
What is Cloud Spanner and How Does it Work?
Google Cloud Spanner is a globally distributed, horizontally scalable, relational database service that offers strong consistency and automatic scaling. It combines the benefits of traditional databases, such as SQL support and transactional consistency, with the advantages of NoSQL databases, such as horizontal scalability and high performance. Cloud Spanner is designed to handle large-scale, mission-critical workloads with minimal operational overhead, making it an ideal choice for enterprises that require high availability, low latency, and strict consistency.
Cloud Spanner is built on a distributed architecture that spans multiple regions and zones, allowing it to provide automatic failover, data replication, and backup. It uses a novel consensus algorithm called TrueTime that ensures strong consistency and low latency across the globe. Cloud Spanner also supports SQL-based tools and applications, such as JDBC and ODBC drivers, as well as popular programming languages, such as Java, Go, and Python.
Why Choose Cloud Spanner for Your Database Needs?
Cloud Spanner offers several benefits that make it an attractive choice for enterprises seeking a robust, scalable, and easy-to-use database service. Some of the key advantages of using Cloud Spanner include:
- Handling large-scale, mission-critical workloads: Cloud Spanner is designed to support high-volume, low-latency, and high-availability applications that require strong consistency and data integrity. It can handle millions of queries per second and terabytes of data with ease.
- Minimal operational overhead: Cloud Spanner automates many of the tasks that are typically required for managing databases, such as scaling, replication, backup, and failover. This allows developers to focus on building applications rather than managing infrastructure.
- Compatibility with SQL-based tools and applications: Cloud Spanner supports SQL syntax, schema, and data types, making it easy to integrate with existing tools and applications that use relational databases. It also provides JDBC and ODBC drivers, as well as APIs for popular programming languages, such as Java, Go, and Python.
- Automatic scaling: Cloud Spanner can automatically scale up or down based on the workload, without requiring any manual intervention. This ensures that the database can handle peak traffic and save costs during off-peak hours.
- Strong consistency: Cloud Spanner provides strong consistency across all replicas, ensuring that all nodes see the same data at the same time. This eliminates the need for complex synchronization mechanisms and ensures data accuracy and integrity.
- Ease of use: Cloud Spanner offers a simple and intuitive user interface, as well as command-line tools and APIs, for creating, configuring, and managing databases. It also provides detailed documentation, tutorials, and examples to help developers get started quickly.
In summary, Cloud Spanner offers a unique combination of scalability, availability, consistency, and ease of use, making it an ideal choice for enterprises that need a reliable and high-performance database service. By choosing Cloud Spanner, organizations can focus on building innovative applications and services, rather than worrying about the underlying database infrastructure.

How to Get Started with Cloud Spanner: A Step-by-Step Guide
Getting started with Cloud Spanner is easy and straightforward. Here’s a step-by-step guide to help you set up and configure a Cloud Spanner database:
- Create a Cloud Spanner instance: In the Google Cloud Console, go to the Cloud Spanner page and click “Create instance”. Choose a name, region, and instance configuration that suits your needs. Click “Create” to create the instance.
- Create a database: In the Cloud Spanner instances page, click on the instance name to go to the instance details page. Click “Create database” and choose a database ID, DDL statement, and other options. Click “Create” to create the database.
- Create a table: To create a table, you can use the Cloud Spanner SQL syntax. Here’s an example of a simple table definition:
CREATE TABLE Singers ( SingerId INT64 NOT NULL, FirstName STRING(1024), LastName STRING(1024), SingerInfo BYTES(MAX), ) PRIMARY KEY(SingerId); - Insert data: To insert data into the table, you can use the Cloud Spanner INSERT statement. Here’s an example of an INSERT statement:
INSERT INTO Singers (SingerId, FirstName, LastName, SingerInfo) VALUES (1, 'John', 'Lennon', 'SingerInfo1'); - Query data: To query data from the table, you can use the Cloud Spanner SELECT statement. Here’s an example of a SELECT statement:
SELECT * FROM Singers WHERE SingerId = 1; - Monitor resource usage: To monitor the resource usage of your Cloud Spanner instance, you can use the Cloud Monitoring dashboard. You can view metrics such as CPU utilization, memory usage, and network traffic.
By following these steps, you can quickly set up and configure a Cloud Spanner database, and start using it for your large-scale, mission-critical workloads. With its strong consistency, automatic scaling, and ease of use, Cloud Spanner is an ideal choice for enterprises that require a reliable and high-performance database service.
