
Understanding Kube Scheduler: The Heart of Kubernetes Cluster Management
Kube Scheduler is a critical component of Kubernetes cluster management that plays a pivotal role in assigning Pods to Nodes based on resource availability, constraints, and other factors. The Kube Scheduler is responsible for making informed decisions about where to place Pods to ensure optimal cluster performance and seamless application deployment and scaling. Given the importance of this role, it is essential to configure the Kube Scheduler appropriately to meet the unique needs of your Kubernetes environment.
Configuring the Kube Scheduler involves adjusting various parameters and settings to ensure that Pods are scheduled on appropriate Nodes based on resource requirements, availability, and other constraints. By optimizing the Kube Scheduler configuration, you can improve cluster performance, reduce downtime, and ensure that applications are deployed and scaled efficiently. In this article, we will explore the key components of Kube Scheduler configuration and provide best practices for configuring PredicateRules, PriorityRules, and BindingRules to meet the needs of your Kubernetes environment.
At a high level, the Kube Scheduler is responsible for making scheduling decisions based on the following factors:
- Resource availability: The Kube Scheduler ensures that Pods are scheduled on Nodes with sufficient resources to meet their requirements.
- Constraints: The Kube Scheduler ensures that Pods are scheduled on Nodes that meet specific constraints, such as node labels, taints, and tolerations.
- Affinity and anti-affinity: The Kube Scheduler ensures that Pods are scheduled on Nodes based on affinity and anti-affinity rules, which specify which Nodes a Pod should or should not be scheduled on.
- Pod priority: The Kube Scheduler ensures that Pods with higher priority are scheduled before Pods with lower priority.
- Custom scheduling policies: The Kube Scheduler allows for custom scheduling policies to be defined, which can be used to implement complex scheduling requirements.
By configuring the Kube Scheduler appropriately, you can ensure that Pods are scheduled on Nodes that meet their resource requirements, constraints, and other factors. This, in turn, can help to improve cluster performance, reduce downtime, and ensure that applications are deployed and scaled efficiently.

Key Components of Kube Scheduler Configuration
The Kube Scheduler configuration consists of three main components: PredicateRules, PriorityRules, and BindingRules. These components work together to make informed scheduling decisions based on the current state of the Kubernetes cluster and the requirements of the Pods being scheduled. By understanding how these components interact with each other and with the Kubernetes API, you can optimize the Kube Scheduler configuration to meet the unique needs of your environment.
PredicateRules: Ensuring Pods Meet Node Requirements
PredicateRules are used to determine whether a Node is a viable candidate for scheduling a particular Pod. These rules evaluate various factors, such as resource availability, node affinity, and constraints, to ensure that the Pod can be scheduled on the Node without violating any constraints or policies. PredicateRules are evaluated in a series of filters, with each filter returning a list of Nodes that meet the specified criteria. Once all filters have been evaluated, the Kube Scheduler selects the Node with the highest score as the target for scheduling the Pod.
PriorityRules: Optimizing Scheduling Decisions
PriorityRules are used to rank Nodes based on various factors, such as resource availability, Pod affinity, and custom priority functions. These rules are evaluated after PredicateRules have been applied, and are used to determine the final Node that a Pod will be scheduled on. By configuring PriorityRules appropriately, you can optimize scheduling decisions based on business needs and application requirements, while balancing these priorities with resource availability and other constraints.
BindingRules: Ensuring Pods are Bound to Nodes
BindingRules are used to ensure that Pods are bound to Nodes in a timely and efficient manner. These rules are evaluated after a Node has been selected for scheduling a Pod, and are used to ensure that the Pod is actually scheduled on the Node. BindingRules can be used to handle node failures, resource contention, and other scheduling challenges, and can help to ensure that Pods are rescheduled appropriately in the event of disruptions.
