of neural network designed for processing grid-like data, such as images. Unlike RNNs, CNNs do not have feedback connections and are not well-suited for processing sequential data directly. However, CNNs are highly effective in tasks such as image recognition, object detection, and semantic segmentation.
Choosing the Right Neural Network Type
Selecting the appropriate neural network type depends on the specific problem requirements and the available data. RNNs are ideal for tasks involving sequential data, such as natural language processing, speech recognition, and time series prediction. FNNs are suitable for tasks with fixed-size input and output, such as image classification or regression problems. CNNs are highly effective in tasks involving grid-like data, such as image recognition, object detection, and semantic segmentation.
Combining Neural Network Types
In some cases, combining different neural network types can lead to improved performance. For example, CNNs can be used as a feature extractor for RNNs in tasks such as video action recognition or image captioning. Additionally, FNNs can be used as a classifier for RNNs in tasks such as sentiment analysis or named entity recognition.
In summary, Recurrent Neural Networks (RNNs) are a powerful tool for processing sequential data, but they are not the only type of artificial neural network. Comparing RNNs to other neural network types, such as Convolutional Neural Networks (CNNs) and Feedforward Neural Networks (FNNs), highlights their unique strengths and weaknesses and when to use them. Selecting the appropriate neural network type depends on the specific problem requirements and the available data. Combining different neural network types can also lead to improved performance in certain tasks.
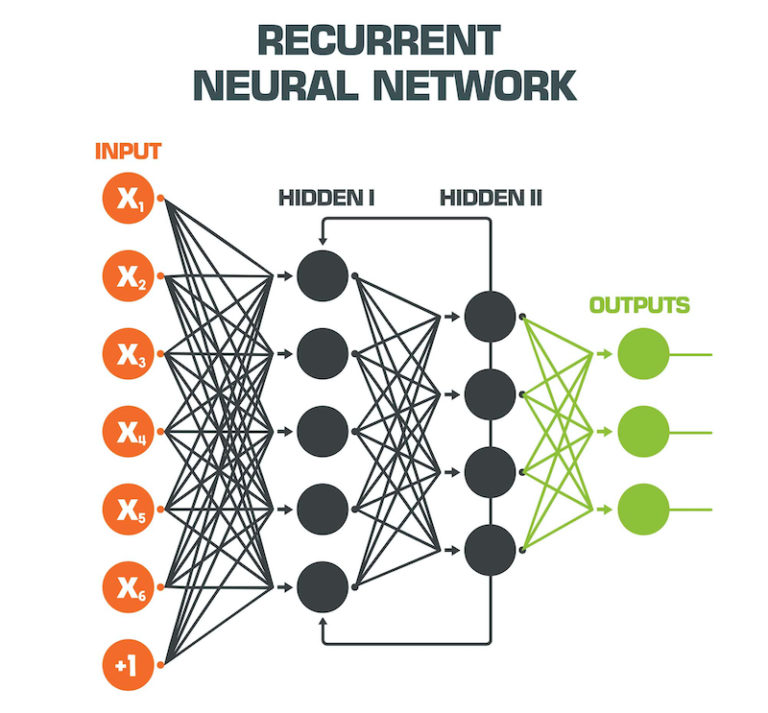
Ethical Considerations and Future Directions for Recurrent Neural Networks
Recurrent Neural Networks (RNNs) have proven to be a powerful tool for processing sequential data, with applications in various domains such as natural language processing, speech recognition, and time series prediction. However, ethical considerations and future research directions are essential to explore as RNNs become more prevalent in real-world applications.
1. Privacy Concerns
RNNs often deal with sensitive data, such as personal communications or medical records. Ensuring the privacy and security of this data is crucial to prevent unauthorized access and potential misuse. Techniques such as differential privacy, secure multi-party computation, and homomorphic encryption can help protect sensitive data while still allowing for meaningful analysis.
2. Potential Biases
RNNs can inadvertently perpetuate and amplify existing biases in the data, leading to unfair or discriminatory outcomes. Ensuring that RNN models are transparent, interpretable, and fair is essential to prevent unintended consequences. Techniques such as explainable AI, fairness-aware machine learning, and adversarial debiasing can help mitigate potential biases in RNN models.
3. Impact on Employment
As RNNs become more proficient in tasks traditionally performed by humans, concerns about job displacement and the future of work arise. It is crucial to consider the ethical implications of automation and develop strategies to minimize its negative impact on employment. This may include retraining programs, education initiatives, and policies that promote the responsible use of automation technologies.
Future Directions for RNN Research
Several areas of research are poised to advance the capabilities of RNNs, including advancements in hardware, software, and algorithmic design. Novel hardware architectures, such as neuromorphic computing and quantum computing, have the potential to significantly accelerate RNN training and inference. Improved software frameworks and libraries can make RNNs more accessible and easier to use for a broader range of applications. Additionally, ongoing research in algorithmic design, such as attention mechanisms, transformers, and graph neural networks, can further enhance the capabilities of RNNs and expand their range of applications.
In summary, ethical considerations related to Recurrent Neural Networks (RNNs) include privacy concerns, potential biases, and the impact on employment. Future research directions for RNNs include advancements in hardware, software, and algorithmic design. Addressing these ethical considerations and investing in future research are essential to ensure the responsible and effective use of RNNs in various applications. By doing so, we can unlock the full potential of RNNs while minimizing their negative consequences and promoting their positive impact on society.
.jpg)