Best Practices for Designing and Operating Cloud Spanner Databases
Cloud Spanner is a powerful and flexible database service that can handle large-scale, mission-critical workloads with ease. However, to get the most out of Cloud Spanner, it’s important to follow best practices for designing and operating your databases. Here are some tips and guidelines to help you get started:
Partition your data
Partitioning your data is a key technique for optimizing performance and scalability in Cloud Spanner. By dividing your data into smaller, more manageable units called splits, you can reduce contention, improve throughput, and reduce latency. When partitioning your data, consider the following:
- Choose a good partition key: A good partition key is one that distributes the data evenly across the splits and minimizes contention. For example, if you have a table of user data, you might choose the user ID as the partition key.
- Avoid hotspots: A hotspot is a split that receives a disproportionate amount of traffic, causing contention and slowing down performance. To avoid hotspots, choose a partition key that distributes the traffic evenly, and consider using techniques like sharding or replication to further distribute the load.
- Monitor your splits: Monitoring your splits is important for detecting and resolving issues with partitioning. Use the Cloud Spanner dashboard to view metrics such as split size, split count, and split contention, and adjust your partitioning strategy as needed.
Optimize your query performance
Optimizing query performance is essential for ensuring a good user experience and reducing costs. Here are some tips for optimizing your queries in Cloud Spanner:
- Use indexes: Indexes can significantly improve query performance by allowing Cloud Spanner to quickly locate and retrieve the data. Consider adding indexes to columns that are frequently used in queries, such as primary keys or foreign keys.
- Limit the result set: Limiting the result set can improve query performance by reducing the amount of data that needs to be returned. Use the LIMIT clause to specify the maximum number of rows to return, and consider using OFFSET or FETCH to paginate the results.
- Avoid scans: Scans can be expensive and slow, especially for large tables. Use the EXPLAIN statement to analyze your queries and identify any scans, and consider rewriting the queries to avoid them.
Monitor resource usage
Monitoring resource usage is important for ensuring that your Cloud Spanner databases are running efficiently and cost-effectively. Use the Cloud Monitoring dashboard to view metrics such as CPU utilization, memory usage, and network traffic, and adjust your resource allocation as needed.
Plan for data backup and disaster recovery
Data backup and disaster recovery are critical for ensuring the availability and durability of your Cloud Spanner databases. Cloud Spanner provides built-in backup and restore functionality, as well as disaster recovery options such as regional replication and automatic failover. Make sure to plan for data backup and disaster recovery, and test your plans regularly to ensure they are effective.
By following these best practices, you can design and operate your Cloud Spanner databases with confidence, and take advantage of its unique features and benefits. With its strong consistency, automatic scaling, and ease of use, Cloud Spanner is an ideal choice for enterprises that require a reliable and high-performance database service.

Real-World Use Cases of Cloud Spanner: Success Stories and Case Studies
Cloud Spanner is a powerful and flexible database service that has been adopted by many companies and organizations for their large-scale, mission-critical workloads. Here are some success stories and case studies that showcase the benefits of using Cloud Spanner:
Pokemon GO
Pokemon GO is a popular mobile game that has millions of daily active users. The game relies on a complex and dynamic database that needs to handle a high volume of reads and writes, as well as geographic distribution and low latency. Pokemon GO uses Cloud Spanner as its primary database service, and has achieved significant improvements in performance, scalability, and reliability.
Snapchat
Snapchat is a social media platform that has over 200 million daily active users. The platform relies on a massive and distributed database that needs to handle a high volume of data, as well as real-time updates and low latency. Snapchat uses Cloud Spanner as its primary database service, and has achieved significant improvements in performance, scalability, and reliability.
Duolingo
Duolingo is a language learning platform that has over 300 million users worldwide. The platform relies on a complex and dynamic database that needs to handle a high volume of data, as well as real-time updates and low latency. Duolingo uses Cloud Spanner as its primary database service, and has achieved significant improvements in performance, scalability, and reliability.
These success stories and case studies demonstrate the power and flexibility of Cloud Spanner, and its ability to handle large-scale, mission-critical workloads with minimal operational overhead. By using Cloud Spanner, these companies and organizations have been able to focus on their core business, and leave the database management to the experts.
When implementing Cloud Spanner, it’s important to follow best practices for designing and operating your databases. This includes partitioning your data, optimizing query performance, monitoring resource usage, and planning for data backup and disaster recovery. By following these best practices, you can ensure that your Cloud Spanner databases are running efficiently and cost-effectively, and take advantage of its unique features and benefits.