Interactions between Components
PredicateRules, PriorityRules, and BindingRules interact with each other and with the Kubernetes API to make informed scheduling decisions. For example, PredicateRules may filter out Nodes that do not have sufficient resources to run a Pod, while PriorityRules may rank Nodes based on their available resources. Once a Node has been selected for scheduling a Pod, BindingRules are used to ensure that the Pod is actually scheduled on the Node. By understanding how these components interact, you can optimize the Kube Scheduler configuration to meet the unique needs of your environment.
In the next section, we will provide best practices for configuring PredicateRules to ensure that Pods are scheduled on appropriate Nodes based on resource requirements, availability, and other constraints.
Strategies for Configuring PredicateRules
PredicateRules are an essential component of Kube Scheduler configuration, as they determine whether a Node is a viable candidate for scheduling a particular Pod. By configuring PredicateRules appropriately, you can ensure that Pods are scheduled on Nodes that meet their resource requirements, constraints, and other factors. In this section, we will provide best practices for configuring PredicateRules to optimize cluster performance and ensure seamless application deployment and scaling.
Setting up Node Affinity and Anti-Affinity
Node affinity and anti-affinity rules allow you to specify which Nodes a Pod should or should not be scheduled on, based on node labels and other factors. By setting up node affinity and anti-affinity rules, you can ensure that Pods are scheduled on Nodes that meet specific criteria, such as being part of a particular availability zone or having access to specific resources. When configuring node affinity and anti-affinity rules, it is essential to balance the need for Pod placement with resource availability and other constraints.
Configuring Taints and Tolerations
Taints and tolerations allow you to mark Nodes as unsuitable for certain types of Pods, while still allowing those Pods to be scheduled if necessary. By configuring taints and tolerations, you can ensure that Pods are scheduled on Nodes that meet their resource requirements and other constraints, while also ensuring that Nodes are not overwhelmed with Pods that do not belong on them. When configuring taints and tolerations, it is essential to balance the need for Pod placement with resource availability and other constraints.
Using Custom Predicate Functions
Custom predicate functions allow you to create custom rules for evaluating Node suitability for Pod scheduling. By using custom predicate functions, you can implement complex scheduling requirements that are not possible with standard PredicateRules. When creating custom predicate functions, it is essential to ensure that they are efficient, reliable, and scalable, as they will be executed frequently during the scheduling process.
Balancing Resource Availability and Constraints
When configuring PredicateRules, it is essential to balance resource availability and constraints to ensure that Pods are scheduled on Nodes that meet their requirements while also ensuring that Nodes are not overwhelmed with Pods that do not belong on them. By using tools like the Kubernetes Horizontal Pod Autoscaler and Resource Quotas, you can ensure that Pods are scheduled on Nodes with sufficient resources to meet their requirements, while also ensuring that Nodes are not overwhelmed with too many Pods.
In the next section, we will discuss how to configure PriorityRules to optimize scheduling decisions based on business needs and application requirements, while balancing these priorities with resource availability and other constraints.
Maximizing Efficiency with PriorityRules
PriorityRules are an essential component of Kube Scheduler configuration, as they determine the order in which Nodes are considered for scheduling Pods. By configuring PriorityRules appropriately, you can optimize scheduling decisions based on business needs and application requirements, while balancing these priorities with resource availability and other constraints. In this section, we will discuss how to configure PriorityRules to ensure efficient and effective scheduling.
Using Custom Priority Functions
Custom priority functions allow you to create custom rules for evaluating Node suitability for Pod scheduling, based on business needs and application requirements. By using custom priority functions, you can implement complex scheduling requirements that are not possible with standard PriorityRules. When creating custom priority functions, it is essential to ensure that they are efficient, reliable, and scalable, as they will be executed frequently during the scheduling process.
Setting Priority Weights
Priority weights allow you to assign a weight to each Node, based on its suitability for Pod scheduling. By setting priority weights appropriately, you can ensure that Pods are scheduled on Nodes that meet their resource requirements and other constraints, while also ensuring that Nodes are not overwhelmed with Pods that do not belong on them. When setting priority weights, it is essential to balance the need for Pod placement with resource availability and other constraints.
Balancing Business Needs and Resource Availability
When configuring PriorityRules, it is essential to balance business needs and resource availability to ensure that Pods are scheduled on Nodes that meet their requirements while also ensuring that Nodes are not overwhelmed with Pods that do not belong on them. By using tools like the Kubernetes Horizontal Pod Autoscaler and Resource Quotas, you can ensure that Pods are scheduled on Nodes with sufficient resources to meet their requirements, while also ensuring that Nodes are not overwhelmed with too many Pods.
Using Multiple PriorityRules
By using multiple PriorityRules, you can implement complex scheduling requirements that are not possible with a single PriorityRule. For example, you may want to prioritize Pods based on their resource requirements, while also ensuring that Pods are scheduled on Nodes that meet specific availability or security requirements. When using multiple PriorityRules, it is essential to ensure that they are efficient, reliable, and scalable, as they will be executed frequently during the scheduling process.
In the next section, we will discuss how to configure BindingRules to ensure that Pods are bound to Nodes in a timely and efficient manner, and how to handle node failures, resource contention, and other scheduling challenges.
Implementing BindingRules for Seamless Scheduling
BindingRules are an essential component of Kube Scheduler configuration, as they determine how Pods are bound to Nodes. By configuring BindingRules appropriately, you can ensure that Pods are scheduled on Nodes that meet their resource requirements and other constraints, while also ensuring that Nodes are not overwhelmed with Pods that do not belong on them. In this section, we will discuss how to configure BindingRules to handle node failures, resource contention, and other scheduling challenges, and how to ensure that Pods are rescheduled appropriately in the event of disruptions.
Handling Node Failures
Node failures can occur due to hardware or software issues, and can result in Pods being evicted from the Node. By configuring BindingRules appropriately, you can ensure that Pods are rescheduled on Nodes that meet their resource requirements and other constraints, while also ensuring that Nodes are not overwhelmed with Pods that do not belong on them. When configuring BindingRules for node failures, it is essential to balance the need for Pod placement with resource availability and other constraints.
Managing Resource Contention
Resource contention can occur when multiple Pods compete for the same resources on a Node. By configuring BindingRules appropriately, you can ensure that Pods are scheduled on Nodes that have sufficient resources to meet their requirements, while also ensuring that Nodes are not overwhelmed with Pods that do not belong on them. When managing resource contention, it is essential to balance the need for Pod placement with resource availability and other constraints.
Rescheduling Pods
Rescheduling Pods can occur due to node failures, resource contention, or other scheduling challenges. By configuring BindingRules appropriately, you can ensure that Pods are rescheduled on Nodes that meet their resource requirements and other constraints, while also ensuring that Nodes are not overwhelmed with Pods that do not belong on them. When rescheduling Pods, it is essential to balance the need for Pod placement with resource availability and other constraints.
Using Multiple BindingRules
By using multiple BindingRules, you can implement complex scheduling requirements that are not possible with a single BindingRule. For example, you may want to prioritize Pods based on their resource requirements, while also ensuring that Pods are scheduled on Nodes that meet specific availability or security requirements. When using multiple BindingRules, it is essential to ensure that they are efficient, reliable, and scalable, as they will be executed frequently during the scheduling process.
In the next section, we will discuss common issues that can arise when configuring Kube Scheduler, and provide troubleshooting tips and best practices for resolving these issues and ensuring optimal cluster performance.
Troubleshooting Common Kube Scheduler Configuration Issues
Configuring Kube Scheduler can be a complex process, and there are several common issues that can arise. In this section, we will identify some of these issues and provide troubleshooting tips and best practices for resolving them and ensuring optimal cluster performance.