If you’re looking for a reliable and high-performance database service for your large-scale, mission-critical workloads, consider using Cloud Spanner. With its strong consistency, automatic scaling, and ease of use, Cloud Spanner is an ideal choice for enterprises that require a robust and scalable database solution.
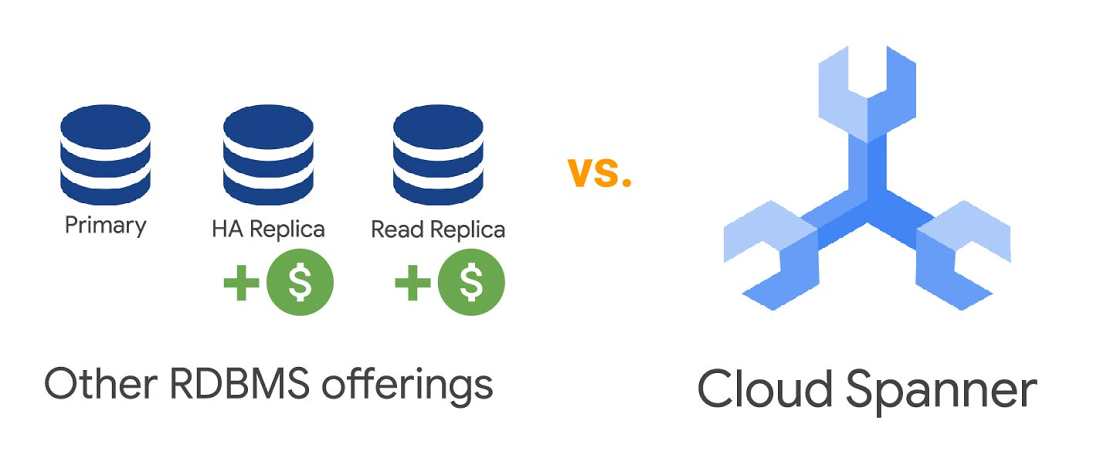
Comparing Cloud Spanner with Other Database Services: Pros and Cons
When it comes to choosing a database service, there are many options available, each with its own strengths and weaknesses. In this section, we will compare Cloud Spanner with other popular database services, such as Amazon RDS, Azure SQL Database, and MongoDB, and discuss the pros and cons of each service in terms of scalability, availability, cost, and functionality.
Cloud Spanner vs. Amazon RDS
Amazon RDS is a managed relational database service that supports several database engines, including MySQL, PostgreSQL, and Oracle. While Amazon RDS offers many benefits, such as ease of use, scalability, and reliability, it has some limitations compared to Cloud Spanner.
- Scalability: Amazon RDS has some limitations when it comes to horizontal scalability. While it supports vertical scaling, it may not be able to handle large-scale, distributed workloads as well as Cloud Spanner.
- Consistency: Amazon RDS uses a multi-region replication model that may result in eventual consistency, which can lead to data discrepancies and stale reads. Cloud Spanner, on the other hand, provides strong consistency across all regions, ensuring that all replicas are up-to-date and accurate.
- Cost: Amazon RDS can be more expensive than Cloud Spanner, especially for large-scale, distributed workloads. Cloud Spanner offers a more cost-effective solution for handling large-scale, mission-critical workloads.
Cloud Spanner vs. Azure SQL Database
Azure SQL Database is a fully managed relational database service that supports several database engines, including SQL Server, MySQL, and PostgreSQL. While Azure SQL Database offers many benefits, such as ease of use, scalability, and reliability, it has some limitations compared to Cloud Spanner.
- Scalability: Azure SQL Database has some limitations when it comes to horizontal scalability. While it supports vertical scaling, it may not be able to handle large-scale, distributed workloads as well as Cloud Spanner.
- Consistency: Azure SQL Database uses a multi-region replication model that may result in eventual consistency, which can lead to data discrepancies and stale reads. Cloud Spanner, on the other hand, provides strong consistency across all regions, ensuring that all replicas are up-to-date and accurate.
- Cost: Azure SQL Database can be more expensive than Cloud Spanner, especially for large-scale, distributed workloads. Cloud Spanner offers a more cost-effective solution for handling large-scale, mission-critical workloads.