Misconfigured Rules
Misconfigured rules can result in Pods being scheduled on inappropriate Nodes, leading to resource contention, node failures, and other scheduling challenges. When configuring PredicateRules, PriorityRules, and BindingRules, it is essential to ensure that they are correctly specified and aligned with business needs and application requirements. When troubleshooting misconfigured rules, it is helpful to review the Kubernetes API logs and other diagnostic tools to identify the root cause of the issue.
Resource Contention
Resource contention can occur when multiple Pods compete for the same resources on a Node. When configuring Kube Scheduler, it is essential to balance the need for Pod placement with resource availability and other constraints. When troubleshooting resource contention, it is helpful to review the Kubernetes API logs and other diagnostic tools to identify the root cause of the issue, and to consider implementing resource quotas or other resource management strategies to prevent future contention.
Node Failures
Node failures can occur due to hardware or software issues, and can result in Pods being evicted from the Node. When configuring Kube Scheduler, it is essential to ensure that BindingRules are correctly specified to handle node failures and ensure that Pods are rescheduled on Nodes that meet their resource requirements and other constraints. When troubleshooting node failures, it is helpful to review the Kubernetes API logs and other diagnostic tools to identify the root cause of the issue, and to consider implementing node health checks or other node management strategies to prevent future failures.
Best Practices for Troubleshooting
When troubleshooting Kube Scheduler configuration issues, it is essential to follow best practices to ensure that the root cause of the issue is identified and resolved efficiently. Some best practices for troubleshooting Kube Scheduler configuration issues include:
- Reviewing the Kubernetes API logs and other diagnostic tools to identify the root cause of the issue.
- Testing and validating changes to Kube Scheduler configuration before deploying them to production environments.
- Maintaining up-to-date documentation on Kube Scheduler configuration and other cluster management tasks.
- Using tools like kubectl, kubeadm, and kubefed to simplify configuration management and ensure consistent performance across multiple clusters and environments.
In the next section, we will discuss best practices for managing Kube Scheduler configuration over time, including monitoring cluster performance, testing and validating changes, and maintaining documentation.
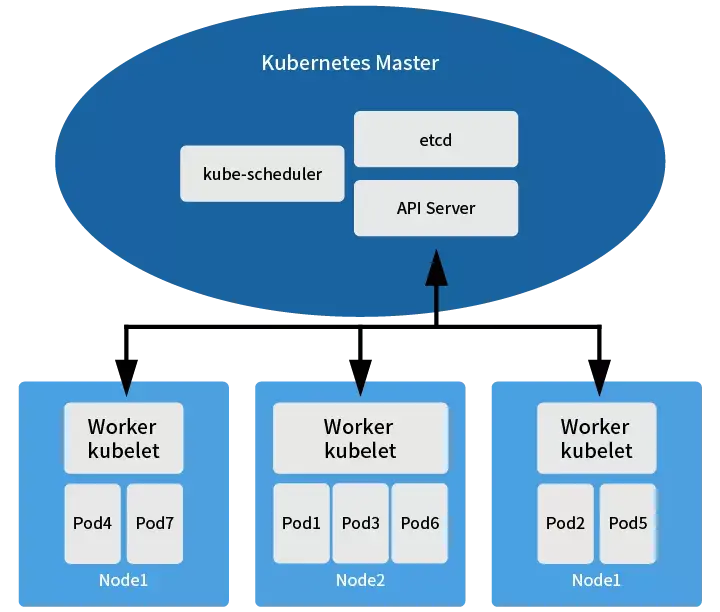
Best Practices for Long-Term Kube Scheduler Configuration Management
Managing Kube Scheduler configuration over time is essential for ensuring optimal cluster performance and seamless application deployment and scaling. In this section, we will discuss best practices for managing Kube Scheduler configuration, including monitoring cluster performance, testing and validating changes, and maintaining documentation.
Monitoring Cluster Performance
Monitoring cluster performance is essential for identifying issues and optimizing Kube Scheduler configuration. When monitoring cluster performance, it is essential to track key performance indicators (KPIs) such as resource utilization, Pod scheduling times, and node health. By monitoring these KPIs, you can identify issues such as resource contention, node failures, and other scheduling challenges, and take corrective action to prevent or mitigate these issues.
Testing and Validating Changes
Testing and validating changes to Kube Scheduler configuration is essential for ensuring that changes do not negatively impact cluster performance. When testing and validating changes, it is essential to use tools like kubectl, kubeadm, and kubefed to simulate changes in a controlled environment, and to validate that changes do not result in unintended consequences such as resource contention or node failures.
Maintaining Documentation
Maintaining up-to-date documentation on Kube Scheduler configuration and other cluster management tasks is essential for ensuring consistent performance across multiple clusters and environments. When maintaining documentation, it is essential to document key components of Kube Scheduler configuration, including PredicateRules, PriorityRules, and BindingRules, and to update documentation as changes are made to Kube Scheduler configuration.
Using Tools for Configuration Management
Using tools like kubectl, kubeadm, and kubefed can simplify configuration management and ensure consistent performance across multiple clusters and environments. When using these tools, it is essential to follow best practices for configuration management, such as testing and validating changes before deploying them to production environments, and maintaining up-to-date documentation on Kube Scheduler configuration and other cluster management tasks.
Best Practices for Long-Term Kube Scheduler Configuration Management
When managing Kube Scheduler configuration over time, it is essential to follow best practices to ensure optimal cluster performance and seamless application deployment and scaling. Some best practices for long-term Kube Scheduler configuration management include:
- Monitoring cluster performance and tracking key performance indicators (KPIs) such as resource utilization, Pod scheduling times, and node health.
- Testing and validating changes to Kube Scheduler configuration in a controlled environment before deploying them to production environments.
- Maintaining up-to-date documentation on Kube Scheduler configuration and other cluster management tasks.
- Using tools like kubectl, kubeadm, and kubefed to simplify configuration management and ensure consistent performance across multiple clusters and environments.
In the next section, we will explore emerging trends and future directions in Kube Scheduler configuration, such as machine learning-based scheduling, multi-cloud and hybrid cloud scheduling, and integration with other Kubernetes components and tools.
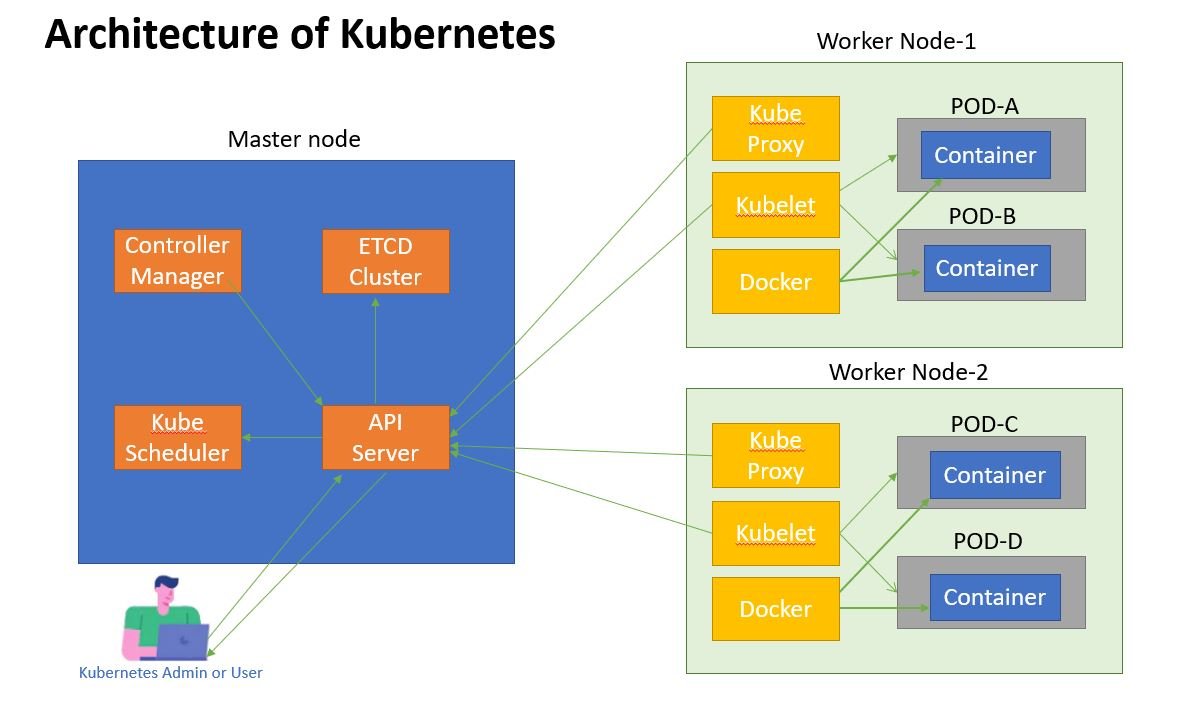
Emerging Trends and Future Directions in Kube Scheduler Configuration