Cloud Spanner vs. MongoDB
MongoDB is a popular NoSQL database service that supports document-oriented data models. While MongoDB offers many benefits, such as ease of use, scalability, and flexibility, it has some limitations compared to Cloud Spanner.
- Scalability: MongoDB has some limitations when it comes to horizontal scalability. While it supports sharding, it may not be able to handle large-scale, distributed workloads as well as Cloud Spanner.
- Consistency: MongoDB uses an eventual consistency model, which can lead to data discrepancies and stale reads. Cloud Spanner, on the other hand, provides strong consistency across all regions, ensuring that all replicas are up-to-date and accurate.
- Cost: MongoDB can be more expensive than Cloud Spanner, especially for large-scale, distributed workloads. Cloud Spanner offers a more cost-effective solution for handling large-scale, mission-critical workloads.
In conclusion, while there are many database services available, Cloud Spanner offers a unique set of features and benefits that make it an ideal choice for large-scale, mission-critical workloads. By providing strong consistency, automatic scaling, and ease of use, Cloud Spanner can help organizations reduce operational overhead, improve performance, and ensure data accuracy and reliability.
Future Trends and Developments in Cloud Spanner and Database Technology
Cloud Spanner has already revolutionized the way organizations manage their databases, but its potential for innovation and growth is far from over. In this section, we will speculate on the future of Cloud Spanner and database technology, and discuss the potential impact of emerging trends on database design, management, and usage.
Integration of Machine Learning and Artificial Intelligence
Machine learning and artificial intelligence are becoming increasingly important in the world of database technology. By integrating machine learning algorithms into Cloud Spanner, organizations can gain deeper insights into their data, automate complex processes, and improve decision-making. For example, machine learning algorithms can be used to predict future trends, identify anomalies, and optimize query performance.
Blockchain Technology
Blockchain technology is another emerging trend that has the potential to transform the way organizations manage their databases. By integrating blockchain technology into Cloud Spanner, organizations can create a decentralized and secure database that is resistant to tampering and fraud. This can be especially useful for industries that require high levels of security and transparency, such as finance, healthcare, and supply chain management.
Serverless Computing
Serverless computing is a new paradigm in cloud computing that allows organizations to build and deploy applications without worrying about infrastructure management. By integrating serverless computing into Cloud Spanner, organizations can reduce operational overhead, improve scalability, and reduce costs. This can be especially useful for organizations that have unpredictable or fluctuating workloads.
Hybrid Cloud and Multi-Cloud Strategies
Hybrid cloud and multi-cloud strategies are becoming increasingly popular in the world of database technology. By integrating hybrid cloud and multi-cloud strategies into Cloud Spanner, organizations can create a flexible and scalable database infrastructure that can adapt to changing business needs. This can be especially useful for organizations that have legacy systems or require specific compliance and security features.
Conclusion
Cloud Spanner is a powerful and innovative database service that has already transformed the way organizations manage their databases. By staying up-to-date with emerging trends and developments in database technology, organizations can continue to leverage the full potential of Cloud Spanner and stay ahead of the competition. Whether it’s integrating machine learning algorithms, blockchain technology, serverless computing, or hybrid cloud and multi-cloud strategies, the future of Cloud Spanner is bright and full of potential.

Conclusion: Embracing Cloud Spanner for Your Database Needs
Throughout this comprehensive guide, we have explored the unique features and benefits of Google Cloud Spanner, a globally distributed, horizontally scalable, relational database service. We have discussed the advantages of using Cloud Spanner, including its strong consistency, automatic scaling, and ease of use. We have also provided a step-by-step tutorial on how to set up and configure a Cloud Spanner database, as well as best practices for designing and managing Cloud Spanner databases.
Real-world use cases of Cloud Spanner have shown that it can handle large-scale, mission-critical workloads with minimal operational overhead, and is compatible with existing SQL-based tools and applications. Comparisons with other popular database services have highlighted the strengths and weaknesses of each service in terms of scalability, availability, cost, and functionality.
As we look to the future of Cloud Spanner and database technology, we can expect to see the integration of machine learning, artificial intelligence, and blockchain. These trends have the potential to transform database design, management, and usage, and Cloud Spanner is well-positioned to take advantage of these developments.
In conclusion, if you are looking for a robust, scalable, and reliable database solution, we encourage you to consider using Cloud Spanner. With its unique features and benefits, it can help you manage your mission-critical workloads with ease and confidence. Sign up for a free trial or contact a Google Cloud representative today to learn more about how Cloud Spanner can meet your database needs.