Kubernetes is a rapidly evolving technology, and Kube Scheduler configuration is no exception. In this section, we will explore emerging trends and future directions in Kube Scheduler configuration, such as machine learning-based scheduling, multi-cloud and hybrid cloud scheduling, and integration with other Kubernetes components and tools. We will also discuss how these trends may impact Kubernetes cluster management and application deployment in the future, and how to stay up-to-date with the latest developments in the field.
Machine Learning-Based Scheduling
Machine learning-based scheduling is an emerging trend in Kube Scheduler configuration that uses machine learning algorithms to make scheduling decisions. By analyzing historical data on Pod scheduling and resource utilization, machine learning-based scheduling can optimize scheduling decisions based on predicted future behavior. This can help to improve cluster performance, reduce resource contention, and ensure seamless application deployment and scaling.
Multi-Cloud and Hybrid Cloud Scheduling
Multi-cloud and hybrid cloud scheduling is another emerging trend in Kube Scheduler configuration that enables Kubernetes clusters to span multiple cloud providers or a combination of on-premises and cloud-based resources. By configuring Kube Scheduler to manage resources across multiple clouds or hybrid environments, organizations can optimize resource utilization, reduce costs, and improve application availability and resilience.
Integration with Other Kubernetes Components and Tools
Integration with other Kubernetes components and tools is a key future direction in Kube Scheduler configuration. By integrating Kube Scheduler with other Kubernetes components such as the Container Runtime Interface (CRI) and the Container Network Interface (CNI), organizations can simplify cluster management, improve security, and ensure consistent performance across multiple clusters and environments.
Staying Up-to-Date with Kube Scheduler Configuration Developments
Staying up-to-date with the latest developments in Kube Scheduler configuration is essential for ensuring optimal cluster performance and seamless application deployment and scaling. To stay up-to-date, organizations can follow Kubernetes community blogs, participate in Kubernetes user groups and meetups, and contribute to Kubernetes open source projects. By staying engaged with the Kubernetes community, organizations can ensure that they are using the latest and most effective Kube Scheduler configuration strategies and tools.
Conclusion
Kube Scheduler configuration is a critical component of Kubernetes cluster management, and optimizing Kube Scheduler configuration is essential for ensuring optimal cluster performance and seamless application deployment and scaling. By understanding the key components of Kube Scheduler configuration, following best practices for configuring PredicateRules, PriorityRules, and BindingRules, and staying up-to-date with emerging trends and future directions in Kube Scheduler configuration, organizations can ensure that their Kubernetes clusters are optimized for business needs and application requirements.